I have a file with about 2M rows and several columns. 1 column contains the description of items:
e.g. “T-shirt made from recycled cotton”, or “laptop computer year 2019” or “salad bowl made from glass and iron”.
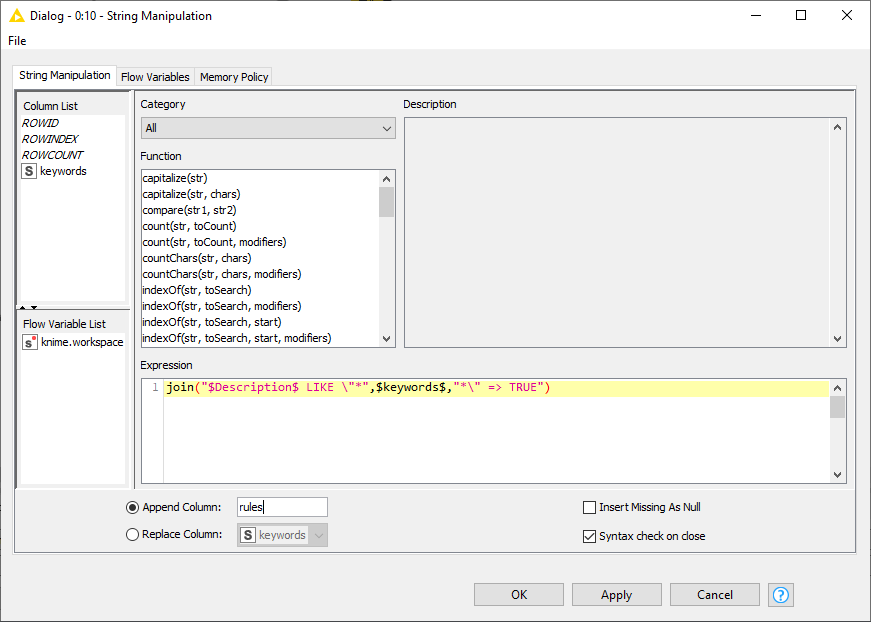
I want to keep only rows that are of interest to me, so I created a list of “words to remove” and I want to remove all rows that contain 1 or more of these words. The item descriptions are very long and can differ slightly so I used “table creator” nodes where each row contains word(s) including wildcards. For example “cotton” is on the list, so I want to remove rows that contain “cotton” in the description.
Reference row filter did not work: it seems it does not work well with wildcards (0 records were removed). In the reference table I have “cotton”, but description are like " 20 white cotton t-shirts" so it does not work.
Individual Row filter nodes would work but my list contains about 55 words to remove to it’s quite tedious to do it that way (would need 55 nodes).
Rule based row filter would also work but I would have to write 55 statements such as $Description$ LIKE “Cotton” or $Description$ LIKE “papaya” ETC 55 times as well so it becomes impossible to read and making changes would lead to errors probably.
Loop: using a table creator (for my list) & row filter node (select the option “exclude the rows by attribute values”) and loop through each item of my list. However this seems to have de-multiplied the data and the results are not correct.
Loop and row filter value: this time “include” the rows by attribute value, and then join the main data set with the “intermediary results” and do an anti-join. This works but is not ideal.
Any recommendations on how to proceed?
thanks!
pls
Hi @PLS_KN , if your dataset doesn’t contain sensitive info, share it here so I can work out a workflow for you. If it does contain sensitive info, either remove the sensitive columns or do some modification.
