Yes, here you go, I was exporting to a new workflow. Mine is a mess at this point ![]()
GroupBy-v4.knwf (154.0 KB)
Yes, here you go, I was exporting to a new workflow. Mine is a mess at this point ![]()
GroupBy-v4.knwf (154.0 KB)
Nah, something is missing, I think… check it out
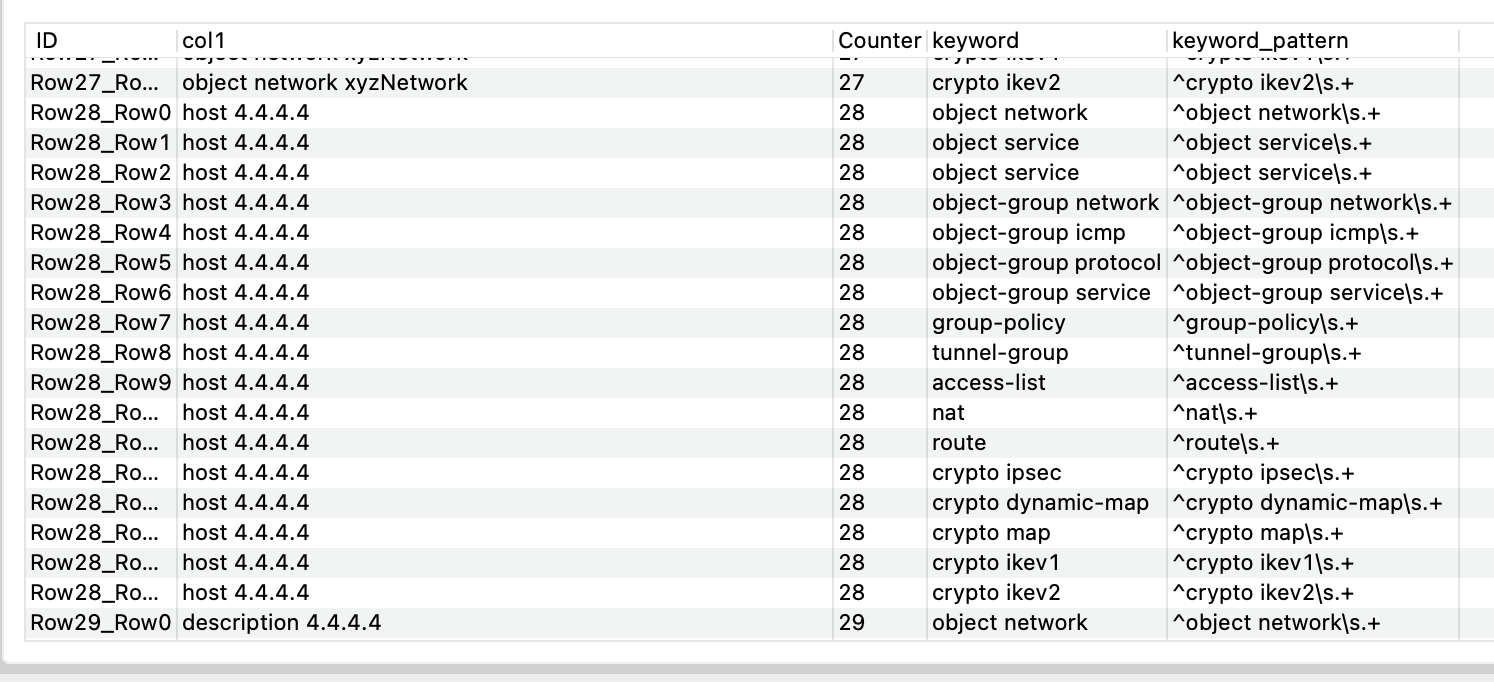
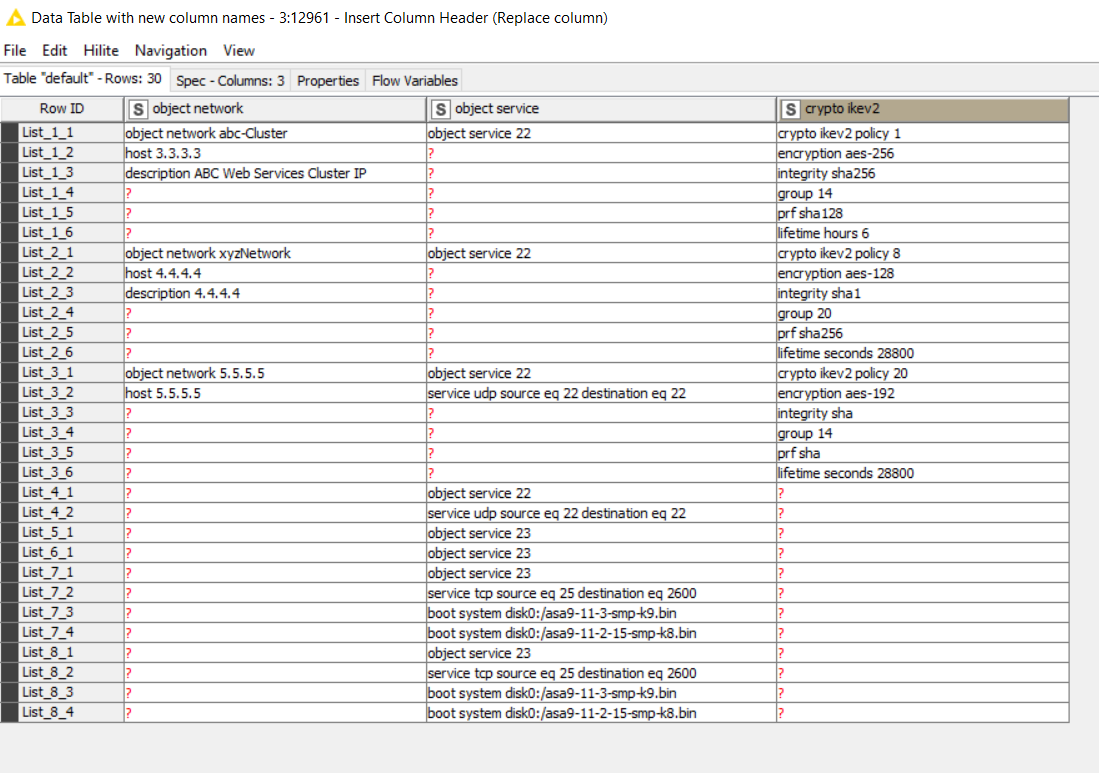
object network xyzNetwork
host 4.4.4.4
description 4.4.4.4
host 4.4.4.4 should only match < object network > right?
At the GroupBy, the column name changed between the original data and my demo so it needs to be reconfigured. That’s why you get the empty table later
If the image you posted was the output of the Cross Joiner (which I think it is), then that is doing exactly what it’s supposed to. It simply “joins” every row to every other row. You will see the total number of rows on the Cross Joiner output is the product of the rows from the two tables. (Hence why it takes up a huge amount of memory if the tables get very large).
There is no “matching” as such at that point. Its job is simply to put every keyword next to every col1 value.
Then the Rule Engine comes along and looks to see in which rows col1** matches keyword_pattern**. It’s the KNIME equivalent of throwing mud at a wall and then seeing what sticks… ![]()
That’s is awesome @takbb
I really appreciate all the time you spent on this and I apologize I haven’t caught the end on the ‘GroupBy’ change. Thanks a lot!
See you next time.
Cheers
J.
No worries, and there is another minor duplication I saw. I was trying to work out why 56 input rows became 58 at the end of the Sorter. It was because you have “object service” twice in the keyword list, so if you remove that it should be right.
@takbb Indeed I had. Took care of it. Thanks for looking out! Cheers.
