Hallo xiaokang_fu,
I got the Moran’s Local I evaluation after experimenting.
The error message described earlier is due to the focal and neighbor columns being strings. I converted this to an integer. Then it worked.
Moran’s Local I cannot be run using Spatial Weight directly.

It also doesn’t work with a set RouID
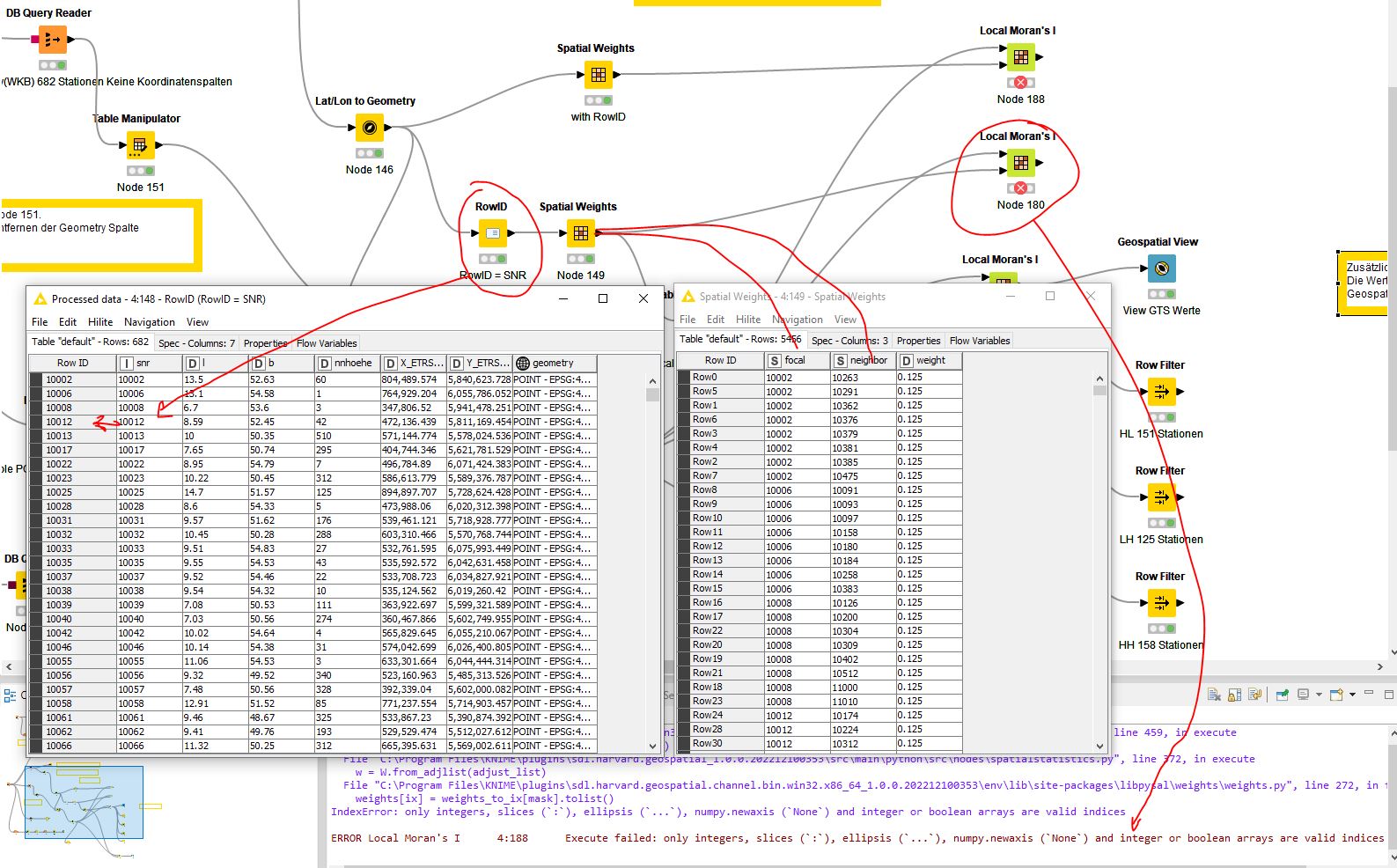
Now, based on the error message, I have converted the columns from string to integer.

However, the result is not plausible, wrong.
