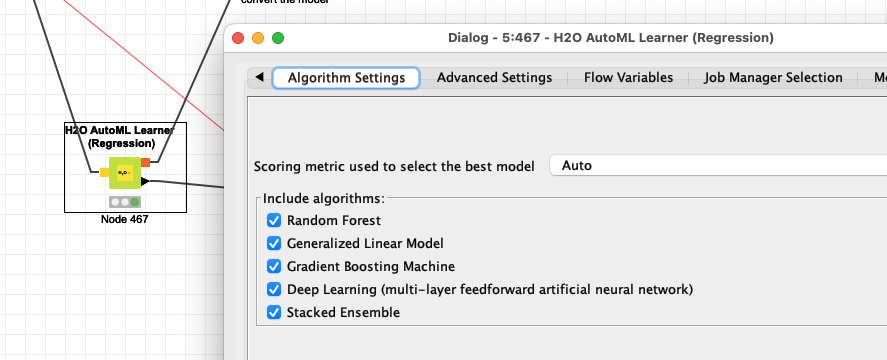
I am generating a number of H2O AutoML Regression models in a loop and write out each model separately as a MOJO type file. I noted that a new model is written approximately every hour (give or take a few seconds), however I have not set a maximum run time as stopping cirteria. This seems to be more than coincidental to me, as the data sets are different for each model.
@evert.homan_scilifelab.se could you explain in more detail what you want to do. The KNIME H2O.ai AutoML nodes would by themselves create several models and try to find an optimal spot. So without changing any additional settings a loop that would run this node several times very likely would come up with basically the same model (minus some minor variations about sampling).
So you might try and change different settings and try them. Also if you want to edit more settings you could try the H2O.ai AutoML with a R or Python wrapper that would give you more access to additional settings.
I don’t think it would make much sense to have additional optimisations loop around a AutoML node since the H2O.ai algorithms themselves would try to find optimal settings and hyper parameters.
If you want to try that yourself you could do this:
use a basic AutoML node for several hours and see what model and settings come out (GBM, GLM, DeepLearning)
then use that sort of model in a KNIME Python node and try a hyper parameter search (hyperparameter tuning for string values - #3 by mlauber71).
Note to self: I have a code somewhere that I wanted to turn into a KNIME workflow …
A comparison of several regression models in one workflow:
I only use a group loop to select different data sets and targets for the models (completely independent data sets from ChEMBL, they are just in one table). I build AutoML models for each target with default settings, exactly as in your image, so no additional parameter optimization is done. I just noted that even though I have not ticked the maximum run time box, it takes almost exact 1 h to build each model I I don’t understand why because some data sets are much larger than others.
@evert.homan_scilifelab.se I think you will have to gain experience with the settings and find an optimal way. Early stopping and time limits are there to prevent th model from running eternally…
Or you try something like 48 hours or 24. so you will have a lot of time but sort of limited. If you run several models depending on the power of your machine you might want to think about parallel jobs or enabling some recovery mechanism.
I did some simple benchmarking. First of all, it is not possible to set the Max run time to zero seconds, the AutoML node does not accept this setting (could this be passed as a variable, in that case which variable?). I used a single data set of 4,985 D2DR ligands with activity data from ChEMBL, described by RDKit descriptors and Morgan fingerprints (expanded bit vector), in total 1065 ‘descriptors’. I then varied the Max. run time in seconds and looked at actual run time, R^2 reported by AutoML, and size of output model (written as MOJO):
set run time | actual run time | R^2 | model size
no max | 3605 sec | 0.96 | 4.9 Mb
30 min | 1807 sec | 0.92 | 2.2 Mb
1 h | 3611 sec | 0.93 |5.9 Mb
2 h | 7202 sec | 0.92 | 24.5 Mb
12 h | 42866 sec | 0.95 | 29.6 Mb
So it seems that the default setting, i.e. without specifying a max run time gives both the best R^2 and a small-size model, and also seem to run for quite precisely 1 h. But maxing the run time to 1 h gives a worse model and larger output file. It’s interesting to note that longer run times primarily result in larger output files without improving R^2.