Something that comes up from time to time on the forum is the ability to provide joins between tables where the join isn’t an exact match. For example, the ability to join one table to another based on a date range, wild cards or regular expressions.
There are a couple of general ways of achieving the required results.
One is to use a cross joiner to match all rows with all other rows, and then use a Rule Engine to see which rows actually meet the required condition, and then applying a row filter to keep only those selected by the Rule Engine.
A second option is to make use of a database, such as H2, to temporarily store the contents of both tables, and then make use of the SQL features to perform the query and return the required joined results.
I have previously written a component using python (my PandaSql Join) component which uses python to join two input tables using PandaSql and return the result, which is similar to the H2 option but requires Python to be present and installed.
The trouble with the Cross Joiner method is that for large tables it can result in an excessively large intermediate step (the product of the rows of both tables when all joined with each other).
The trouble with the database method is that it requires the user to spend time adding a load of additional nodes to the workflow, and know some basic sql syntax to achieve the desired result. Possibly their whole reason for using KNIME is to avoid understanding SQL!!
I decided though that this comes up sufficiently often that a component solution was in order, so I have created several “joiner” components which make use of the inbuilt H2 database to facilitate joining using SQL but (mostly) not require SQL Knowledge, and not requiring the manual and laborious addition of multiple nodes to the workflow.
They each do what they say on the tin.
The joiners provide the following functionality:
Join Between: source column BETWEEN values in two lookup columns
Join Like: source column LIKE a wildcard pattern in a lookup column
Join Contains: source column CONTAINS a value in a lookup column (lookup is substring of source)
Join Regexp_Like: source column matches a regular expression pattern in a lookup column
Join Custom Condition: write a sql where clause to join two tables. This is useful for more complex/multiple conditions but this one does require basic sql syntax knowledge, but is good when you cannot achieve the result easily using the other methods.
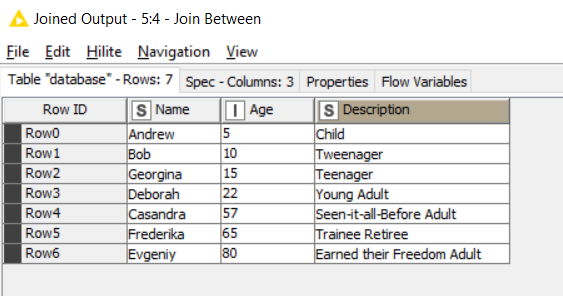
EXAMPLE - JOIN BETWEEN
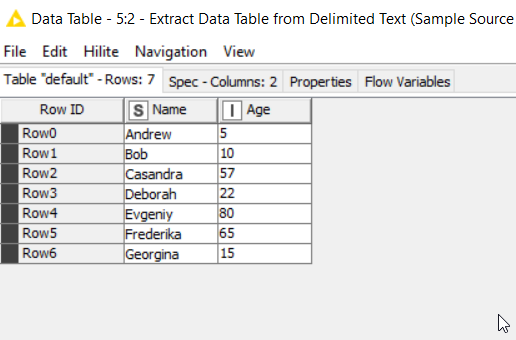
Source Data
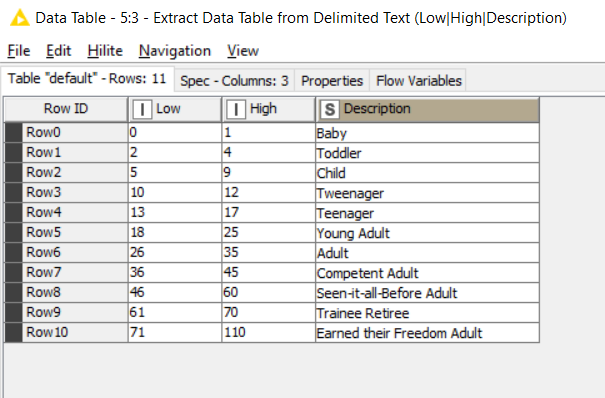
Enrichment / Lookup Data
Join Between

Result
Have a good weekend one and all! ![]()