Hello, very new Knime. We are looking to move away from our text based script files for handling data to something visual & are working through various examples to see how we can handle the different types of jobs we currently have working.
Now for this type I’m not even sure what you call this type of file so found it hard to search for an answer.
Basically each row has a record type indicator as the first field & that indicates what fields are expected for that record.
Types & handling could be:
100: header row. it contains the creation date that I will need for all rows.
200: premise details. I will need the premise id for the next related rows until another 200 row is read.
300: meter details. i will need the meter id for the next related rows until another 300 (or 200) row is read.
400: register read. register id, read date, interval length, read columns (1440/interval length = how many read columns after this there will be.)
500: event record. only appears when there are reading events & has various columns for identifying issues & reasons.
900: footer record. number of premises read, number of register readings
So as an example the file could look like:
100,20220511,FromParty,ToParty
200,321654987,ConfigType,DepotName
300,10005000,SerialNumber,Make,Model
400,A,20220510,144,54,67,89,56,45,64,89,68,48,58
400,B,20220510,144,64,65,65,85,45,61,34,87,84,51
300,100050203,SerialNumber,Make,Model
400,A,20220510,144.56,84,51,56,57,18,85,45,85,15
200,654456654,ConfigType,DepotName
300,100068484,SerialNumber,Make,Model
400,A,20220510,288,554,567,859,566,457
500,Z29,035
900,2,4
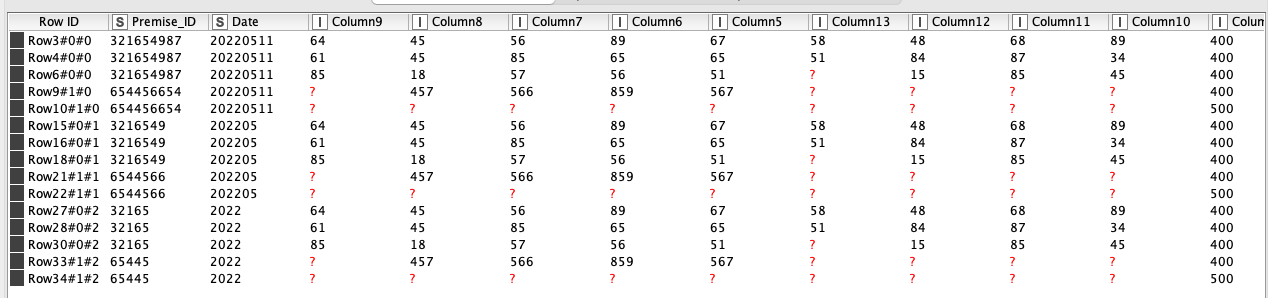
Then I need to put this data into 2 separate tables basically for the 400 & 500 rows with the appropriate data from their related previous rows.
Like these as an example:
Table 400:
PREMISE_ID METER_ID REGISTER_ID READ_DT INTERVAL_LENGTH I01 I02 ... I10 CREATE_DT
321654987 10005000 A 10/05/2022 144 54 67 48 58 11/05/2022
321654987 10005000 B 10/05/2022 144 64 65 84 51 11/05/2022
321654987 100050203 A 10/05/2022 144 56 84 85 15 11/05/2022
654456654 100068484 A 10/05/2022 288 554 567 null null 11/05/2022
and table 500:
PREMISE_ID METER_ID REGISTER_ID READ_DT ERROR_CD REASON_CD
654456654 100068484 A 10/05/2022 Z29 `035
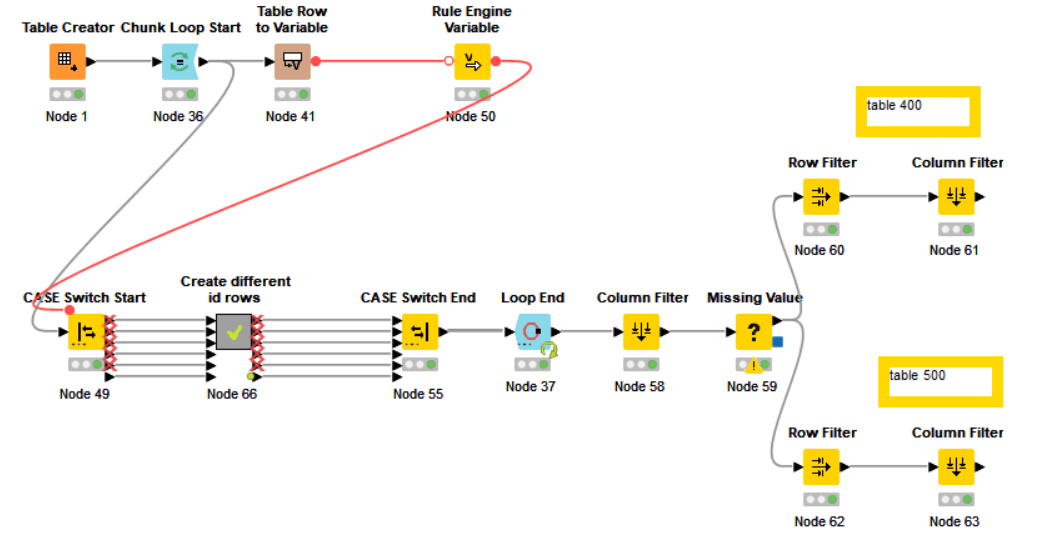
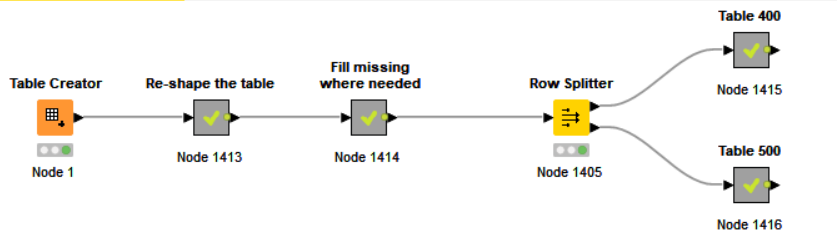
I have been trying to find how to perform the above. I believe I would to move through a file sequentially storing the various data from the 100, 200, & 300 into variables. Then attach it to the 400 & 500 rows in the correct order. But I can’t work out which nodes I would achieve this with. It seems all the “splitter” types would handle each row by its type but there wouldn’t be a relationship to the correct other rows.
Can somebody please assist in pointing me in the right direction.
Cheers
Adrian