Hi @jarviscampbell , there are some tricks with certain nodes that alone don’t seem to do much but together they become quite powerful for specific functions.
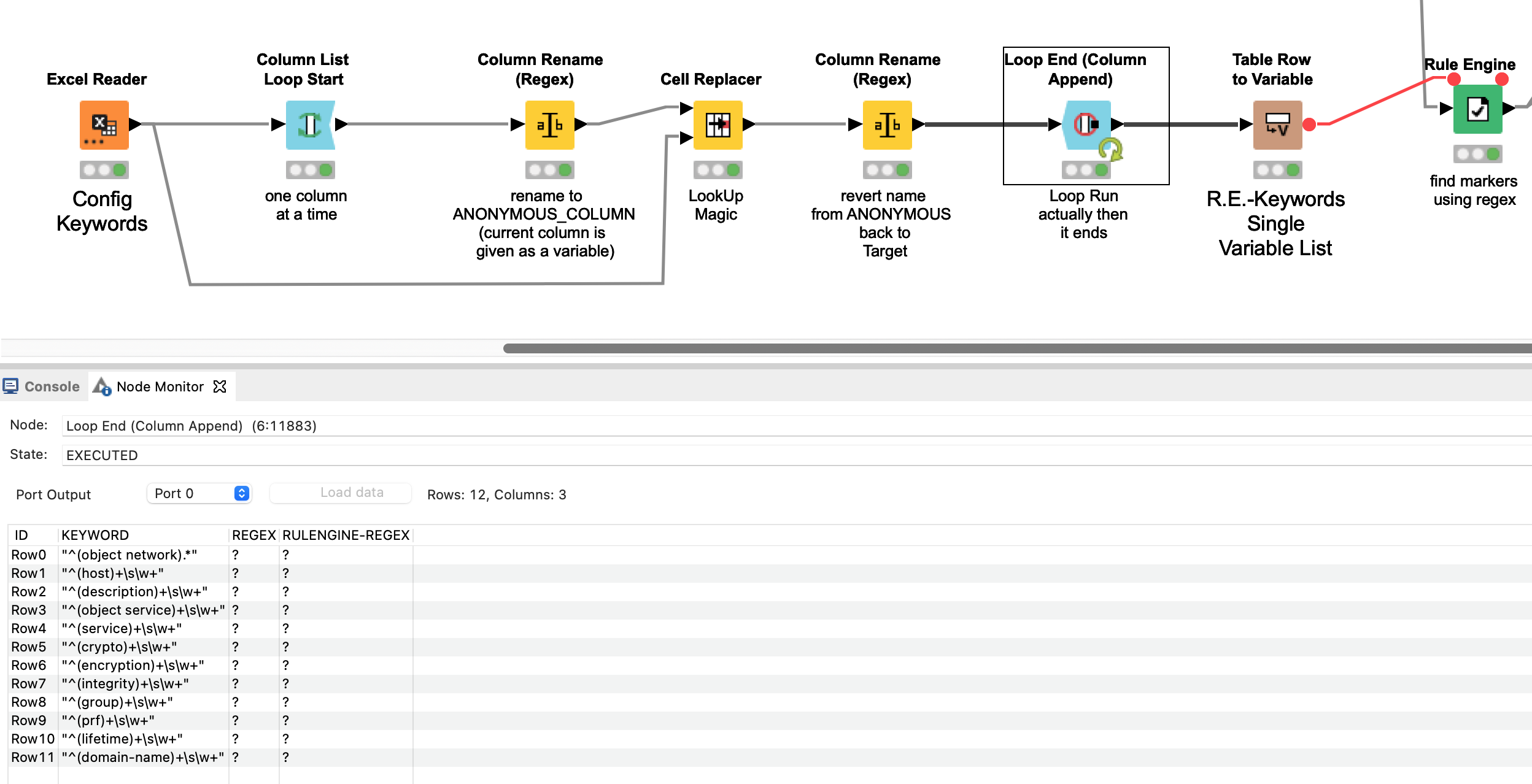
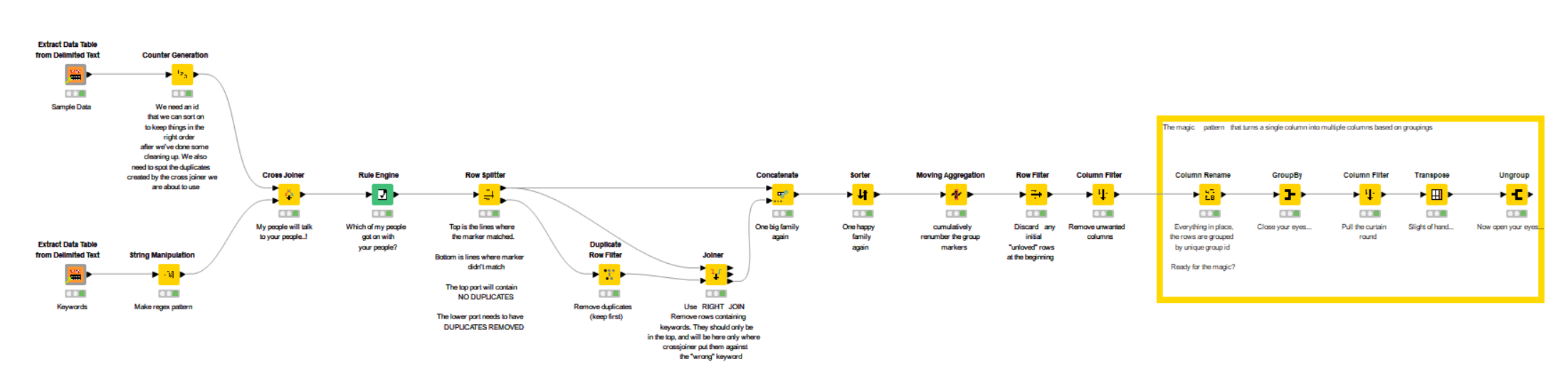
This workflow contains a couple of those different tricks, or “patterns”.
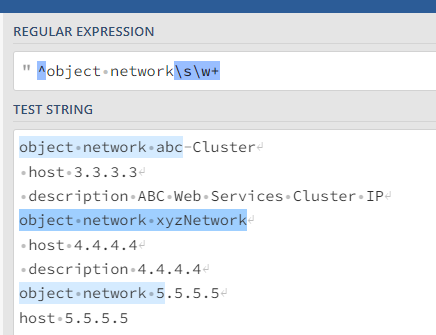
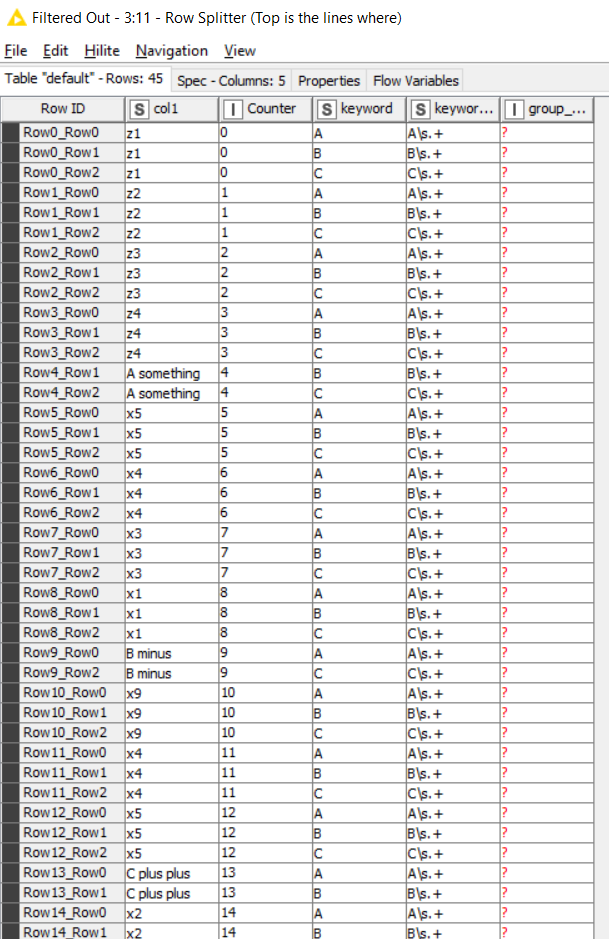
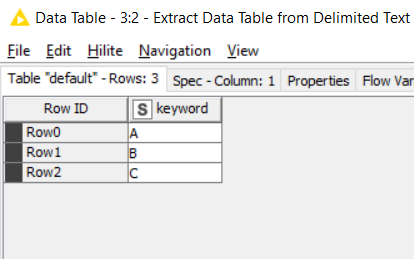
On the left, I used my sample data as it was simple to work with. We have this:
After the data I added a counter generation. Counter generations are good for keeping rows in the right initial order after you’ve done a load of transformations. So we give each row a number.
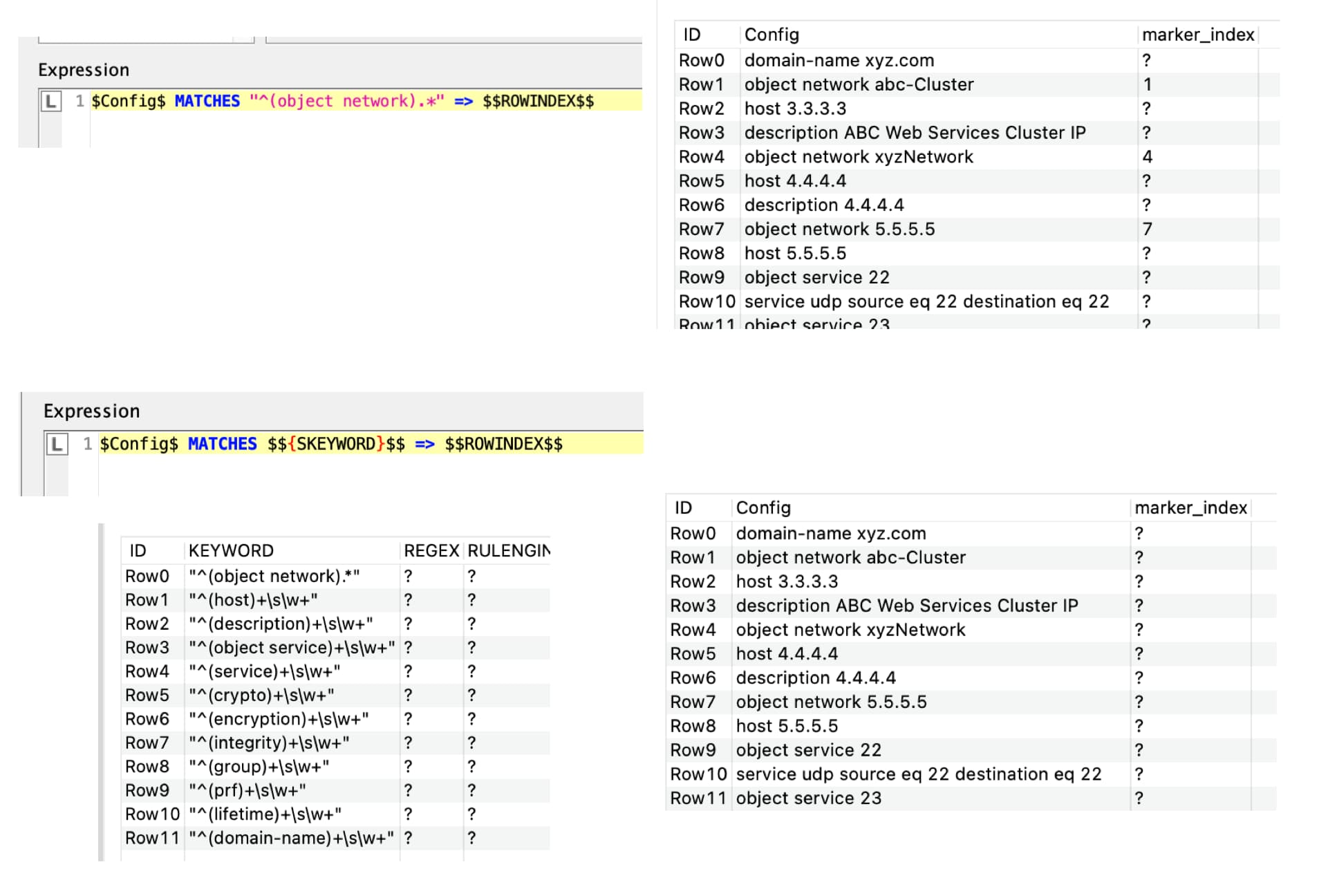
The other input is the set of “keywords” (initial parts of phrases to be found)
A String Manipulation turns all of these into whatever pattern we deem appropriate. You might change this regex if it doesn’t perfectly match your data:
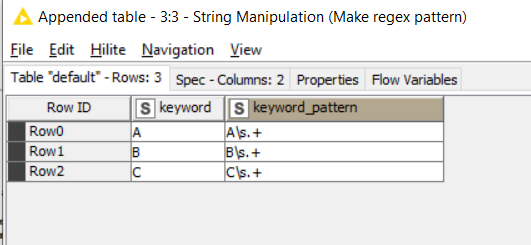
This regex I have here is similar but not quite the same as yours and here will of require that only matches containing some whitespace and at least one other character will be found. That may not be right for you, and you can adjust it accordingly.
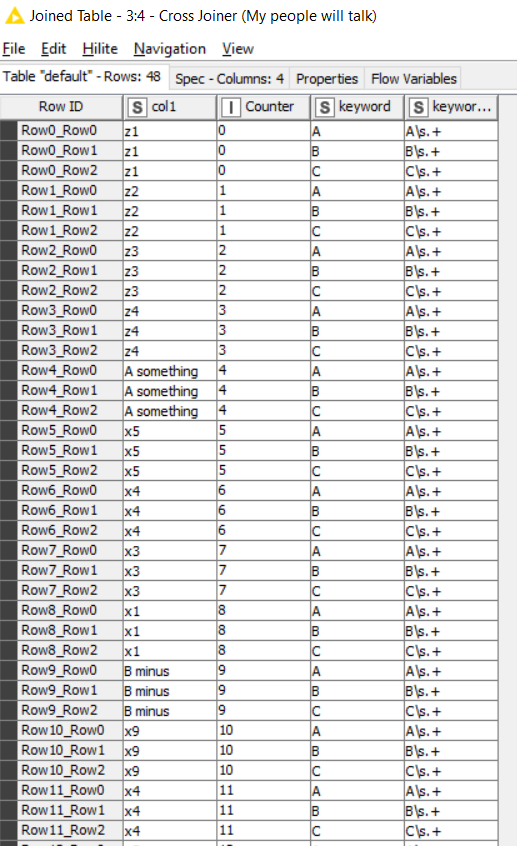
The seldom-used cross-joiner is up next and joins every row to every other row. If your keyword dataset is small then this should be ok. If you cross joined tables with thousands of rows each, it starts to get more inefficient and memory-hungry.
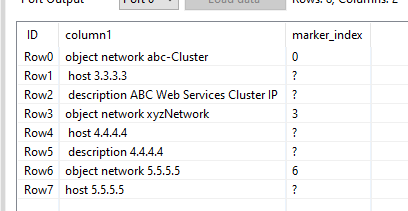
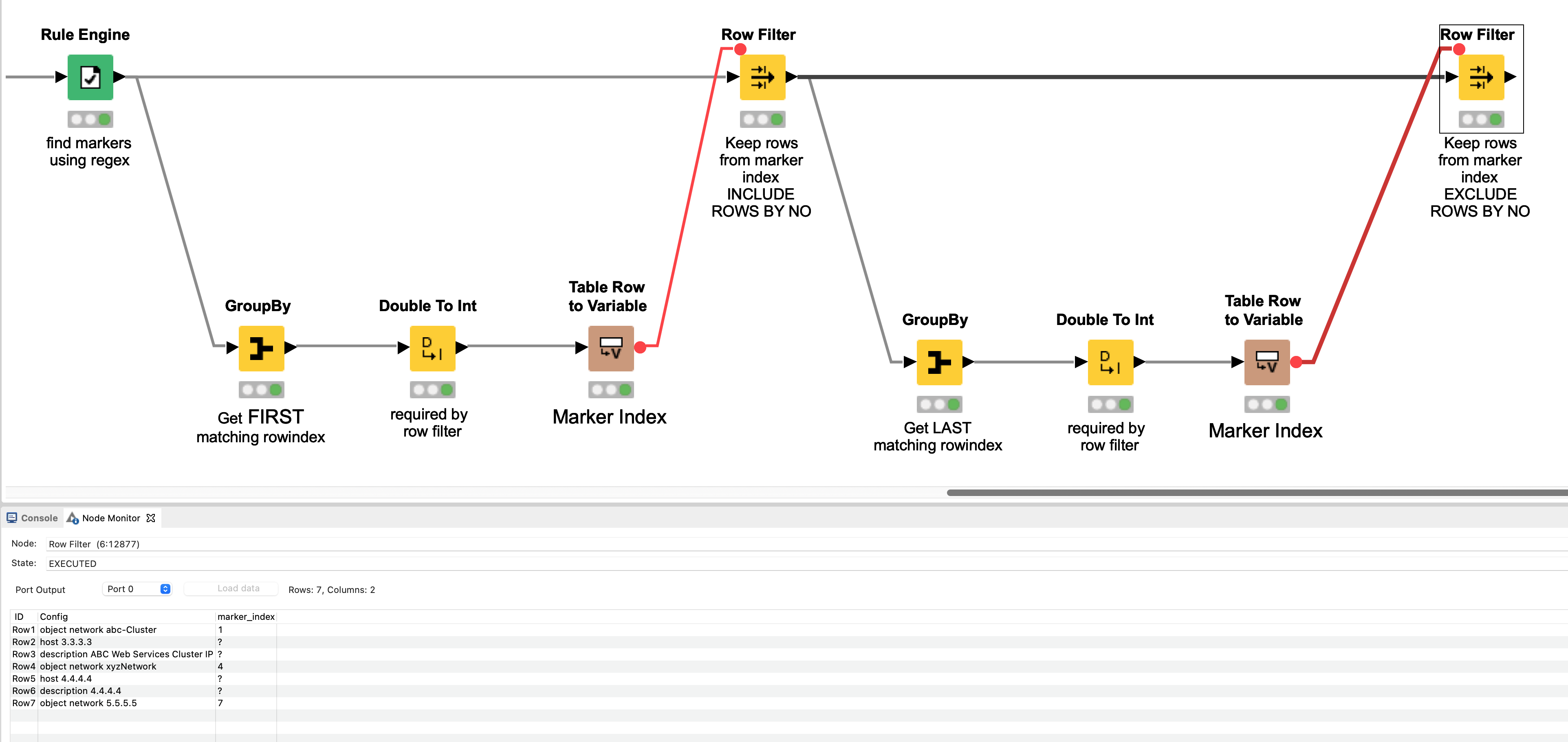
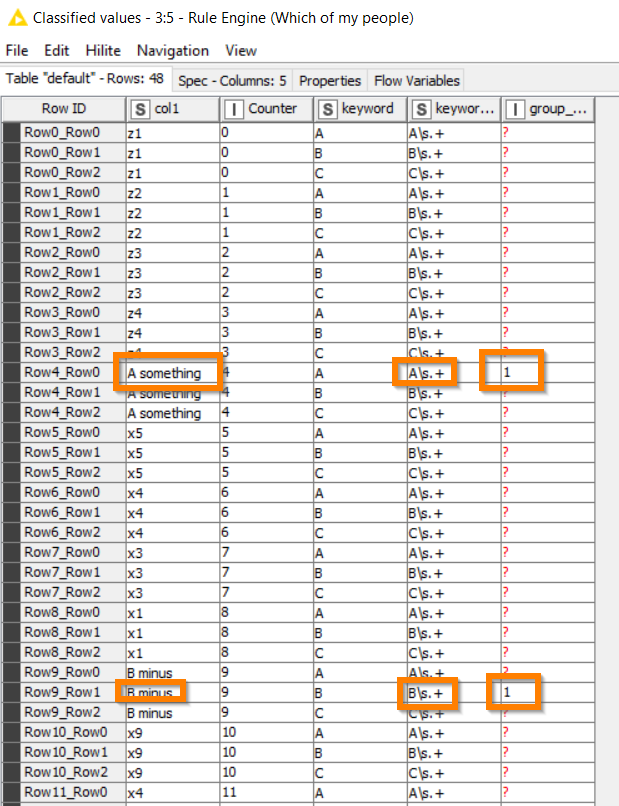
Next a Rule Engine looks at each joined row and finds those rows that actually match a keyword and places a 1 in the new column
It has to be a 1. The reason for that comes in a minute, but first we want to get rid of all those extra rows we generated:
First off we want to split out the rows that are “markers” (they have a 1 next to them) from the others:
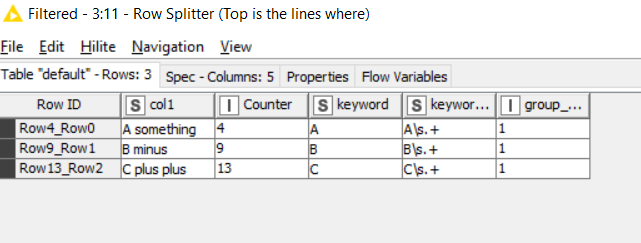
The upper set contains no duplicates because they matches a pattern, but the lower set has a load of duplicates because they are the remaining rows which didn’t.
So a duplicate row filter gets rid of the duplication created by the Cross Joiner. But we still need to get rid of duplicates created from Marker rows that we attempted to match with the wrong keyword.
We can identify them by joining this lower list back with the set of Marker rows correctly identified on the top port. If we Right Join with it, we will be returned only the rows that are not “Marker” words
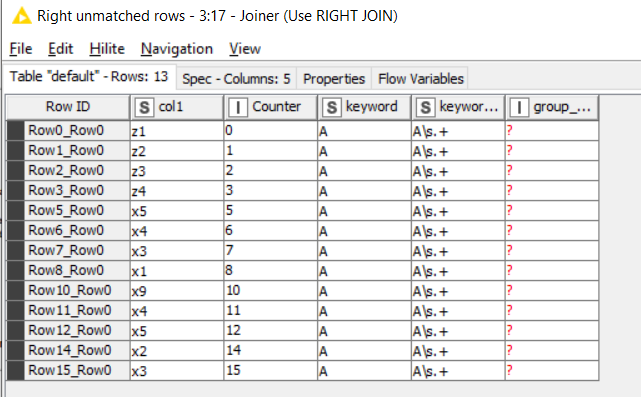
So we now have the data but we need to bring the Marker and non-marker rows back together with a concatenate
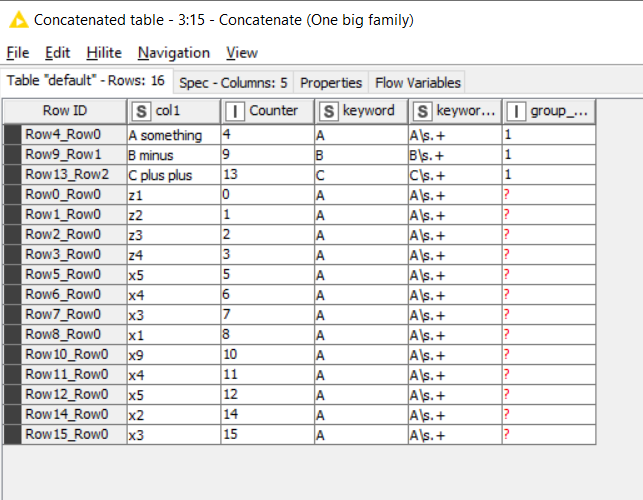
And make use of the Counter Generation from the start, to re-sort into the original order
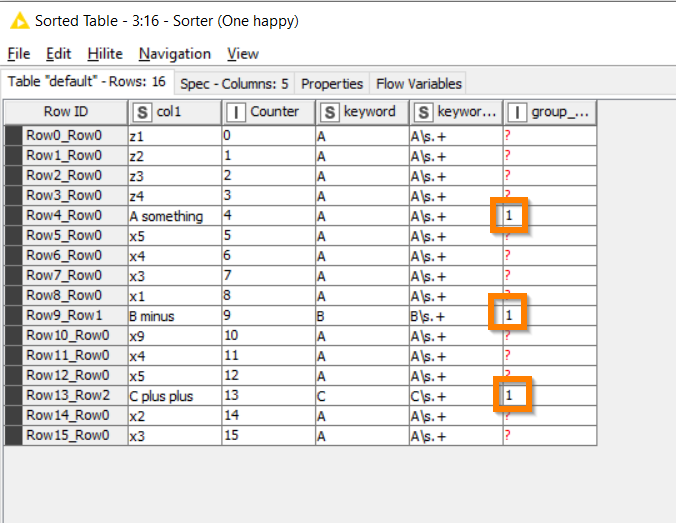
Now, you remember those 1 values that we got the Rule Engine to put in?
This is where we make use of them. A Moving Aggregation node can be configured to cumulatively sum this column down the table. And the result is this:
A simple trick, but we have now given all rows associated with each marker, a “group identifier”
A row filter can now discard those “unloved” rows that appeared before the first marker, and a column filter followed by a Column Renamer can tidy up a little.
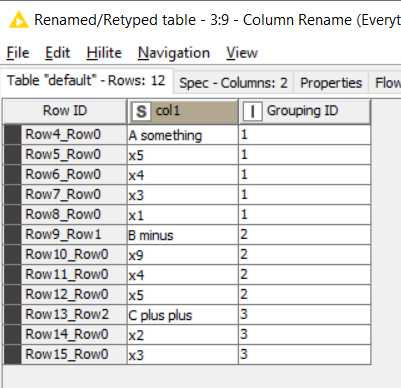
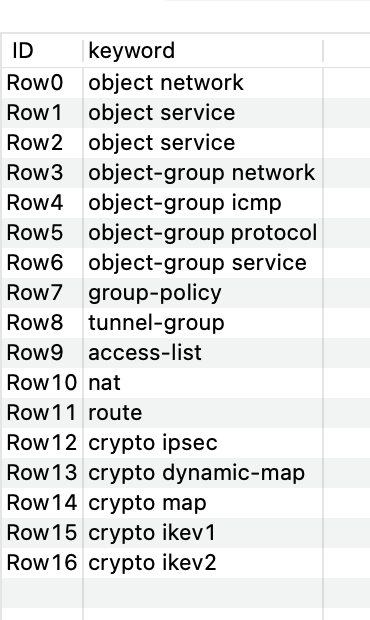
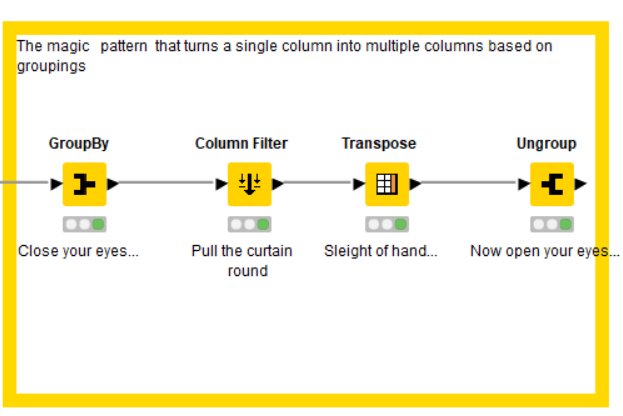
And at this point, we are practically done. It leaves just one more trick involving a GroupBy, Column Filter (to remove the Group Number because it will now get in the way), a Transpose, and an Ungroup.
The Group By groups each row by group id into a list, the transpose puts each of these lists into its own column, and then the ungroup makes them back into rows again.
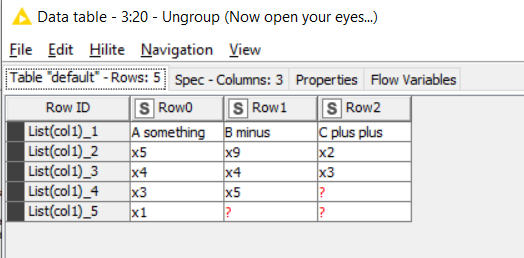
With this end result:
Breaking rows by keywords and breaking into column groups.knwf (101.5 KB)
I could have added a RowId node to tidy the rowids, and possibly a Column Rename (Regex) to turn Row0, Row1, Row2 into Col0, Col1, Col2 or something like that… but I am told you should always leave the audience wanting more