I want to extract the column type to save this alongside i.e. a CSV file in order to once after reading CSV again, reinstate the original column type(s). Reason for that is that data might get shared / transmitted in human readable text files types. But, reinterpreting column types is time consuming and failure prone.
I am trying to accomplish this by looping over the table of data types derived from aforementioned workflow.
Not really an elegant but more a brute force approach (due lack of ideas currently). However, it seems the type can not be managed through variables, can it?
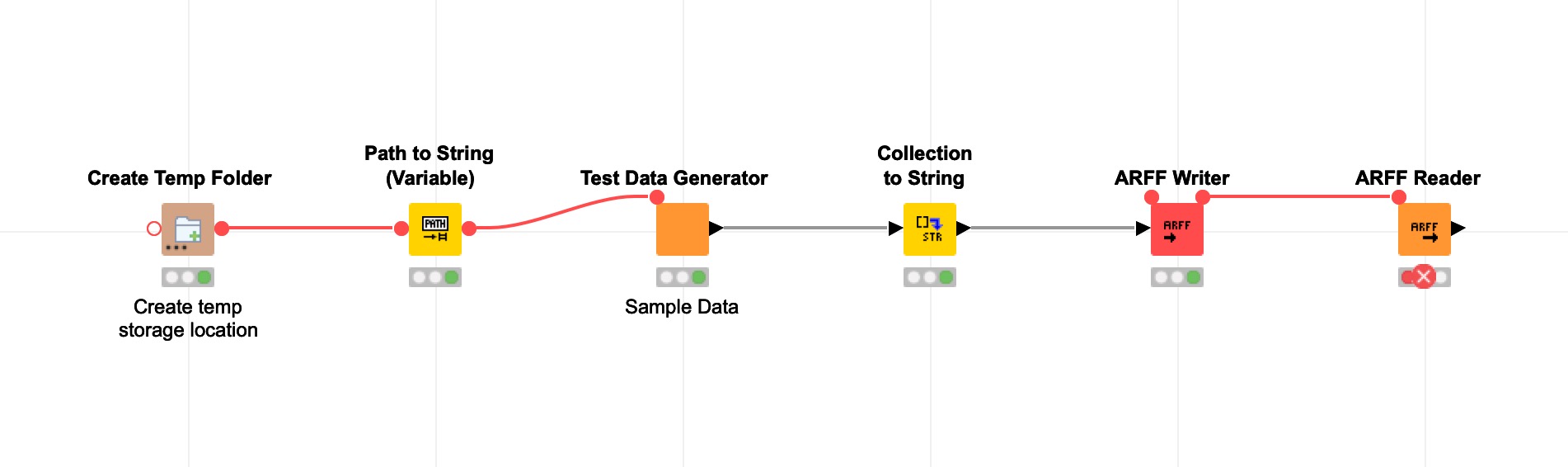
WARN ARFF Writer 5:1708 Class List (Collection of: String) not supported.
There are some complex data types I am curious they can exist outside of Knime and still being readable. Adding more to my explantion / the reason why, not everyone will or can use Knime. Having a human readable but still interchangeable format would make adoption easier. Some only trust, understand and therefore support what they can actually see.
Anyways, sometimes it’s necessary to leverage meta information such as the column type or date time format in order to properly make systems / processes understand each other. Having to guess / try & error each time, is one of the root causes of potentially nice solutions being never adopted.