Hi @badger101
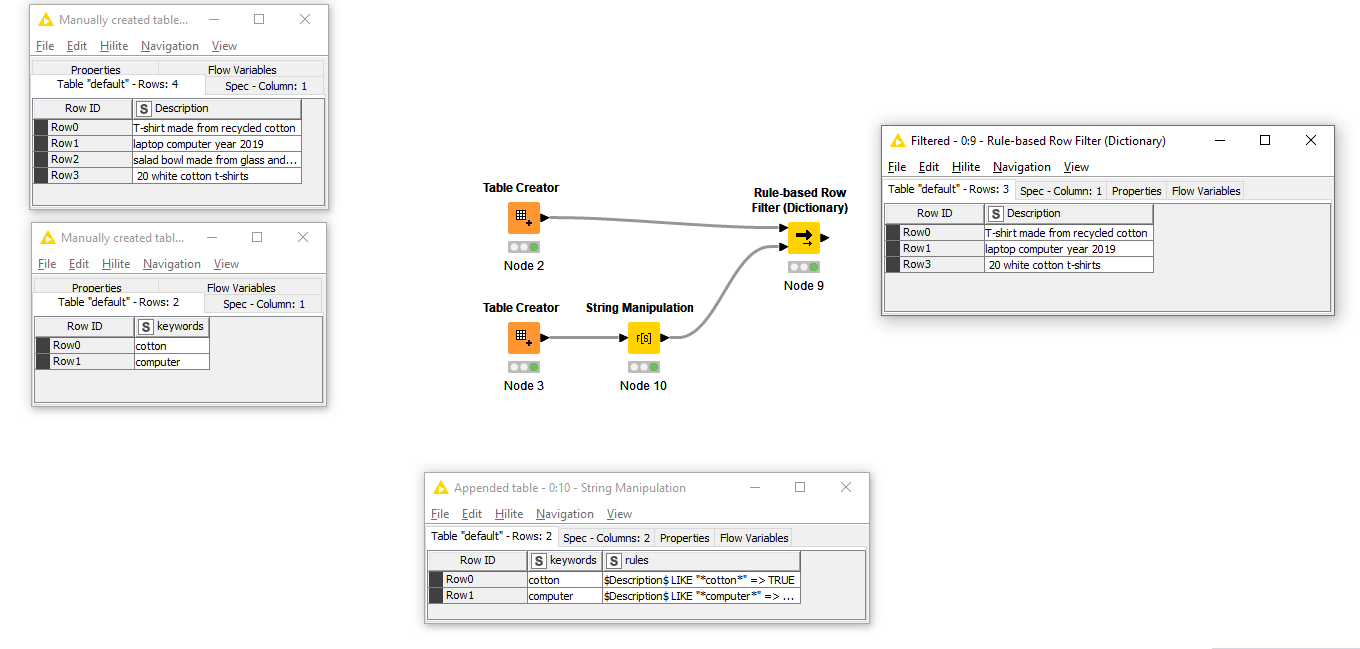
unfortunately I work with sensible data so I’ve create two dummy tables. Let me know if you think of anything! here’s the workflow KNIME_project.knwf (27.4 KB)
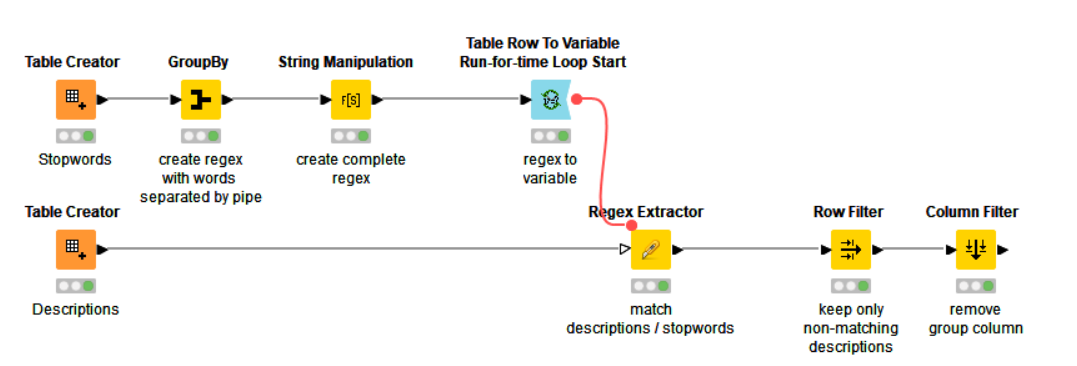
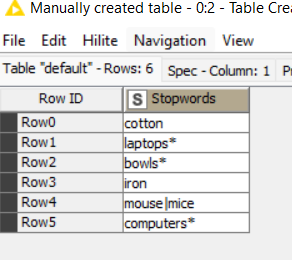
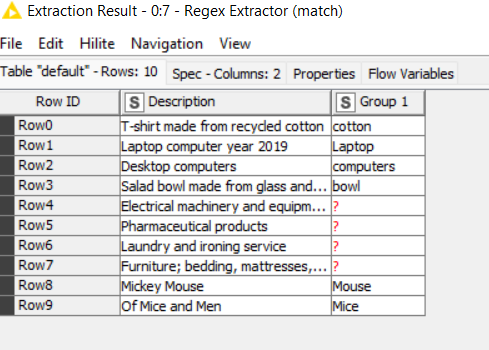
The Stopwords node contains the “words to remove”. They are “packed” into a single regular expression, so the matching happens only once per Description. The words, in fact, are “patterns” belonging to a regex and they are meant to match exactly, so if you want to include both singulars and plurals you must use e.g. computers*. For the same reason “iron” won’t match “ironing”, unless you use iron(ing)*.
