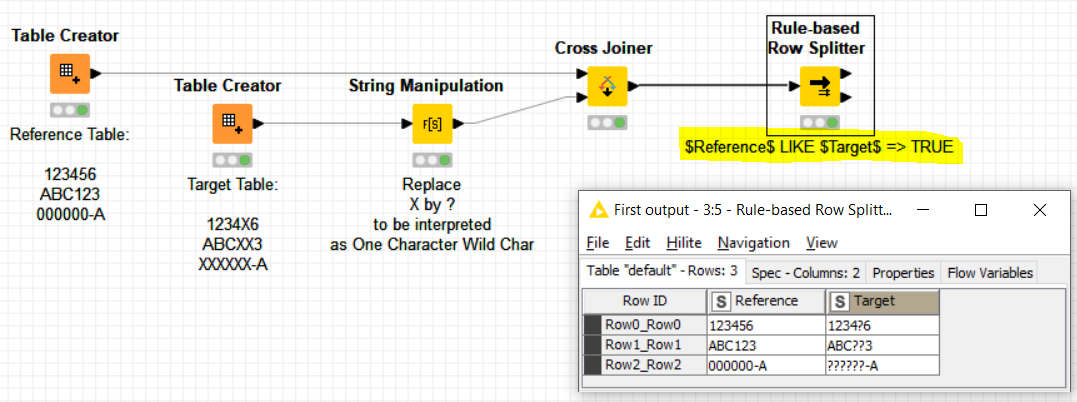
So I have a challenge in KNIME where I have two datasets that I want to compare/join based on a keyfield. So far so good, you can use the joiner. However…this is not a regular join.
I have wildcards in my data. Here are some random examples:
Data column A (for example):
123456
ABC123
000000-A
Column B (to join):
1234X6
ABCXX3
XXXXXX-A
The X represent a wildcard number, meaning they can be numbers from 0 to 9. Now what I want to achieve is to cmpare column A and B. However like this they will not match of course. I am looking for a method to tell KNIME that the X are wildcards so that eventually KNIME will match these.
eg. the last entry from column B should match with column A, because it meets the criteria of the wildcard.
I hope this makes sense? Has anyone already encountered such a problem and how did you solve it? Looking forward to your ideas!
Hi thanks for you comment. Maybe I did not explain my problem clear enough, as I think we are talking about different things here.
So I have two streams of data, one which is my masterdata and another one with that has data I want to lookup (through a joiner (usually):
My master data has a column we’ll call Column A containing thousands of lines with partnumbers.
My other stream of data has a column we’ll call Column B, containg thousands of lines with partnumbers but also some that have wildcards. There is also an additional column which is the data that I want to retrieve from it to join to my masterfile.
However if I do the Joiner node (keys: Column A & Column B) it will of course not match the partnumbers with wildcards in them. So I am looking for a method to account for wildcards, represented with an “X”. X being any possibility from 0 to 9.
I hope this makes sense, otherwise I’ll make a screenshot in KNIME tomorrow
Be aware that a -Cross Joiner- is quite memory greedy so for a very big joining, I would add extra tricks. Please let us know if this is the case and we will suggest further improvement.