H2O.ai Automl - a powerful auto-machine-learning framework wrapped with KNIME
It features various models like Random Forest or XGBoost along with Deep Learning. It has wrappers for R and Python but also could be used from KNIME. The results will be written to a folder and the models will be stored in MOJO format to be used in KNIME (as well as on a Big Data cluster via Sparkling Water).
One major parameter to set is the running time the model has to test various models and do some hyperparameter optimization as well. The best model of each round is stored, and some graphics are produced to see the results.
Results are interpreted thru various statistics and model characteristics are stored in an Excel und TXT file as well as in PNG graphics you can easily re-use in presentations and to give your winning models a visual inspection.
Also, you could use the Meta node “Model Quality Regression - Graphics” to evaluate other regression models:
Hexbin Plot
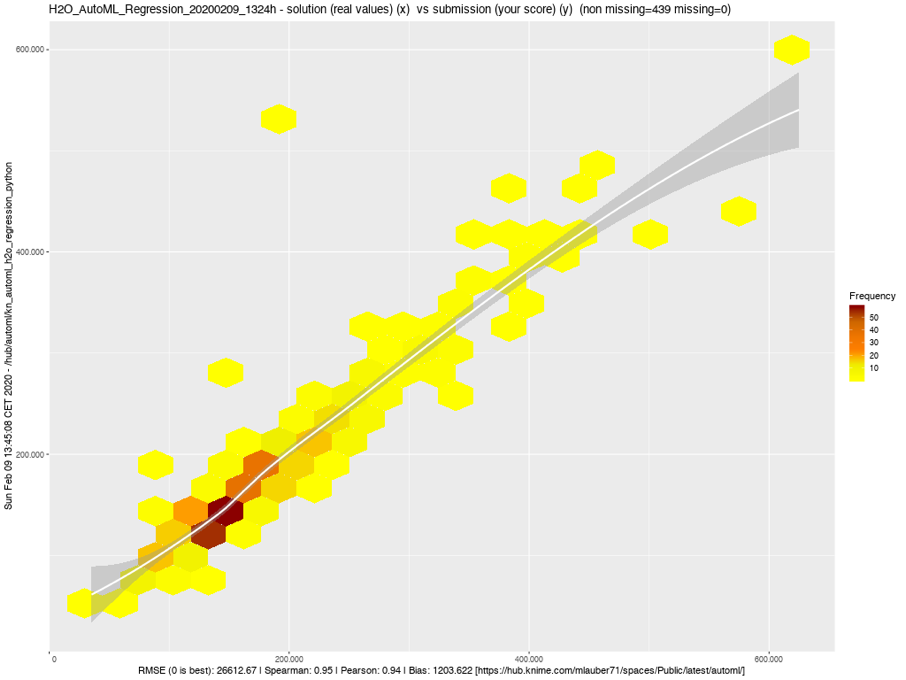
One quick overview of how solution and submission are correlated with an emphasis on the volume of matches – and a general trend. We are able to catch the trend quite good although not the exact numbers.
If this is good very much depends on your business case.
A linear comparison of values

Solution (the truth) as a green line and the submission (the prediction from the model) as a red line plotted against it. You get an idea where the numbers deviate. From the hexbin plot, we have an idea that the affected higher numbers do not represent a large proportion – but the amount of error is significant.
It might be that this special case is an outlier or that the model is way better with cheaper houses.
Parallel Plot

A parallel plot gives another idea of how the numbers stack up against each other on an individual basis. What we can see that as a tendency the submissions seem to be slightly higher. Especially with the higher numbers, there are some notable outliers.
Bland-Altman Plot
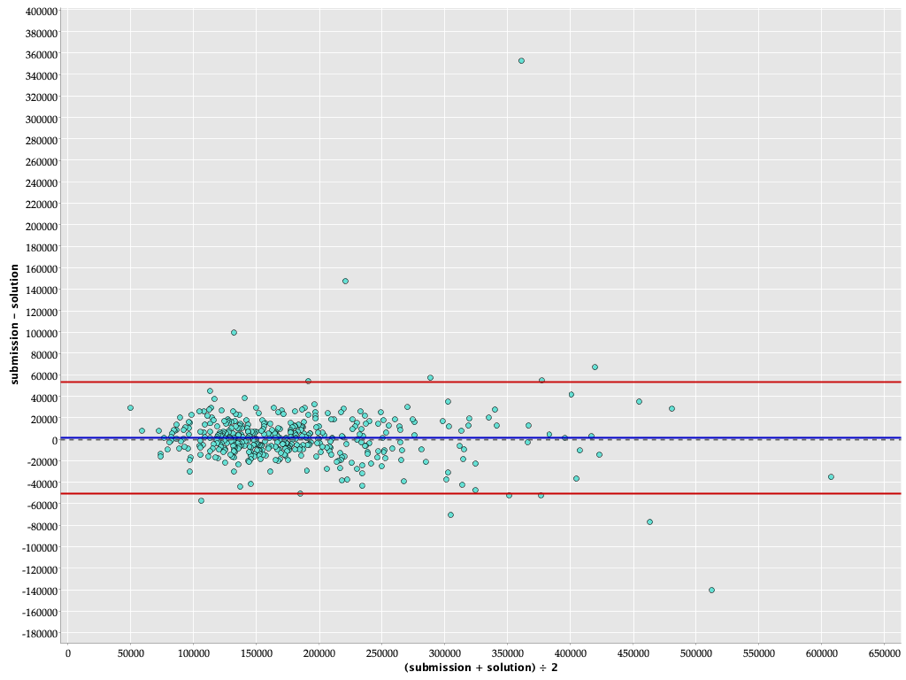
A Bland-Altman Plot is another way of presenting the difference between the predictions (submission) and the truth (solution). Not 100% sure if this will give a large further insight, but I wanted to try the method.
https://en.wikipedia.org/wiki/Bland–Altman_plot
The accompanying Excel file also holds some interesting information
The Leaderboard from the set of models run. On top is the best model H2O.ai found.
