This sounds easier than it is. I have to read files with an unknown number of columns and an unknown name of each column. I need KNIME to read all these columns as strings.
Example, when reading one file with postal codes from the US, it decided the column was an integer because there was no alpha-characters. In the process, postal codes with leading zeros are damaged. So I can’t convert them to strings after the read.
This is easy to do with CSV Reader and File Reader if you know the name of the columns in advance. But since I don’t know the column names in advance, I would have to change the File Reader configuration manually for every file submitted. That’s no an option.
As brute force solution: Load CSV without specifying it has header. So it will load everything as text (if there is no headers like 123). Then write it to the temporary CSV and read it specifying there is a header. For small files it has to work.
Thank you both. The R solution would work well, but it does introduce something my team is not familiar with. I do love the option to read in the header. I can extract that first line and convert it to column names without too much effort.
Use the File reader node. Once you load a CSV file, you can click on the column header to change column properties. including changing a number to a string.
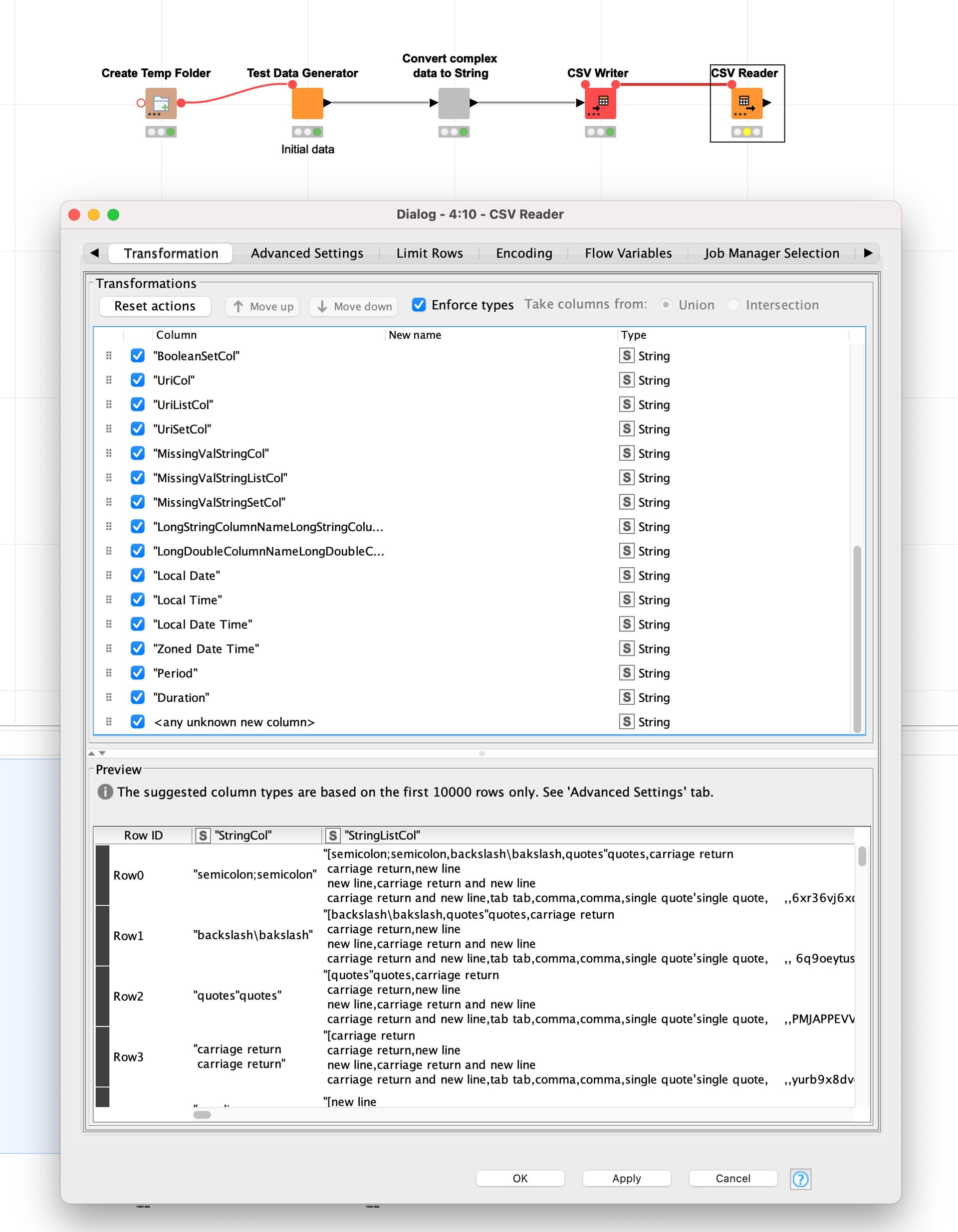
I happen to work on a workflow which allows to dynamically set the column types. Your challenge can be accomplished by exploiting default node behavior.
