@evert.homan_scilifelab.se could you explain in more detail what you want to do. The KNIME H2O.ai AutoML nodes would by themselves create several models and try to find an optimal spot. So without changing any additional settings a loop that would run this node several times very likely would come up with basically the same model (minus some minor variations about sampling).
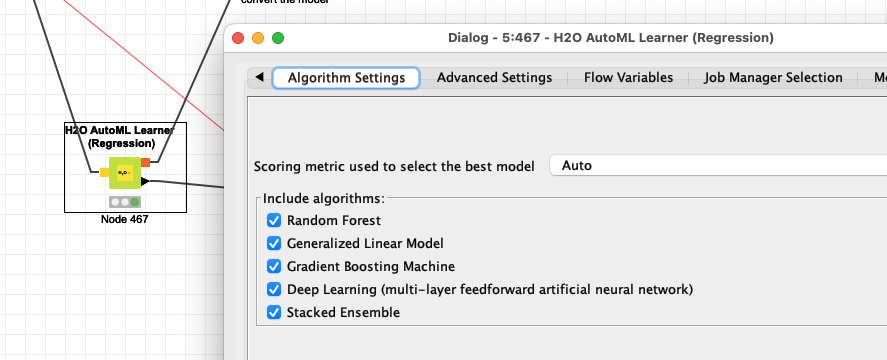
So you might try and change different settings and try them. Also if you want to edit more settings you could try the H2O.ai AutoML with a R or Python wrapper that would give you more access to additional settings.
I don’t think it would make much sense to have additional optimisations loop around a AutoML node since the H2O.ai algorithms themselves would try to find optimal settings and hyper parameters.
If you want to try that yourself you could do this:
- use a basic AutoML node for several hours and see what model and settings come out (GBM, GLM, DeepLearning)
- then use that sort of model in a KNIME Python node and try a hyper parameter search (hyperparameter tuning for string values - #3 by mlauber71).
Note to self: I have a code somewhere that I wanted to turn into a KNIME workflow …
A comparison of several regression models in one workflow: