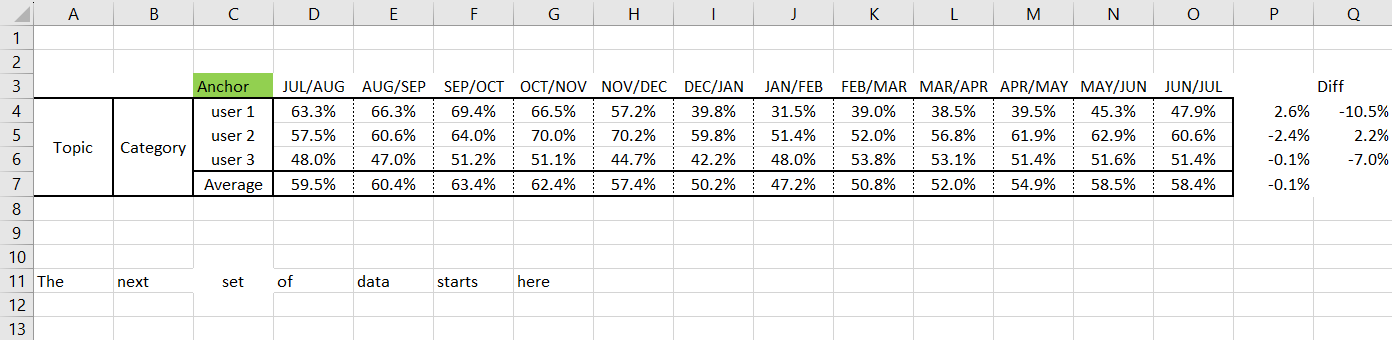
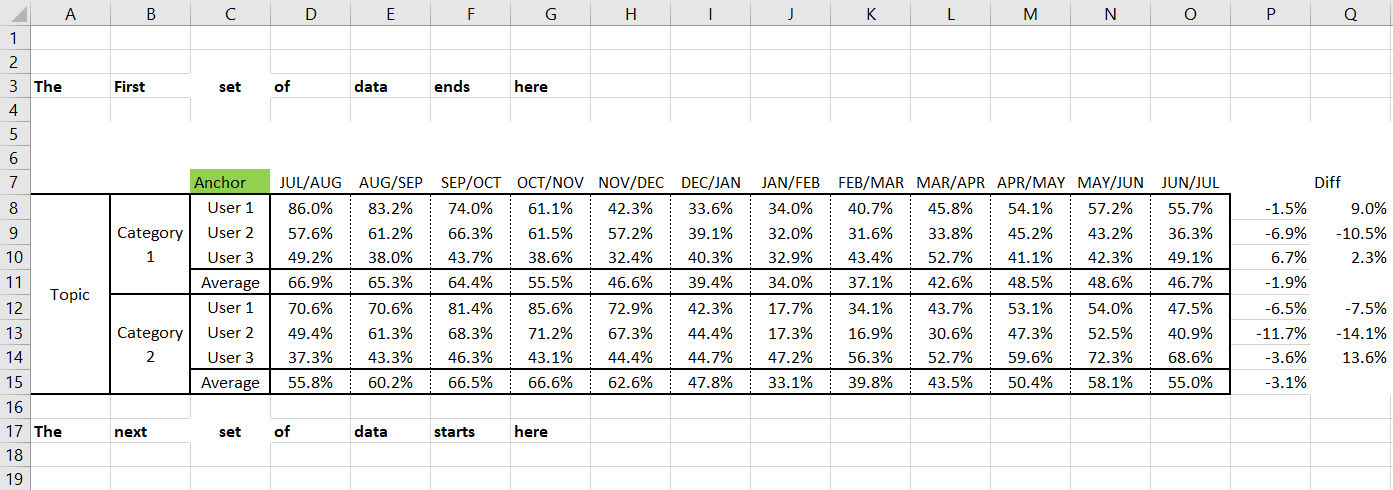
I have an excel workbook with multiple sheets. There is a table in each of the sheets that has the same starting (anchor) point but the starting row and also the number of rows in each table can be different per sheet. Example of sheets below and test data in attachment.
Is there a way to find the anchor point (the word Anchor highlighted in green) and then dynamically read the number of rows the table? I need to read the full table area (i.e. from col.A to col.Q.
I could hardcode the number of rows each table will have but i’m conscious that the number rows on each sheet each month could change.