Important two know and adhere to are three things:
CSV must be saved by the source with enforced quotation (regardless if necessary or not i.e. in case of type int)
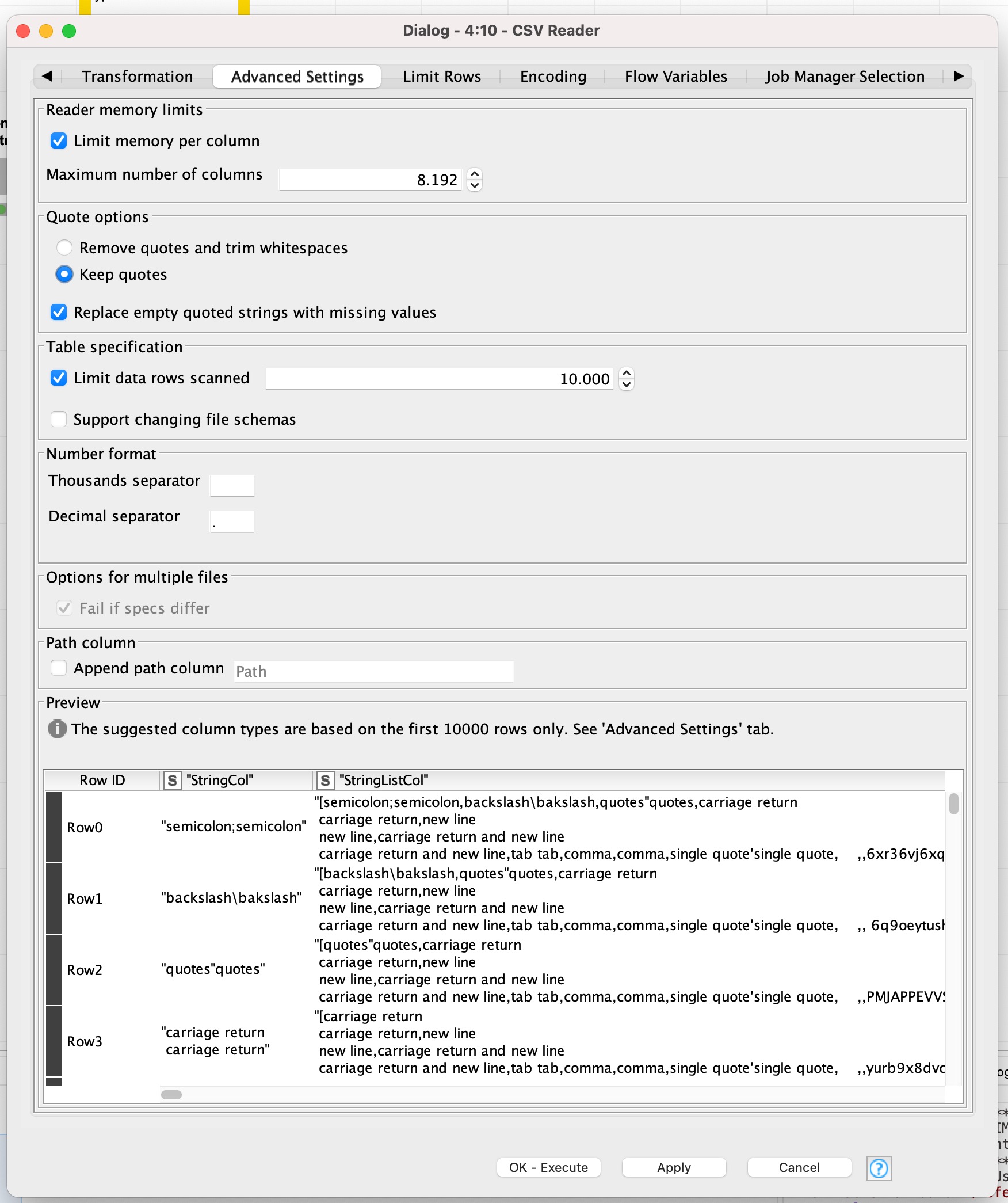
CSV Reader setting requires “Keep quotes” being defined (1st screenshot below)
Any unknown column must be forced to type String (2nd screenshot below)
Quick question @mlauber71 and apologize if stray away form this conversations purpose with it but this might help me about another challenge:
Do you happen to know all / as many Py-Representations of the column types listed? I wonder if, via your solution, it would be possible to not only extract but also enforce data types during read.