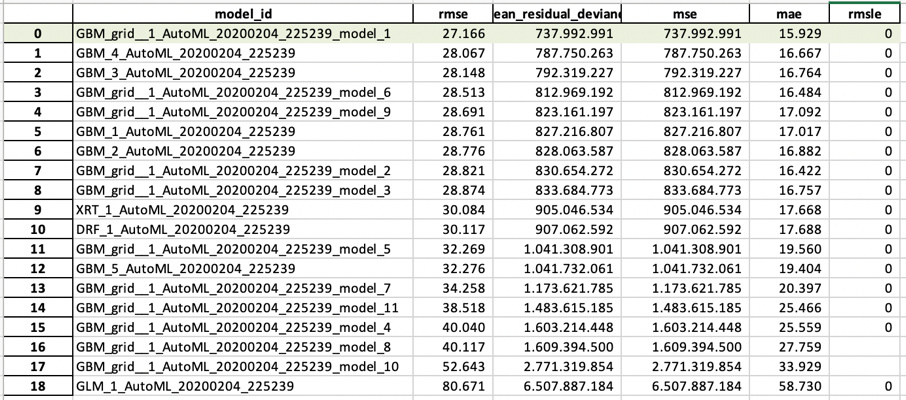
It gives you an idea
- Which types of models were considered, in this case, the leaderboard is stacked with GBM models. The winning one also used Grid search of hyperparameters
- Also, the stretch of the RMSE is quite wide. Since the models only trained 2.5 minutes it would be possible that further training time might result in better models
- In between there as some other models besides GBM if they would appear more often you might also investigate that further
If you are into tweaking, your models further the model summary also gives you the parameters used.
Further information will be stored in the print of the whole model with all parameters, also about the cross-validations done.
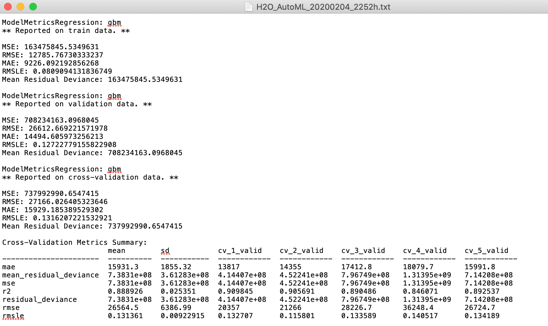
Variable Importance is very important
Then there is the variable importance list. You should study that list carefully. If one variable captures all the importance you might have a leak. And the variables also should make sense.
If you have a very large list and further down, they stop making sense you could cut them off (besides all the data preparation magic you could do with vtreat, featuretools, tsfresh, label encoding and so on). And also, H2O does some modifications.
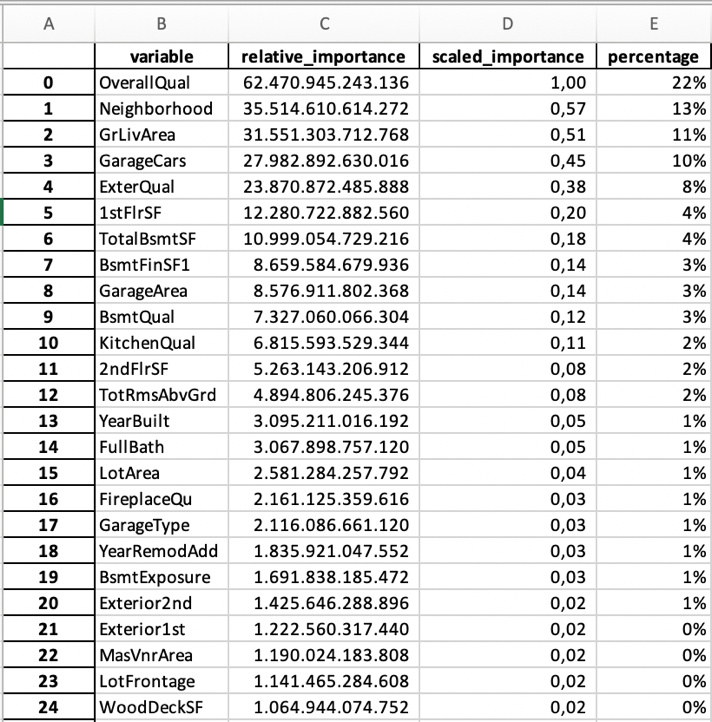
You could use that list to shrink your y variables and re-run the model. The list of variables is also stored in the overall list.
Jupyter notebook
Enclosed in the workflow in the subfolder
/script/ kn_automl_h2o_regression_python.ipynb
there is a walkthrough of Automl in a Jupyter notebook to explore the functions further and if you do not wish to use the wrapper with KNIME