@mwiegand if we are into interesting (re-)engineerings concerning text files I can add the case of a MySQL Dump being imported into H2 …
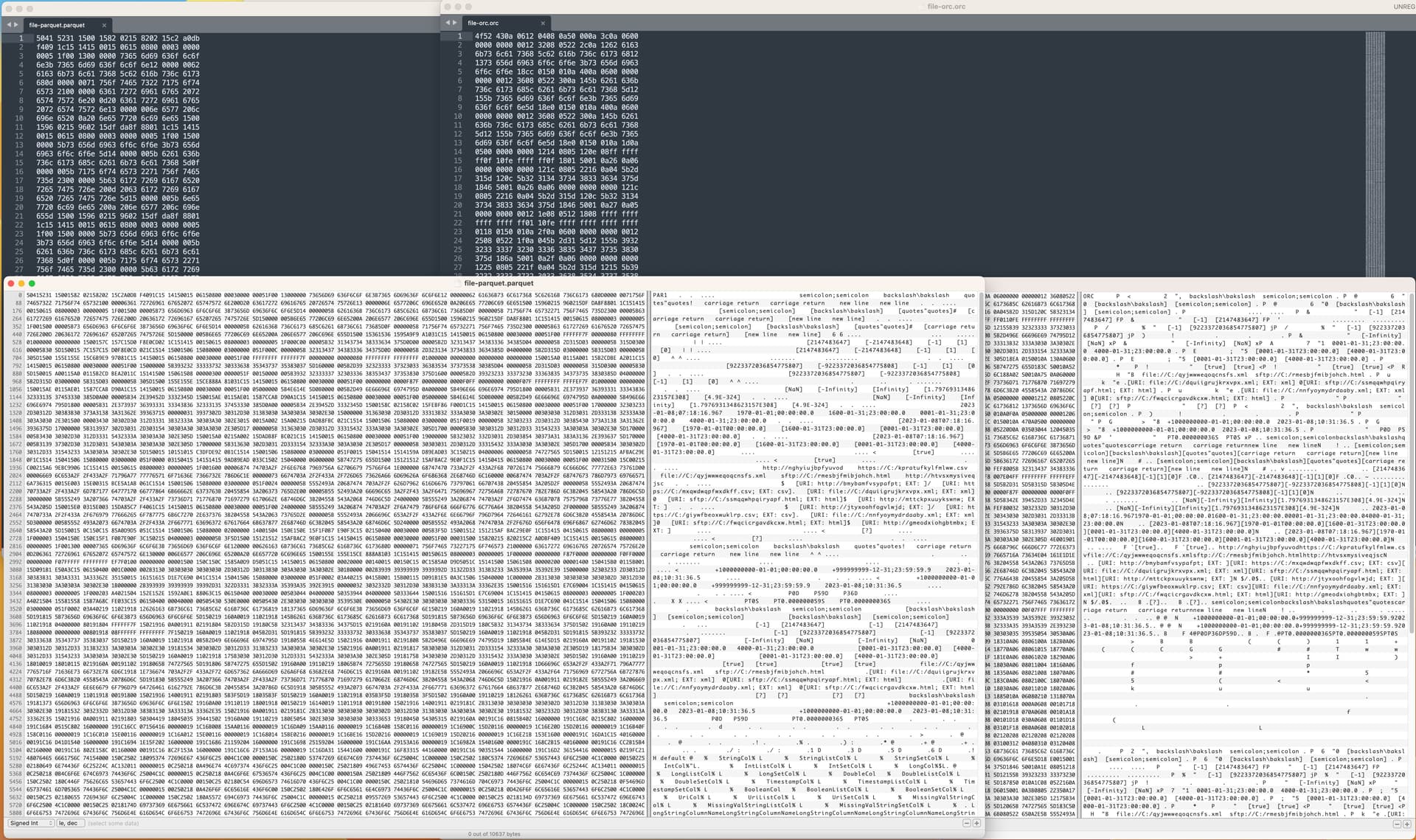
I think the most transferable file format still is Parquet. Another one might be ORC though with KNIME not exactly as flexible. Also SQLite and H2 are quite common to exchange information. But admittedly they are not text-only. KNIME itself supports a very wider arrange of data formats that you will not see in most other applications.
that sounds like a nightmare but pretty much falls into the nice exercise of “will it blend”
The Parquet nodes I became aware about recently too and thanks for the reminder. It feels like these are one if not the only possible solution. Got to familiarize with Parquet more. Will check ORC as well.
If I find a solution to ensure column types are preserved as some sort of meta file, I will circle back.
