I have a table ( lets name it Main Tbl) with rows of random sentence with name of specific car brands in each sentence! ( for instance : row 1 : Benz is a German car with 3000 cc engine , row 2 : best kia motors have four cylinders, row 3: black Toyota is most profitable cars and so on !)
What I want is to extract name of cars from each sentence.
However, I also could create a reference table with name of all the car`s brand on it!
So, I want to write a workflow which goes row by row in Main Tbl base on rows in reference table and extract the exact name of car from Main Tbl base on reference table!
It would be like this :
Main Tbl
Benz is a German car with 3000 cc engine
best kia motors have four cylinders
black Toyota is most profitable cars
.
.
.
.
.
.
reference table :
Ref Tbl
Kia
BMW
Benz
Toyota
.
.
.
.
.
Desire table
Benz is German car with 3000 cc engine -------------- Benz
best kia motors have four cylinders---------------------- kia
black Toyota is most profitable cars -------------------- Toyota
I wish I could make my problem clear for everyone,
regards
Let us know if further clarifications are needed.
BR
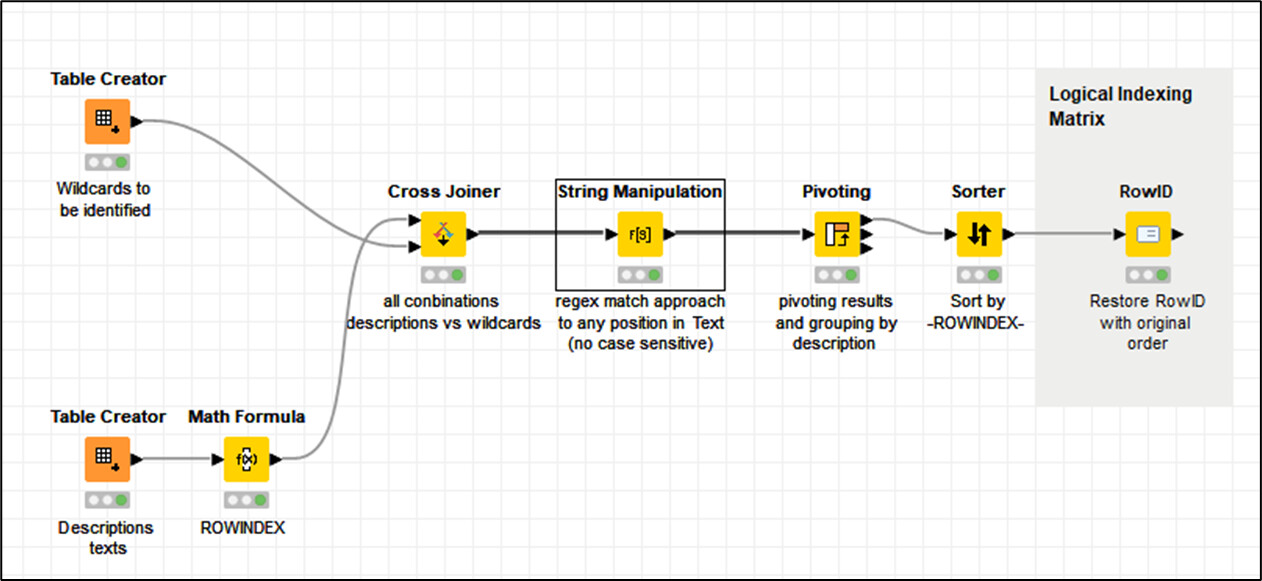
PS.- The logical indexing matrix can be easily unpivoted and filtered to get your desired output (being aware of a unique TRUE by row, aiming to avoid duplicates)
first and foremost, many thanks for you guidance , it does really help me through my problem.
nevertheless, when I modified my workflow base on your guidance , I have faced a new issue!
As I mention above I create a list contains words which I need to be extract from my original text .
My workflow was working smoothly (thanks to your help!) but the problem is my main table is not that cleaned and some of the words are attach to each other!
Let me clarify the issue , in my workflow I use “string(”\b(“+$Stopwords$+”)\b")" in String Manipulation node then attach this node to " Table row variable run for time loop start " and then attach the outcome variable to “Regex Extractor” as variable and my original texts as an input!
