I’m new to KNIME and have been using the tool to expand my analytics capabilities primarily regarding employee data.
I’ve created several KNIME workflows based on data and insights mentioned in books and articles to familiarize myself with the tool.
I tried creating a Decision Tree to predict employee churn, where the independent variables would predict whether the employee would be Active (A) or Terminated (T) at the end of the year.
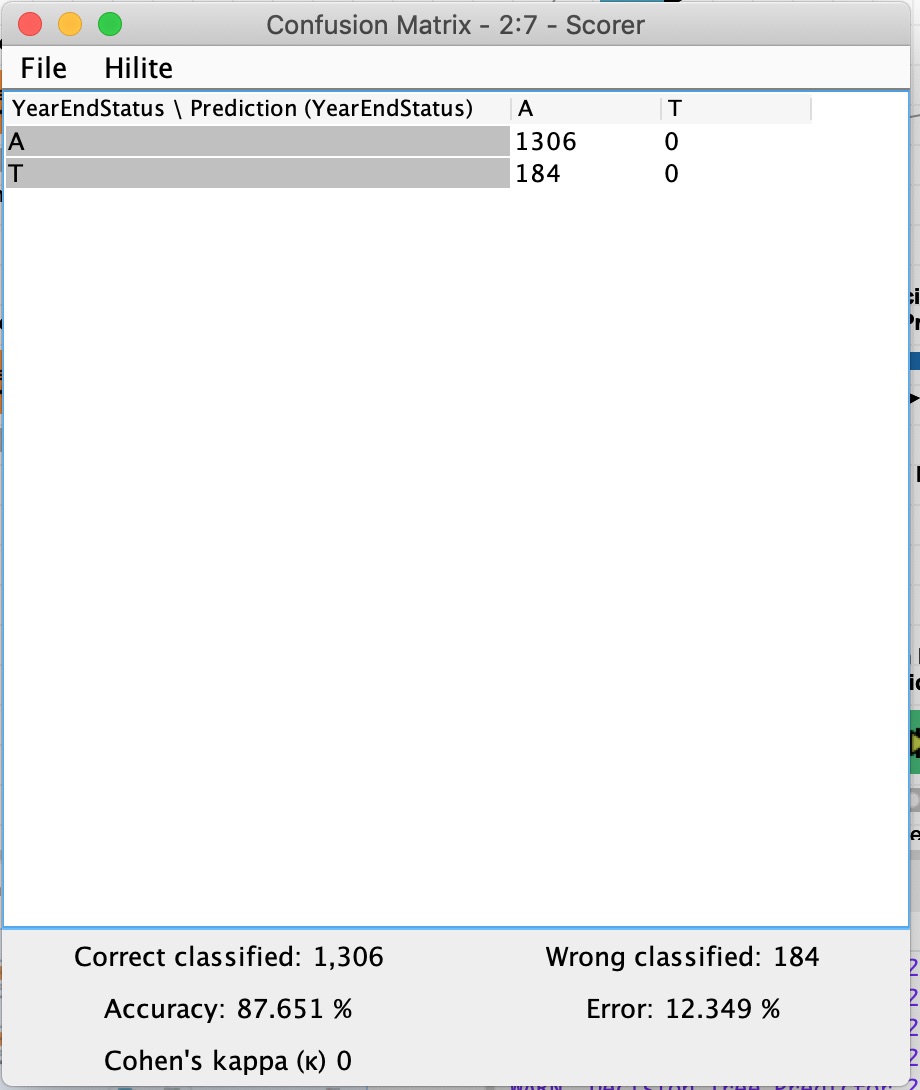
After I partition the dataset into 80% train and 20% test sets and run the workflow, the confusion matrix only shows it predicting Active records:
It looks like you just use the % prediction and then the scorer sets a result and since the majority would remain the moment a leaf reaches 50+% remain it counts as A (Active).
It might be that your Decision Tree does not find small enough groups where T (Terminate) is the majority. You could still derive a score from the tree and rank the people which are most likely to go.
So the person most likely to leave might have a score of 0.42 or something - by the 0.5+ rule he would be classified as A but it might still be possible to find a cutoff to decide who is of a higher risk of leaving.
You would have to set the cutoff point yourself instead of using the 50%+ rule.
This example also allows you to extract rules from your tree so you can see what is driving its decision:
One other way to measure the quality of such a model is Gini/AUC - we had a discussion about that here. Also you might want to try other models as well.
