I am trying to calculate the fastest and cheapest shipping option for incoming orders.
Most items in an order can either be shipped from the manufacturer´s warehouse directly (drop-shipping) to the customer or via our own warehouse.
Some manufacturers do not offer drop-shipping, therefore the only option is to ship these items via our own warehouse. Other items again, are too expensive to ship first to our warehouse and then again to the customer, so they should always be shipped from the manufacturer´s warehouse.
The associated costs and delivery time varies between our own warehouse and different manufacturers.
I would like to calculate the fastest and the cheapest option.
First I need to calculate all possible combinations, then I can join estimated costs and delivery times (these are available in a database).
Next, I need to aggregate the values and pick the cheapest and fastest option.
What I am struggling with is calculating all possible combinations.
If all items n can be drop-shipped, the total amount of combinations should be 2 raised to the power of n. Because of the exponential growth in combinations, I would only handle orders with up to 15 items.
Here is a workflow with sample input data and what the output should look like.
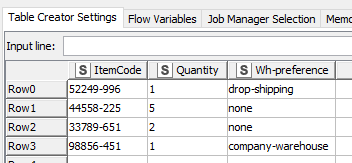
This is the input. There´s the item code, quantity and a column for Wahrehouse preference. If a preference for a warehouse is set in the Wh-preference column, the item should only be shipped from this warehouse and no other options need to be considered.
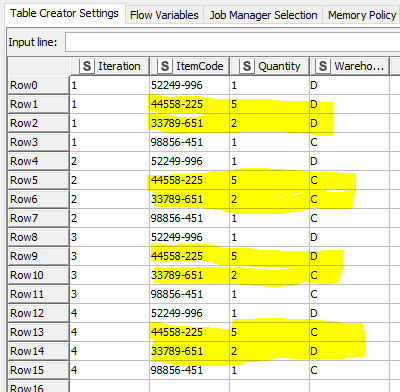
This is the desired output with all possible combinations. The D and C in the warehouse column stand for drop-shipping and company-warehouse. Only the yellow marked lines iterated through all possible combinations, the warehouse for the other items stays the same due to the warehouse preference in the input table.
Maybe this helps:
I found a forum post dealing with a similar problem. Unfortunaltely I am not able to adopt the logic to my problem.
The idea of treating the combinations as a binary problem (0=company-warehouse, 1=drop-shipping) looks like it could also be applied here.
I wonder if this will do it. It looks like it does based on your sample data.
The idea here was to group, for each item, the available set of warehouse-prefs and then once they were grouped, to selectively ungroup each (one at a time). A feature of ungrouping is that it duplicates all the other rows across each ungrouping, so ungrouping one at a time means that we get back all the possible combinations. Nice theory anyway. I hope it’s right!
In the workflow, I ungroup from the column with the smallest number of preferences to the largest in that order, but now its written, I’m not sure that was necessary, so you could experiment to see if the sorting makes any difference. I suspect now that it doesn’t.
The recursive loop is key to acting on the table in a way that allows a different ungrouping on each iteration.
The rest of the flow is grouping, transposing and unpivoting to get the data reassembled in the format of your output table.
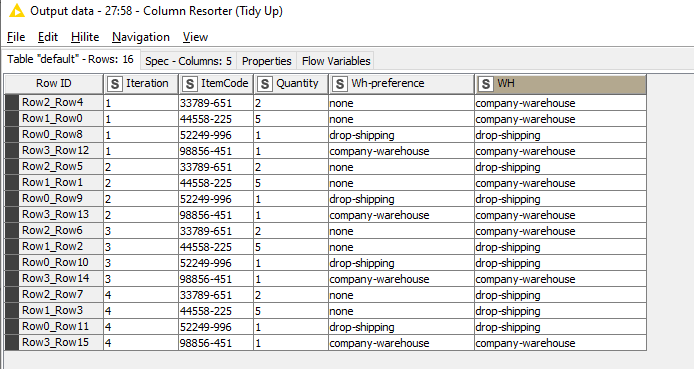
This is what pops out the end. I left in the original preference for comparison and testing purposes.
Hopefully the comments I’ve put in explain the sequence of events. Possibly on review there may be a few shortcuts to chunks of this workflow, but hopefully it’s a starting point for further ideas.
Wow. Thank you @takbb.
I´m speechless, that was quick!
I did not have time yet to test with different scenarios, but it seems to do exactly what I need.
Hi @e2boden, that’s great, and thank you for marking it as the solution. The process of grouping/ungrouping feels like there might be scope for creating a new generic component for doing this kind of “find all combinations” task that I had not previously considered.
… something to think about