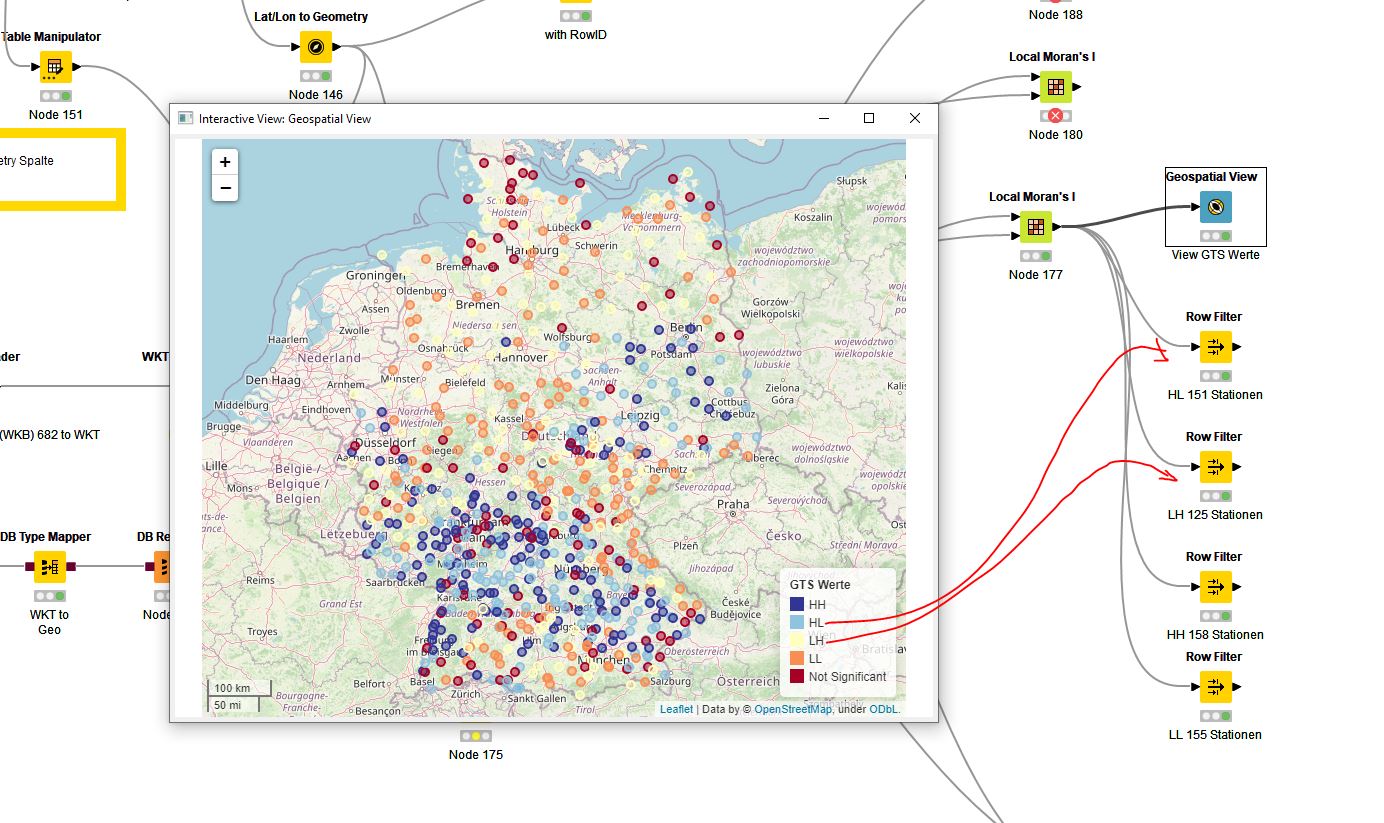
Far too many LH and HL values are determined.
