Hi @8bastian8 ,
Thank you for uploading your sample workflow. It always makes it much easier to assist when we can see what has been attempted so far.
You were on the right lines. The “simple”  way to check if it ends in a digit is to use the regexMatcher function rather than lastIndexOfChar. Unfortunately lastIndexOfChar doesn’t work with regex patterns and so you can only use it for specific characters rather than character ranges. Alternatively, you could have used the indexOfChars and inspected to see if the last character were present in a string.
way to check if it ends in a digit is to use the regexMatcher function rather than lastIndexOfChar. Unfortunately lastIndexOfChar doesn’t work with regex patterns and so you can only use it for specific characters rather than character ranges. Alternatively, you could have used the indexOfChars and inspected to see if the last character were present in a string.
As your original question was looking to see if the last character was a digit, I modified your code also to see if the last character was a digit, rather than a letter which means I have effectively reversed your logic (and so you will see that the operations responding to true and false are the other way round to the way you had them)
Borrowing from @aworker’s idea, on using reverse, which as he demonstrated makes it easy to retrieve the last character, we could test this for example:
if(indexOfChars(substr(reverse(strip(column("publication_number"))),0,1), "0123456789") > -1)
My preference here though would be regexMatcher as the resultant code is less complex:
if(regexMatcher(strip(column("publication_number")), ".*[0-9]"))
{
substr(strip(column("publication_number")),length(strip(column("publication_number")))-2)
}
else
{
substr(strip(column("publication_number")),length(strip(column("publication_number")))-1)
}
The regexMatcher in the Column Expression node returns a boolean true or false and so can be happily used as the condition.
In the attached workflow, I also added a further column expression in the same node to perform the “removal” from the original string.
Another way to achieve this, is to use my “favourite” relatively undocumented feature of String Manipulation, which is the “ternary operator”. This allows for some conditions to be included in the script.
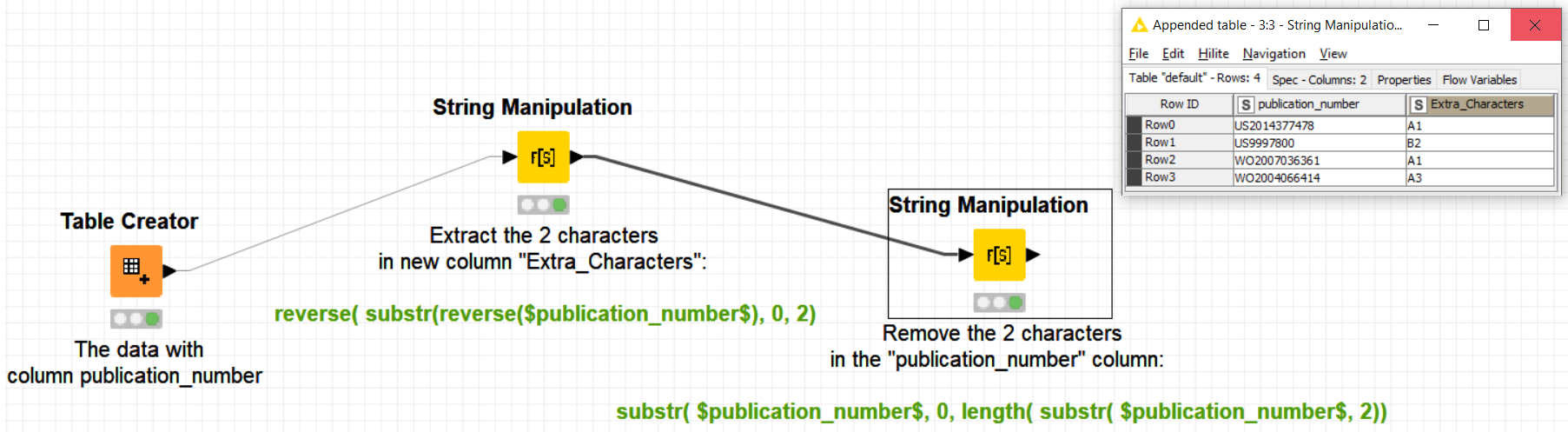
To get the last two characters, from the “stripped” string, only if the final non-space character is a digit, you can use the following script:
regexMatcher(strip($publication_number$),".*[0-9]").equals("True")
?substr(strip($publication_number$),length(strip($publication_number$))-2)
:substr(strip($publication_number$),length(strip($publication_number$))-1)
and to return the body of the string with the final two characters removed, under the same conditions, use this:
regexMatcher(strip($publication_number$),".*[0-9]").equals("True")
?substr(strip($publication_number$),0,length(strip($publication_number$))-2)
:substr(strip($publication_number$),0,length(strip($publication_number$))-1)
Note that I also wrapped the “strip” function around all references to the column, so that the resultant data is stripped of spaces. This would have the effect of stripping spaces from the front of the column too. If you only want to strip spaces from the end, then replace this with the stripEnd function.
What both of these do is check that the string matches the regex pattern “ends in a digit”. If the “regexMatcher” function returns the string "True", the result of the operation performed after the ? is returned.
Otherwise, the operation after the : is performed and the result returned
Note also that regexMatcher functions differs in the String Manipulation node as it returns a String "True" or "False" rather than a boolean, so the way of checking the result of the function differs from the way it appears in the Column Expression node.
I have attached a workflow demonstrating all of the above methods.
Delete last two characters_last character of string in column v2.knwf (12.7 KB)