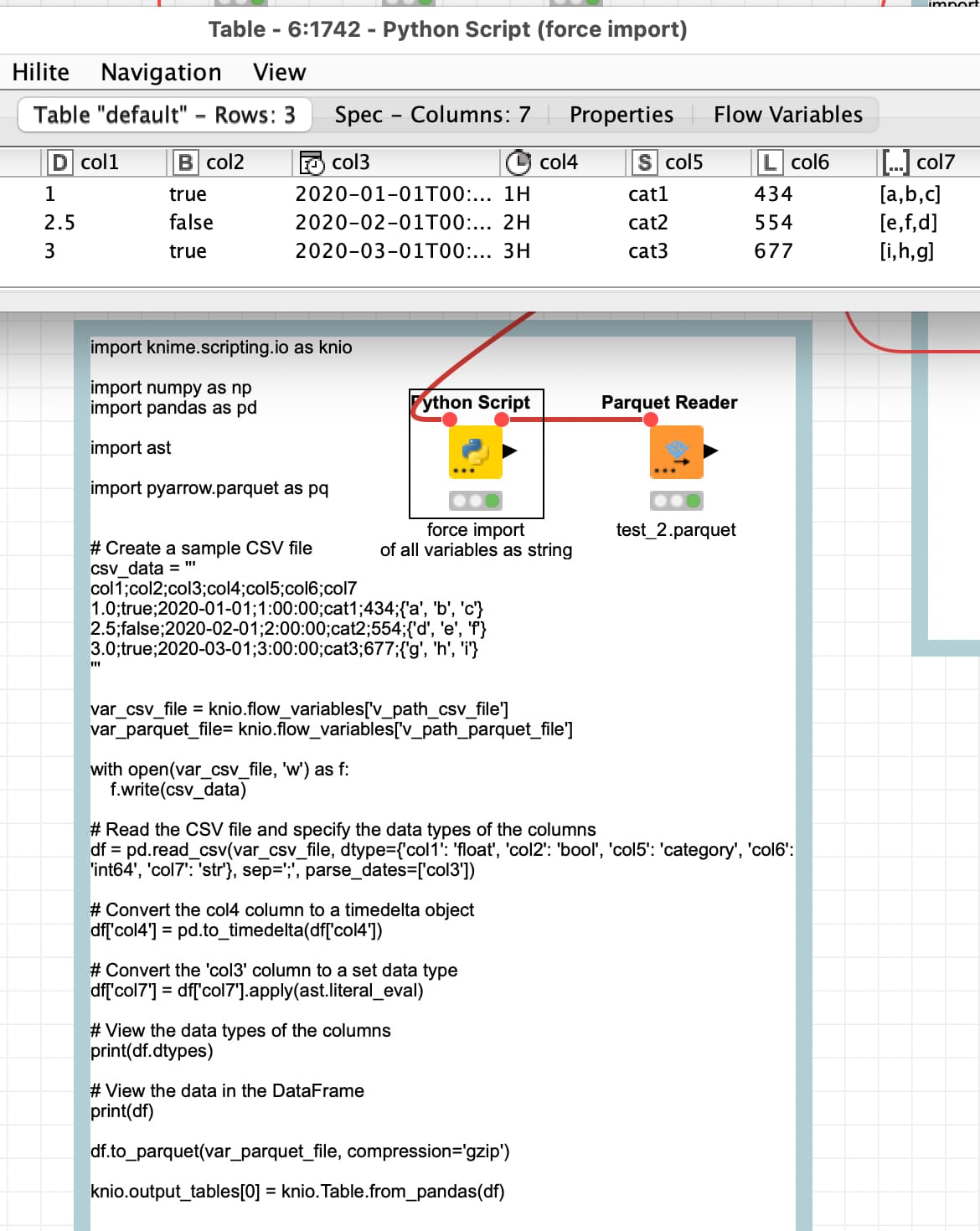
@mwiegand that should also be possible and it took ChatGPT only about 4 tries to put this together and there still might be more data types out there - also shows the limitations of this automatic programming approach …
import pandas as pd
import pyarrow.parquet as pq
import ast
import pyarrow.parquet as pq
# Create a sample CSV file
csv_data = '''
col1;col2;col3;col4;col5;col6;col7
1.0;true;2020-01-01;1:00:00;cat1;434;{'a', 'b', 'c'}
2.5;false;2020-02-01;2:00:00;cat2;554;{'d', 'e', 'f'}
3.0;true;2020-03-01;3:00:00;cat3;677;{'g', 'h', 'i'}
'''
with open(var_csv_file, 'w') as f:
f.write(csv_data)
# Read the CSV file and specify the data types of the columns
df = pd.read_csv(var_csv_file, dtype={'col1': 'float', 'col2': 'bool', 'col5': 'category', 'col6': 'int64', 'col7': 'str'}, sep=';', parse_dates=['col3'])
# Convert the col4 column to a timedelta object
df['col4'] = pd.to_timedelta(df['col4'])
# Convert the 'col3' column to a set data type
df['col7'] = df['col7'].apply(ast.literal_eval)
# View the data types of the columns
print(df.dtypes)
I used it that way, but using sep=None to auto detect the separator and encoding=‘unicode_escape’ to avoid some errors that were coming up and it worked too. I’m not a python pro, what do you think of this solution?