Then you might have to adapt your business strategy if you cannot get better data or find a better model. You might not be able to make immediate decision but make intermediate ones. Like putting people on a watchlist or assigning some money to hire new people based on a probability some of them will leave.
Also you might want to be careful with the Accuracy claim. As we have discussed on several occasions. This is a good example why ‘Accuracy’ is not always helpful. 87% would sound impressive for some AI buzz but as everyone can easily see here in this case the number is pretty useless in itself.
Appreciate the info, and the links. Can you direct me to where I would set the cutoff point in the Decision Tree node myself so that it uses something other than the default 50%+ rule? I didn’t see anything in the node parameters that would affect that.
Note that since the business issue I’m trying to address is employee churn, false positives are OK. Even though those employees are falsely predicted to Terminate when they remained Active, going forward those are still the kinds of employees that the business could engage to help ensure they don’t leave in the future (that is, cast a wider rather than more narrow net). But the model still has to predict that some people Terminate so that the business can apply those Decision Tree rules on the independent variables. LOL
Thanks for taking the time to respond. Appreciate any additional insights you can provide.
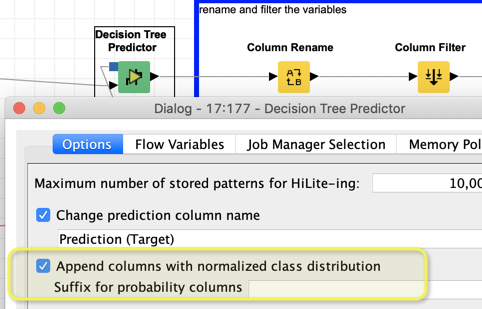
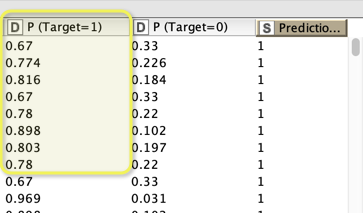
In the decision Tree predictor (and most other model predictors) you can tell the system to give out the thing we like to call prediction score. It is the % of Target = 1 in the specific leaf of your tree in the training data in this specific row (but the roe is taken from the test data and the score is calculated following the rules set in training). In a simple case it can be interpreted as some sort of probability but you have to be somewhat careful with that - in the end it is just a rank you can use.
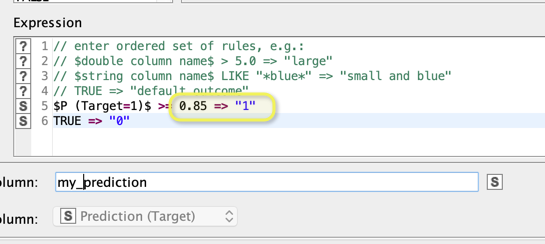
What you can now do is use a Rule Engine node and set your own cutoff and create “my_prediction”. There are ways to automatically calculate the optimal cutoff but I think it best to check wahr your business needs are.
With your new cutoff you can see what the proportion of people terminating and staying active would be - you see their proportion when using your brand new variable my_prediction = “1”.
Then you will have to make a decision if you can live with the number of (potential) misclassifications or if you cannot you might
build a better model with a Random Forest or XGBoost (I would recommend using a few more models to see where it gets you)
get better data / more information
check if you whole setup is correct
And please note all this depends heavily on (at least) several things:
your whole setup correctly reflects the question you want an answer to (the sample truly represents your staff)
the setup, situation, data … will be basically the same next time you run your model (no massive layoffs planned, no competitor next door offering double the money to your employees)
you can safely identify your target (that should be OK in this case but sometimes can be tricky in more complex cases)
If you have changes in the environment eg you hire hundreds of new people with very different contracts you model might not reflect that and you might have to limit it to the people already on board.
And as I have mentioned earlier in this thread I recommend checking the rules and variables driving you model and see if they make any sense - maybe checking that with some HR people or business experts.
This is very helpful as far as understanding for the P(target = 1) influences the overall call by the model. You mention that this can be optimized for a given model. Can you lead us to this type of a workflow? We are running into an issue with a unbalanced training set and need to optimize the model (perhaps for its concordance).
Question is what you mean by optimized for a given model. If you want to finde the best cutoff point, I have built a MetaNode that would evaluate a given model (solution - the truth: 1/0 and submission (score 0-1) and recommend a best cut-off point using two statistics:
Also, H2O.ai Automl would come back with a best cutoff based on F1 score. But please keep in mind: in the end, you will have to make a business decision what score represents a correct hit.