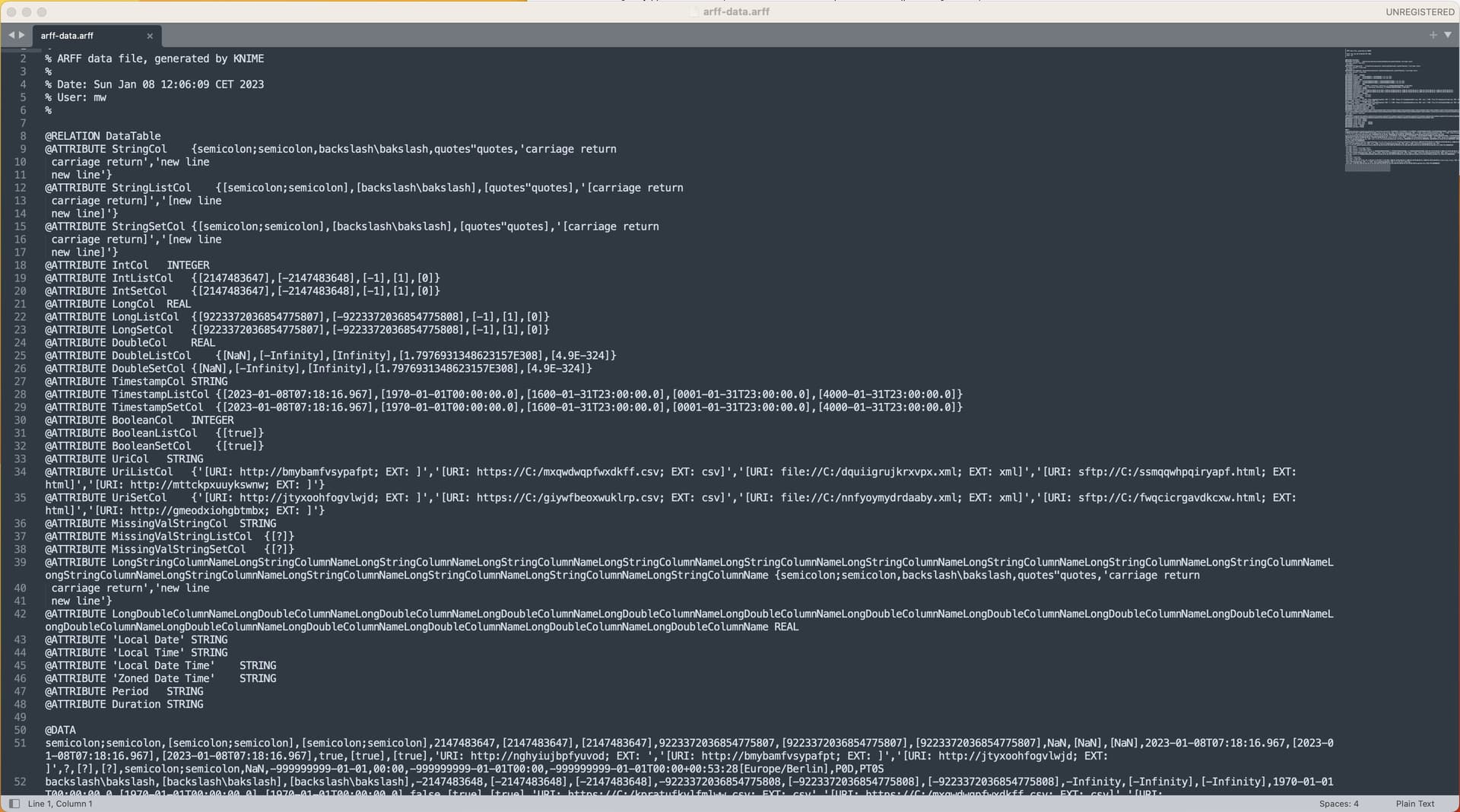
The ARFF Writer does (yet) not support paths (to point to storage location, column type untested) and the column type Collection. However, it looks more promising as it’s kind of human readable
Unfortunately, the writer node seems to miss proper quote treatment causing the ARFF Reader to break: ERROR ARFF Reader 5:1726 Configure failed (TokenizerException): New line in quoted string (or closing quote missing). In line 9.