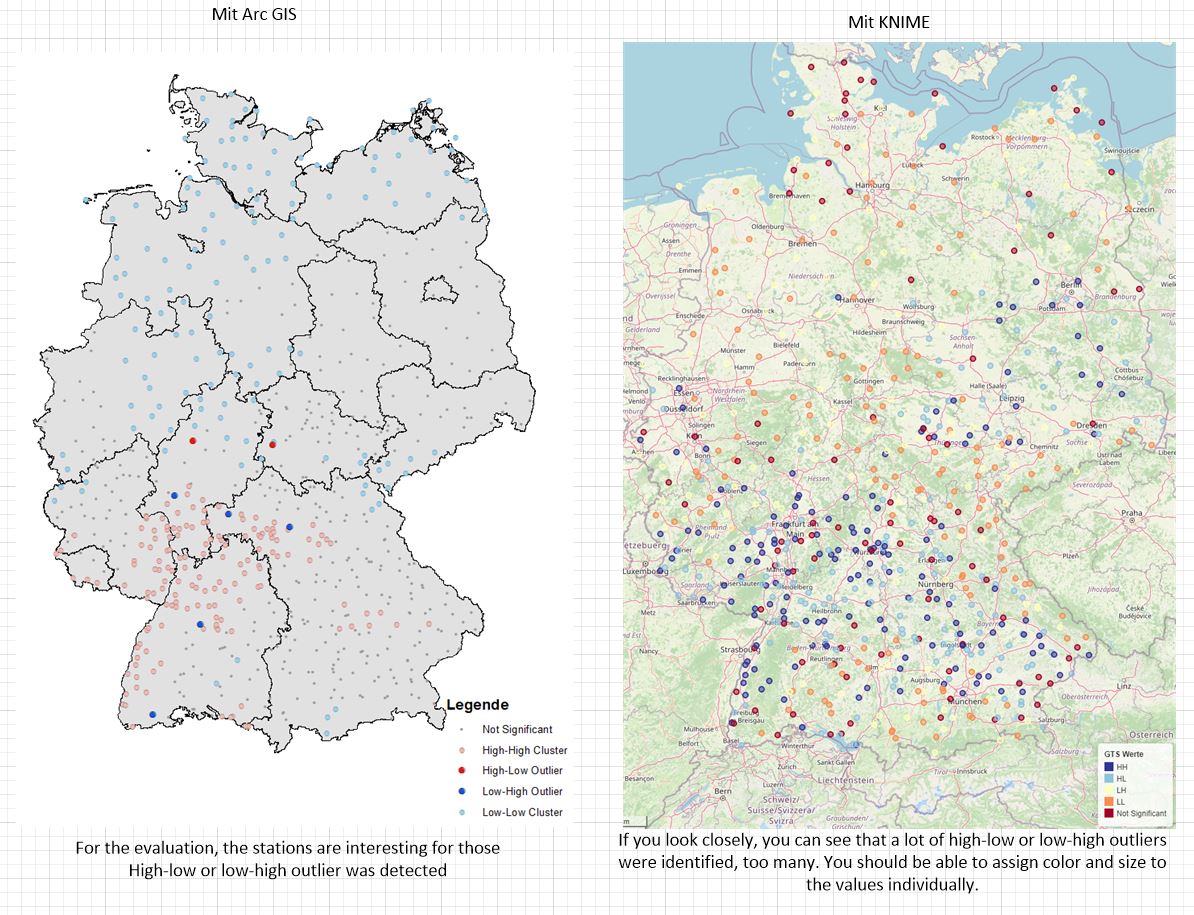
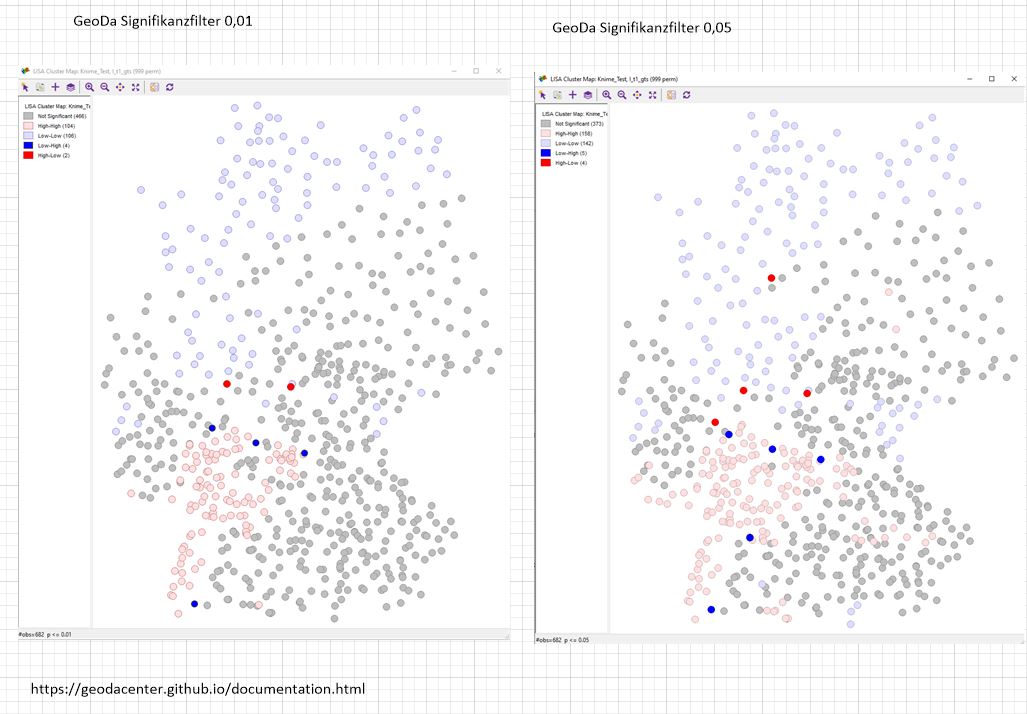
Finally, a comparison with other programs that I have been using for years.
Best regards
Patrik