Hi @jarviscampbell ,
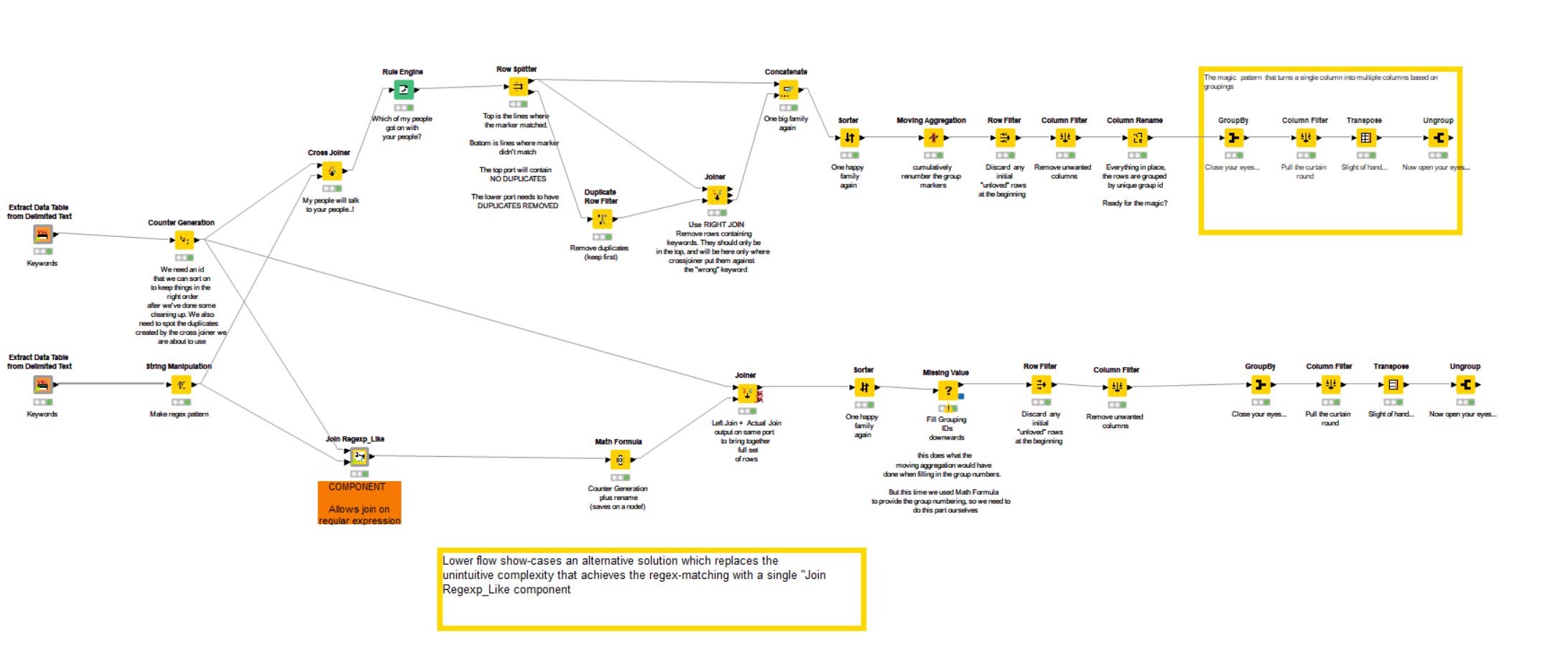
I thought I’d take this opportunity to show-case a new component of mine. One of the less intuitive aspects of the solution for this workflow is the mechanism to join using regex patterns. The standard KNIME joiner nodes do not provide a facility for non-equi-joins (e.g. wildcards, regular expressions and ranges).
After assisting with your workflow, I decided to create a set of components which use the built-in H2 database behind the scenes to help bridge this gap.
The attached shows how the Join Regexp_Like component can simplify that part of the workflow, making it more readable and intuitive.
I have left the old mechanism at the top, and added the new variation at the bottom
GroupBy-alternative with regex join component.knwf (165.1 KB)
There are some other minor changes as a result but hopefully you may find such a component useful in future. You can see the full set in my other post on the subject:
Hi @takbb I will take a look at your next post. However, I think I jumped the gun. I thought you did such a beautiful job displaying ur solution that I got overwhelmed about the first requirement/use case ![]() The solution must group all the keywords under one single column. I should only have around 16ish columns instead of hundreds
The solution must group all the keywords under one single column. I should only have around 16ish columns instead of hundreds ![]() I bet that is an easy fix during the ‘group-mark’ stage, isn’t it?
I bet that is an easy fix during the ‘group-mark’ stage, isn’t it?