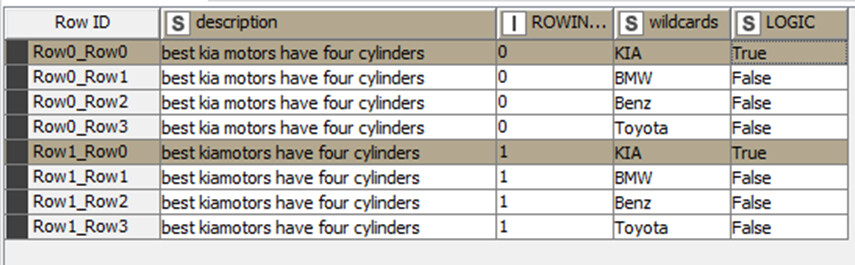
When my original text is like " best kia motors have four cylinders" and my “stopword” is “kia” everything is working , but when my original text is like " best kiamotors have four cylinders" it doesn’t work , probably because it cannot recognize word kia in kiamotors!
So, I suppose I need a regex to recognize “sequence of specific character in text” like k+i+a in kiamotors !
Hi @badger101 ,
it isn’t very large file ( my main table has only 8 thousand rows) but the problem is, the data are in Persian language so it is a bit hard to work with for somebody isn’t familiar with the language.
I’ve modified the workflow to test the bug that you’ve experienced, and I can’t replicate the issue. Using the unmodified ‘regexMatcher’ expression from the original workflow, it performs ok
I think you have to be more specific on identifying the root of the problem. I mean if it can be related to: special characters in the sentence, line breaks or returns…
Dear @gonhaddock ,
I tested your workflow with my original dataset and it seems it is working properly ( many thanks indeed!)
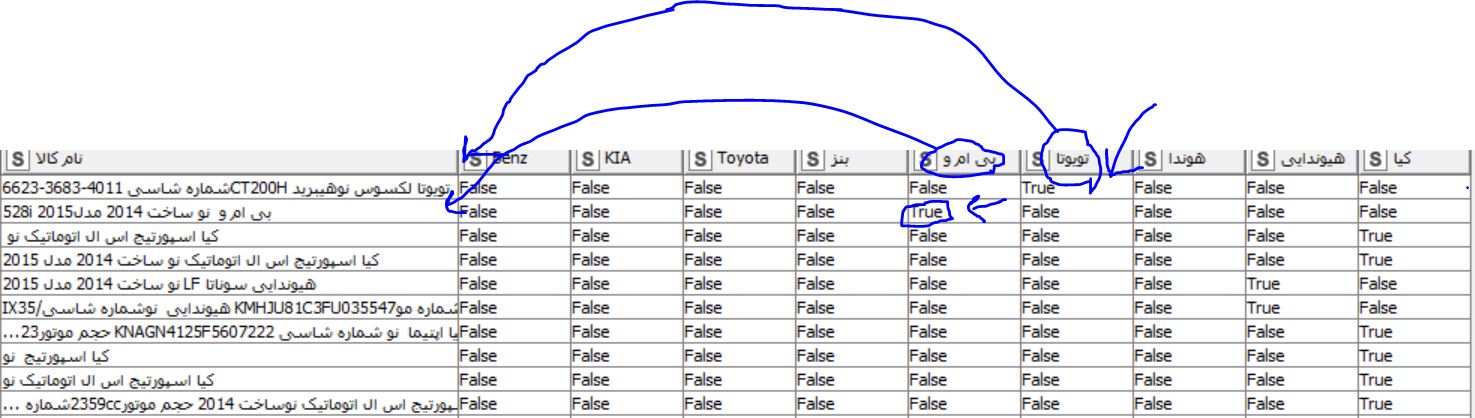
However, I now need to find a way to write a wildcards in front of description after pivoting!
my pivoting out put is like this :
Hello @psfard
The Logical Indexing Matrix workflow is a very ‘formal’ way to work in data mining, as allows all type of checking results (There are some other methods like Group By…) Expected issues are: if a single sentence returns validation for 2 wildcards i.e. ‘Benz is a more premium product than KIA’; or a false TRUE with a word in a sentence that unintentionally contains a brand (i.e. benzene). Then take some actions.
It allows you to perform some type of relational analysis as well if the case.
Unpivoting at the end will return you to the String Manipulation table status, the Column Headers will be distributed in a column named $ColumnNames$.
But if you want to keep it simple and you are confident with the result; then you can end the workflow in this 5th node (String Manipulation) and just add a ‘Row Filter’ node for LOGIC == TRUE .
Dear @gonhaddock ,
as a matter of fact , I have faced the same two problems ( false True and 2 wildcards in same sentence) . However, your advice about Unpivoting and then Groupby on row index with concatenate aggregation on ColumnNames has solved must of my problems. So thank you very much for walking me through this.