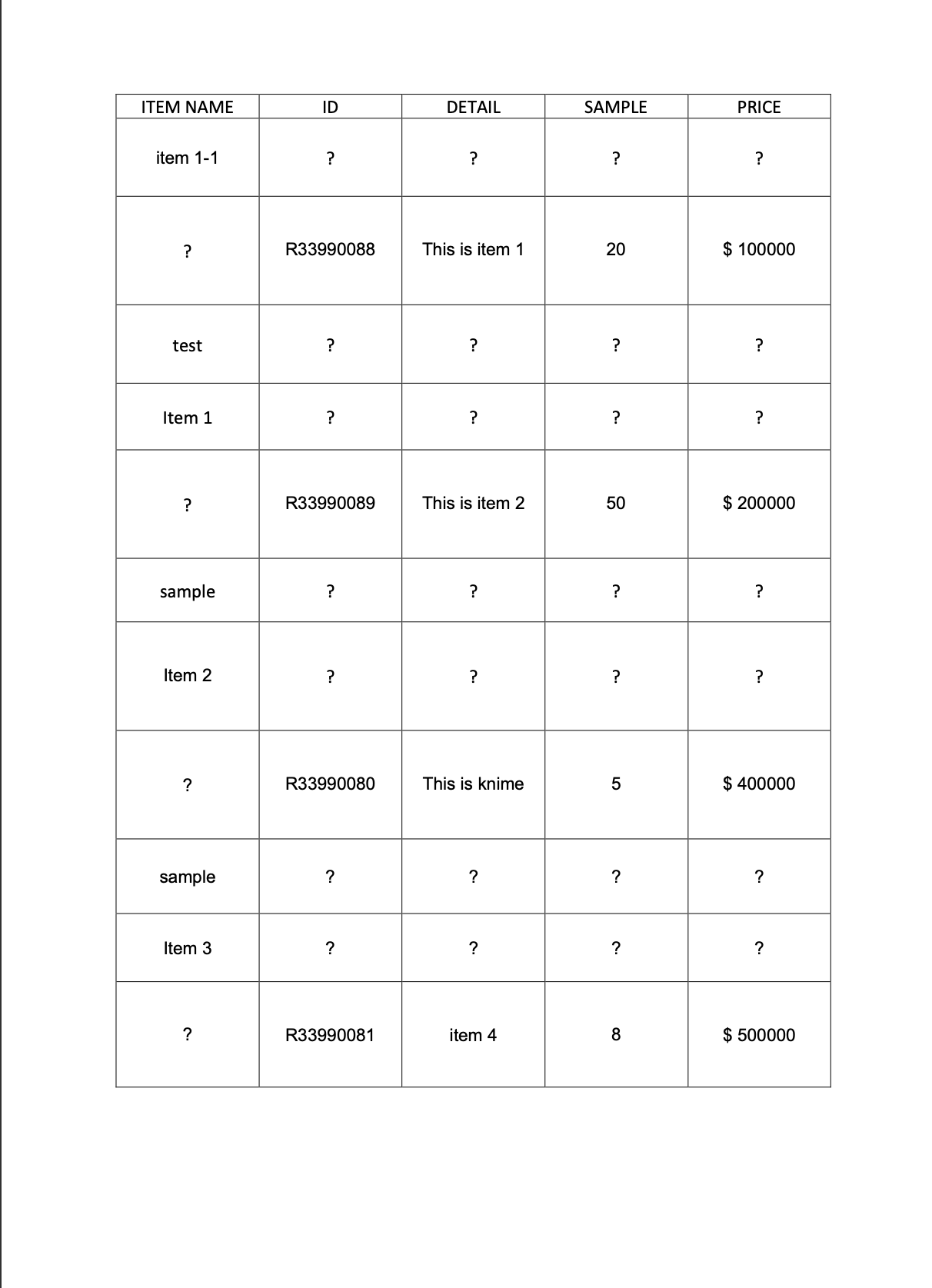
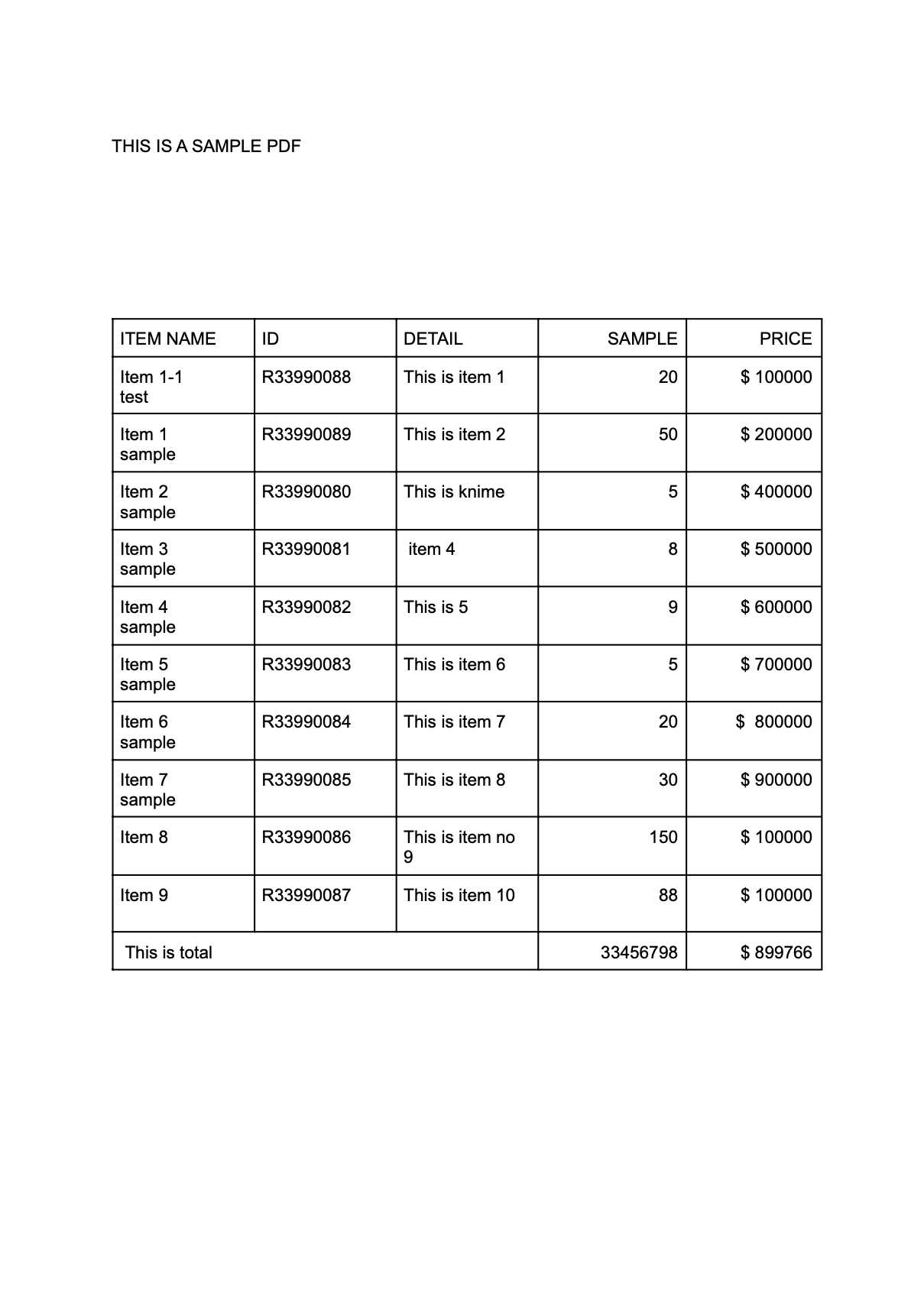
I used a Python source node to extract tables from a pdf using some Python packages, i.e., Tabula and Pandas.
I am facing a problem when extracting the tables because it is giving an unstructured output from the Python source node. I am not able to extract the exact table from the pdf.
The code i used in the Python source node is as follows:
from tabula import read_pdf
import pandas as pd #reads the table from pdf file
read_pdf = read_pdf(“examples.pdf”,pages=“all”) #address of pdf file
output_ table=pd.DataFrame(read_pdf[0])
The text which is wrapped in the next line of the cell is coming as new line in the knime output of python source node
Please find the example input pdf and the knime