Hello @taylorpeter55,
If one can assume that the area is delimited by Anchor and Average and that there is only one area of interest in a sheet, this workflow can work
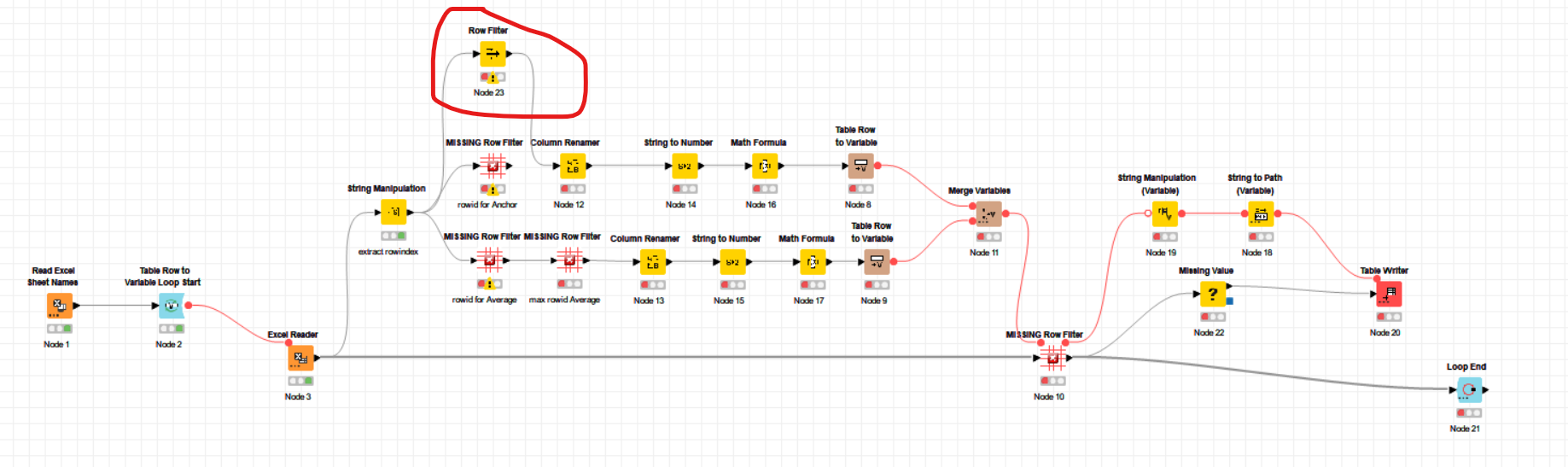
Unfortunately the version of the row filter node that you are using is only available in version 5.3 and above and my company is not using this version yet (and i’m unable to upgrade).
Are you able to replace these with the deprecated version of the row filter? If not, please can you tell me the configuration of the 4 MISSING Row Filter nodes that you used in the screenshot below please?
I’m hoping that I can replace the missing row filters with the row filter node that I have available (as circled).
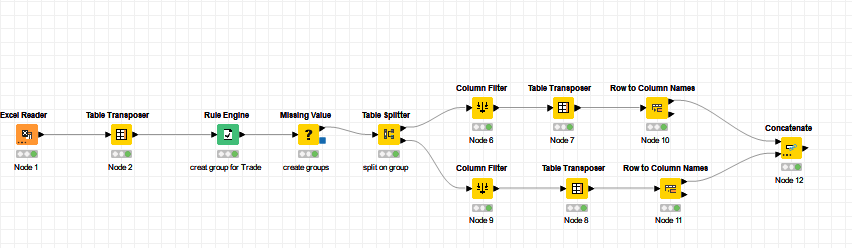
Here is a version with the old Row Filter. I add a more general treatment in case of more than one block of data in a sheet (see sheet topic 3 in the Excel file in the data folder for the workflow).
To have a valid workflow, I make it doing something : here writing a table (in the data folder too) for each blocks and sheets. Of course this has to be adpated especialy if all the blocks have the same specifications.
Note that I use some Missing value node to propagate the fusionned cell in Excel.
You’re welcome !
There is a Math Formula node in the workflow and it’s doing nothing (+0) : Ieft it because it is necessary to adjust row index and row number. There are the same with the old Row filter but are differing by one with the new node.
You may also be interested in the Table Splitter node, introduced with KNIME 5.x which may be useful for part of this requirement, as it allows you to split a table at a row defined by a value in a column.
Hi @JPollet . You’re welcome! Unfortunately I don’t think that’s an option… maybe one for feedback/ideas as it would certainly make sense to allow regex/wildcards
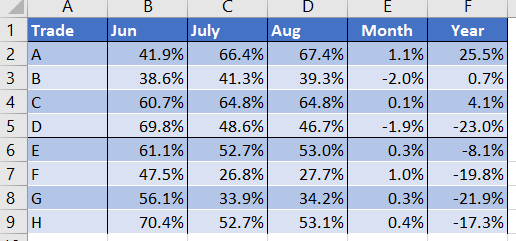
At this moment i’ve hardcoded the columns (i.e. Col1 to6, Col7 to 13 but i was wondering if there is a way of finding the word Trade (as starting column of each table) to split them and then concat back together?