Hi @jarviscampbell , I don’t think it would be too difficult, but can you give an example of the output. If it helps, this is my understanding of what you’ve said (using my original simple data with a few additional lines). Is this right?
col1
z1
z2
z3
z4
A
x5
x4
x3
x1
B
x9
x4
x5
C
x2
x3
A
x4
x5
x10
C
x2
B
x5
x3
And your keywords were
A
B
C
Would the expected result be something like this result (does the heading get repeated or do you just want all the “data” lines?:
col1 col2 col3
A B C
x5 x9 x2
x4 x4 x3
x3 B C
x1 x5 x2
A x3
x4
x5
x10
(I might not be able to come back to you right away as I’ll be away from my computer for the rest of the day - yes even I have time away from KNIME ![]() )
)
lol, of course I understand. Whenever you have the chance. But I think that it looks like that @takbb
col1 col2 col3
A B C
x5 x9 x2
x4 x4 x3
x3 B C
x1 x5 x2
A x3
x4
x5
x10
Man @takbb that is awesome, but I must admit, I bit above my level of understanding fully. I do see that we went from 4 nodes to 3, so that did get all composed within a single new component which is great. I see you put enough work on that. Knime should hire an expert like you. ![]() Thank you for your contribution to the community. I am sure a lot of us will benefit from your efforts.
Thank you for your contribution to the community. I am sure a lot of us will benefit from your efforts.
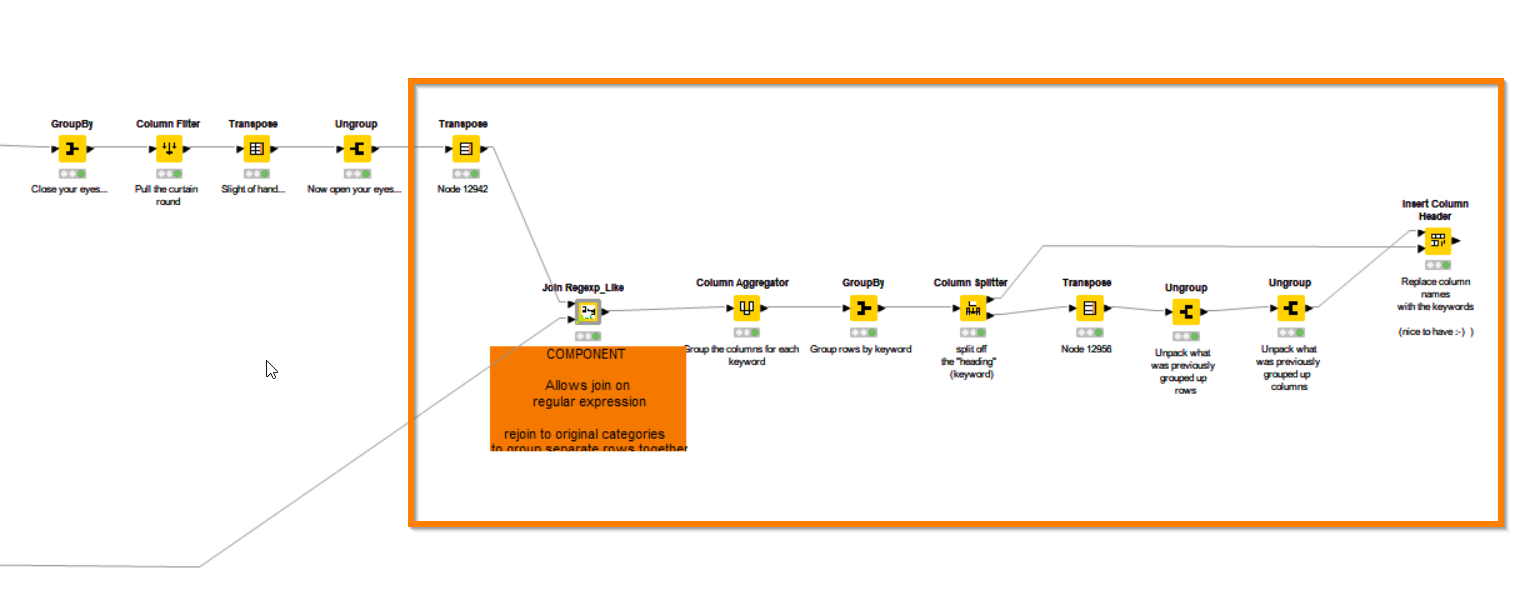
Hopefully this is a step in the right direction…
I just added some more stuff on the end, making use of the joiner regex component.
It currently leaves gaps, which means that a new “grouping” always starts on the same line as other new groupings. This is just the way the method I used ends up doing it. That may be what you are after. If you want it “squashed up” so the blank cells disappear, I’ll have to think about that. There are forum posts on the subject, such as this one, but I haven’t thought this through any further to say if there are alternative approaches:
And now I must dash! ![]()
GroupBy-alternative with regex join component 2.knwf (221.9 KB)
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.