The complete regex, once calculated by the String Manipulation node, is passed as a variable to the Regex Extractor, which creates a column with matched words (if any) or missing values
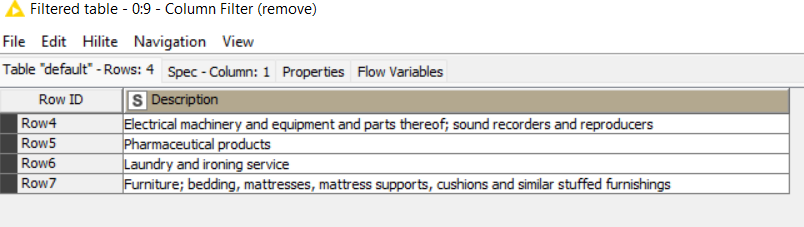
The last step is to filter out the “matching” rows and the Group column
Result
Hello @PLS_KN
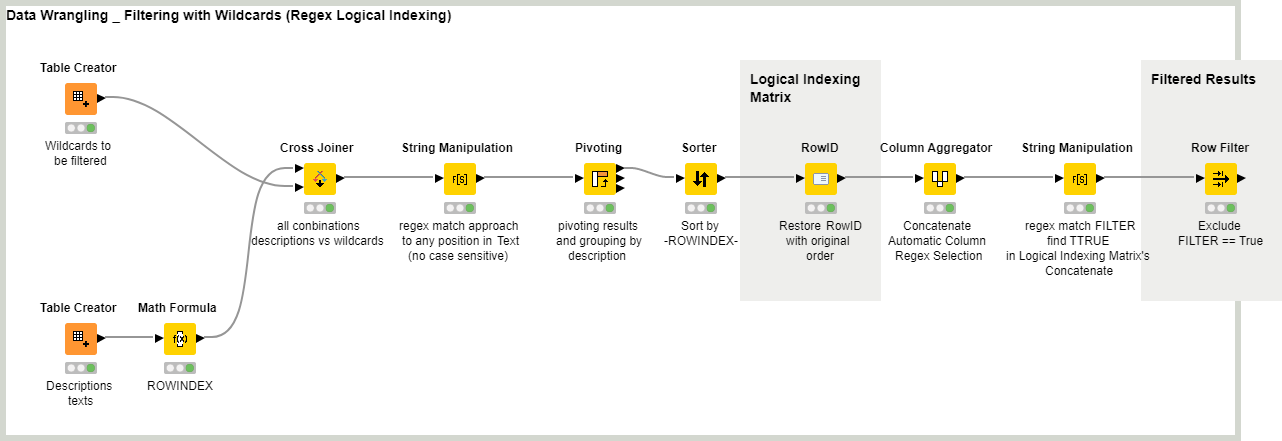
I couldn’t avoid to give this a try. It is based in a Logical Indexing methodology. It doesn’t use the Regex Extractor component (I cannot download it from my network today).
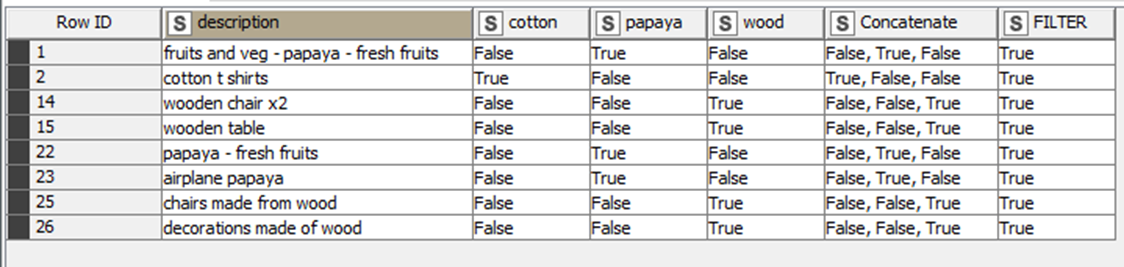
With the mentioned logical indexing matrix you can give this workflow some other LOGICAL uses like: when does a word happens when some other is present before…
This is an example of the excluded words in your final filter: