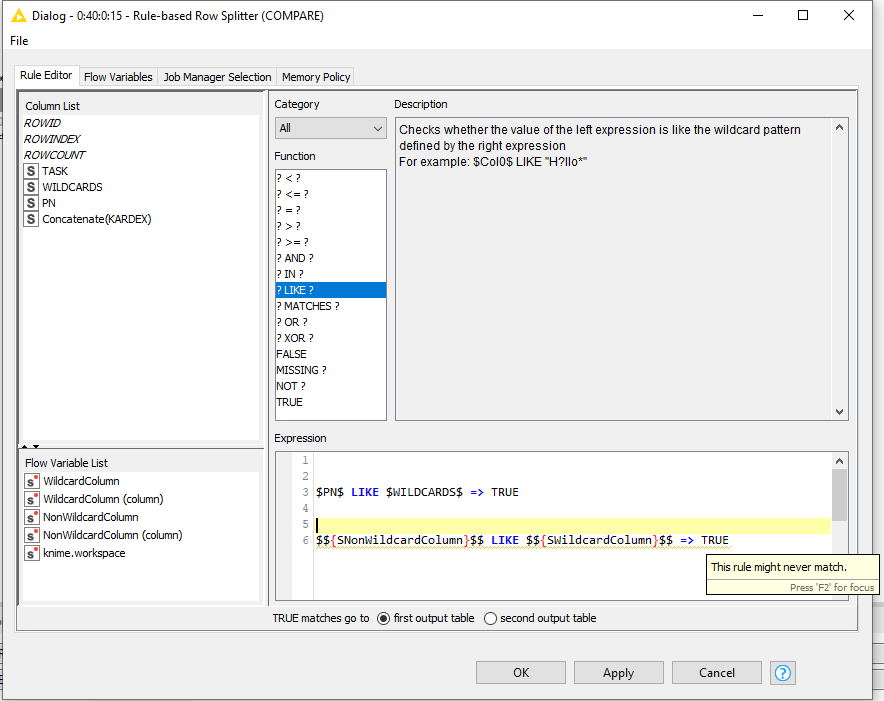
I now want to make a comparisson with the rule based rule filters with a LIKE for wildcards. This works when I manually select the columns, but now I want it to be controlled with a variable. But then it somehow doesnt work anymore and I dont understand why. Below an example:
The first line of code will work. But if I replace it with the second one it wont work. Even though the variables are exactly the same column names as the first line of code. Does anyone know what Im doing wrong?
If you enter a Flow Variable like that, it will compare against the value of it.
If you want to compare two columns with each other, and use dynamic column names for it, you could rename them before and after with a Column Rename node. That allows you to write a static rule.
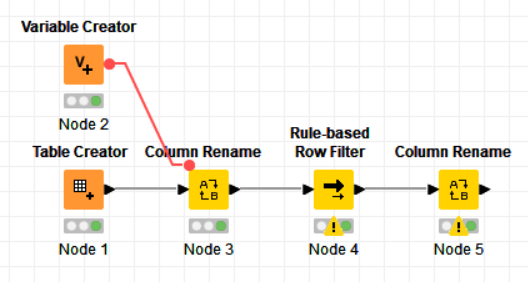
I attatched my workflow here. As you can see there are two rule based row filters. Of which one works but the columns are hardcoded/selected. They must be selectable throught the component configuration as I created. But the comparison doesnt work there.
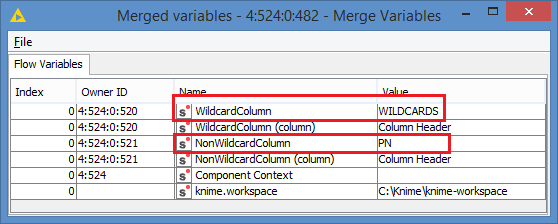
Hi @Sjoerd , so the best way to debug this is just to check what you are comparing. To do this, since you are running this rule $${SNonWildcardColumn}$$ LIKE $${SWildcardColumn}$$ => TRUE, just check the values the variables NonWildcardColumn and WildcardColumn by simply viewing what’s the variable output of the previous node, which is your Merge Variables (Node 482):
So, basically you care comparing “PN” LIKE “WILDCARDS”, which is not true.
EDIT: And since you are comparing variable to a variable, instead of variable to a column, the rows are being ignored, and each row will evaluate to the same result, which is the result of “PN” LIKE “WILDCARDS”, which is false. So, none of the rows will be TRUE, hence why you get nothing in your top data output of your Rule-based Row Splitter. All of the rows went to the bottom since they all evaluated to false.
If I’m correctly getting what you are trying to do, you need to rename the columns instead. You cannot pass column names dynamically to the Rule-based Row Splitter.
