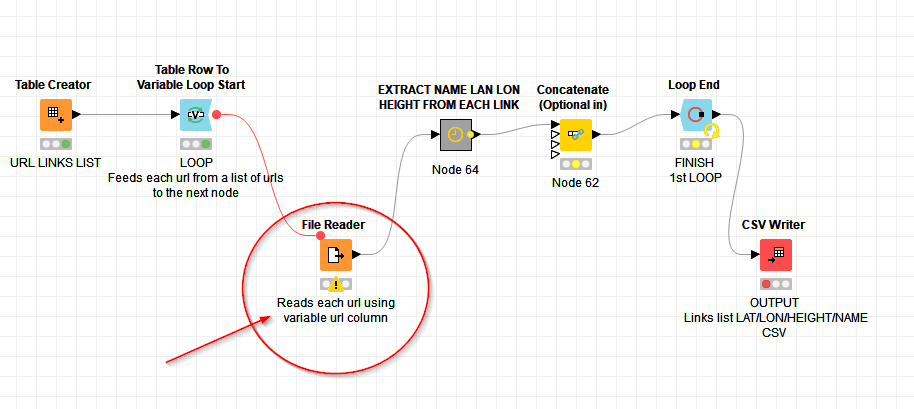
For the record, I would like to continue updating the previous question with some new information in regards to the freezing of the “File Reader” node (link below)
I noticed that there is an increase in memory (>50,000MB not KB, that is 50GB), and I used the “Run Garbage Collector” node at each iteration inside the loop. I recall the workflow here: LINKS_download.knwf (275.7 KB)
and here:
It turns out that Garbage Collector “disposes” the memory and smoothes the workflow with no issues, though File Reader still takes some longer-cycles to read but it does read eventually (I guess due to some outside reasons, not responding server, timeouts, etc).
An update for this issue about slow workflow process:
I also found that after 5,000 - 6,000 iterations in which urls are read and a csv table is saved, the workflow slows down from 14 csv files (output) to 3 csv files per minute. The workflow successfully finishes but it takes more time. Garbage collector does not help at this point to make workflow efficient, and restart of knime is required. After restart of knime, the 14 csv files per minute continues and knime is doing “fast workflow” for another 5,000-6,000 links.
Thanks for bringing this up. You wrote that while running the workflow, KNIME AP would, at some point, use about 50 GB of heap space. May I ask how much memory you have allocated to KNIME Analytics Platform? Also, have you made any modifications to the knime.ini file?
You also wrote that after 5000-6000 iterations, the workflow slows down from 14 files per minute to 3 files per minute. Is this a sudden change or is it more gradual? In other words, would the workflow slow down to 5-10 files per minute after 2000-4000 iterations? Also, if you do invoke a garbage collection in each iteration, does the allocated heap space still grow in between iterations? If so, by how much?
Finally, can you confirm that, after 5000-6000, the majority of time is still spent at the File Reader node or are other nodes catching up in terms of time spent?
About memory and knime.ini:
I have attached the knime.ini below. I have dedicated appox. 53GB RAM. I can do more, but it doesn’t do much of difference.
About workflow speed:
Yes, there is a gradual slow down of workflow speed. It does slow down to 5-10 files after 2000-4000 iterations.
Garbage collection facilitates significantly.
Time spent
Sometimes File Reader node and sometimes Loop End.
In addition, I have made another workflow with more demanding requests such as downloading large tables from urls and store them to CSV files individually. I finally found that integrating R instead of using File reader or CSV reader takes very short time.
I have a comparison below between Knime, Knime/R (hybrid), and R:
Knime
With Knime nodes (Not R), my workflow to download 18,000 links/tables required approximately 4-5 days with no interuptions.
Knime/R hybrid (R snippet)
With R script in Knime, it took me approximately 1 day, that is more than 3,000 minutes.
R Studio
With R script and no knime involved at all, I spent 34 minutes to download approximately 18,000 tables.
Mlauber71,
R was looping with knime loop nodes.
How do you simply download the tables and save them as files? This was my intention. Any suggestion other than CSV reader or file reader nodes reading urls and saving them as CSV files inside in a knime loop?
You could use the Download node like in these examples. You could also construct it that you could restart the process without having to load files again that have already been loaded.
Another possibility would be to have the loop inside the R node so there would be no need for communication between KNIME and R that also might use up resources.
I noticed you have the line -Dorg.knime.container.cellsinmemory=10000000 in your knime.ini. This is much larger than the default of 1,000 and entails that KNIME AP holds tables with up to 10 million cells in memory no-matter-what until memory becomes critical. Before this critical memory condition is met, the garbage collector will take up more and more of your CPU cycles, which could explain the slow-down. Note that, for instance, a String cell can easily require 100 byte or more memory. Therefore, holding multiple tables with 10 million cells in memory can quickly fill up your 53 GB of main memory. I suggest to take this line out of your knime.ini and leave the caching of tables in memory to KNIME AP. The -Dorg.knime.container.cellsinmemory option is mostly a remnant from earlier days, when KNIME AP did not have an elaborate table caching mechanism.
Also, I was wondering:
Which version of KNIME are you using? KNIME 4.0 is more aggressive in using heap space than KNIME 4.1, so I suggest an upgrade if you are still on 4.0.
If you set your console / log level to DEBUG in your KNIME preferences, do you observe memory alerts in your console or knime.log? If so, what exactly is being reported?
If you configure the memory policy of nodes in your loop to “Write tables to disc”, does the heap still fill up and the workflow still slow down?