Also, it’s not exactly the best way to do this kind of column selection, because the component cannot know what the columns of the 2 input tables are before being run - try the drop downs before running the Component, you will not see the columns PN or Column 1 in the MAIN INPUT box. The Value Selection Configuration nodes within the component have to run first for the drop downs to be populated properly.
Okay, I understand now that there is just no way to let the rule based rule filter work with dynamic column naming…
I managed to solve it now with your suggestions of renaming the column names first and then renaming it back. Seems a bit farfetched?
As for your suggestion with the drop downs, you suggest it should be seperate from the component first, correct? Indeed now I first have to run it, then select the columns I want and then run it again.
Not at all farfetched. It’s the correct approach. Rename them to the column names you are using in your Rule Engine, run your rule, then rename back so that the columns are back to the original ones. That’s how you make it seamless
For the drop down, it’s tricky, but I would definitely separate these Configuration nodes from the operation since they need to run first. You don’t want to have to re-run the whole thing.
EDIT: An additional note regarding capturing the column headers for the drop down. You are using the Extract Column Header, which is one way of doing this, but be aware that you are basically re-creating your data table with this node as in you are duplicating the data and additionally using the same amount of resources of the data table. In your case, you do not need the data, just the header. Resource-wise, it could be better to use the Extract Table Spec node instead of the Extract Column Header in this case. Basically you want a “filter” instead of a “splitter”, and Extract Table Spec will give you the header without the data.
I might also recommend to use a Loop instead of the Cross-Joiner if your input tables are somewhat big. It’s fine if KNIME doesn’t hit the memory limit, otherwise you’ll want to loop it.
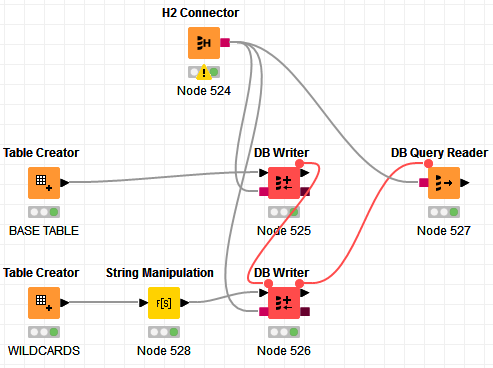
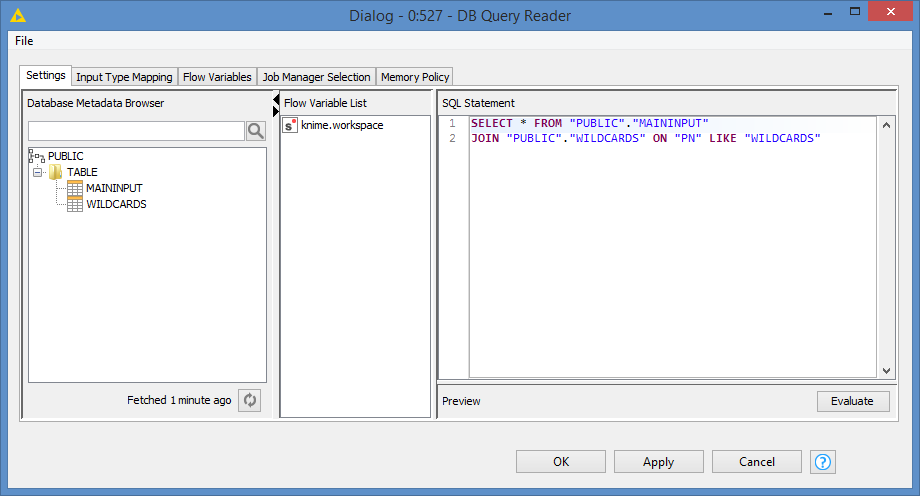
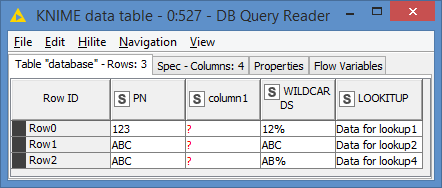
Hi @Thyme , if the data is big enough, I would say the most efficient way to do this would be to load both tables in an H2 virtual DB, and then do a JOIN with a LIKE. No Cross Join, no Loop
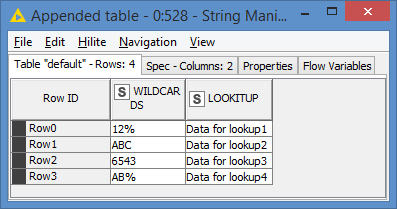
EDIT: A quick demo:
First, change the Knime wildcard character “?” to the DB wildcard character “%” via the String Manipulation:
After that, write the tables the the virtual DB. Then run this query: