Dear friends I have a problem,
I want to predict on an unbalanced dataset using random forest algorithm. I built the model using the smote node. But I also want to use cross validation. I reserved 70% for training and 30% for testing, but when I use the link I got from training, I get an error.
Could you please take a look at where could be the problem?
Thank you. Best regards.
1 Like
Hi @UgurErcan
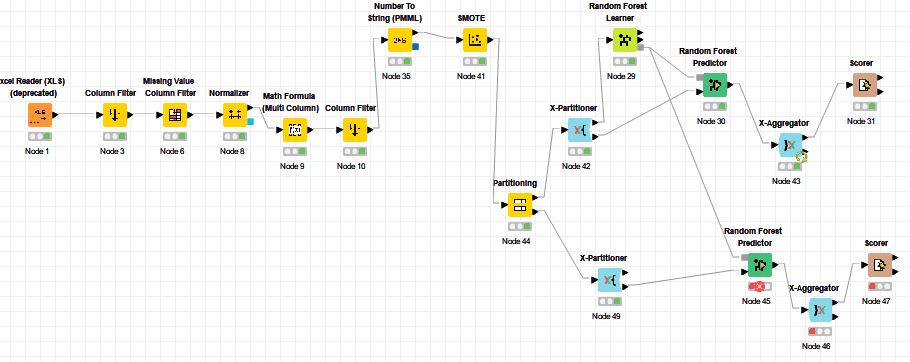
This is a quick answer to your question, just to warn you that it is not possible to have a connexion accross two different loops in the way you are doing it here in your workflow, i.e. from the “Random Forest Learner” node to the “Random Forest Predictor” node from one loop to another different loop. Even if it were possible, this would not solve your problem.
Is it possible for you to share your workflow with its data? It would be easier for us to help you if so.
Looking forward to your reply.
Best
Ael
4 Likes
Thank you aworker,
I send you, excel and workflow.
Thank you. Best.
KNIME_project.knwf (40.0 KB) knime.xlsx (19.7 KB)
[quote=“UgurErcan, post:3, topic:33756”]
Thank you aworker,
I send you, excel and workflow.
Thank you. Best.
knime.xlsx (19.7 KB) KNIME_project.knwf (40.0 KB)
1 Like
Where to start?
I suggest you first look at the examples and the example server so that you understand how the cross validation loop actually works. Other option is the cross-validation meta node:
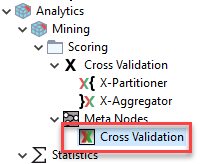
These are still simplified but get the point across. You only need 1 loop. Albeit I do not really like the X-aggregator node. It is a bit pointless.
Second point, SMOTE must always only be used for training data and NEVER test data.. Never, ever, ever no exception. Besides that I would avoid it anyway and choose an logarithm that can better deal with class imbalance, like xgboost.
Third point, you must always only normalize on the training data and use the Normalizer (Apply) node for the test data. Else you have data leakage.
Also unclear what the whole thing with the Math formula node is supposed to do. You simply need to convert your class column to a string.
Find attached an improved version. But please, please educate yourself so that you understand the points made. Just following very general guidance from the internet is not a good idea and if this is for real-world use, it will cost your job.
KNIME_project.knwf (160.8 KB)
For example what this improved version is missing and why you should absolutely not use it “as-is”, is that most of your variables aren’t numeric but categorical. Therefore you should one-hot encode them. It also means they can not be normalized the way it’s done in the workflow and also can’t be used for SMOTE. SMOTE works distance-based. Categorical variables don’t always have a clear distance.
So again, please read up on basic “ML theory” or “statistics” and I mean very basic. What is train-test split? What is cross-validation? What is one-hot encoding? Types of features (continuous, discrete categorical,…) distance measures,…
7 Likes
Dear @UgurErcan
Sorry I’m late to answer your question but @kienerj did a great job answering it. There are plenty of wise and useful hints in his message to take them positively and learn from it further.
Please be willing to post new questions if you need extra help. We will be willing to help you.
Good luck and all the best,
Ael
2 Likes
@kienerj Could you please provide us with a good paper reference mathematically proving that “plain” xgboost is not affected by class imbalance ? Not experimental please. Or are you talking of Class Weighted XGBoost or Cost-Sensitive XGBoost ?
Thanks,
Ael
1 Like
Dear @kienerj what you say is very valuable. Thank you so much. But I need to set up this model urgently. I’m trying but something’s wrong again. By the way, do I need to use Meta Node-Cross Validation for cross validation instead of x-partitioner?
Could you please provide us with a good paper reference mathematically proving that “plain” xgboost is not affected by class imbalance ?
I never said “not affected”, I said less impacted which when nitpicking is admittedly wrong and you answered what I meant. You can provide corrections with class weights (or instance weights but not in KNIME). Of course this has limits but for OPs split of about 80/20 it should work assuming there is any signal in the data (which I doubt + the fact it’s simply not enough data).
@kienerj @aworker
KNIME_project.knwf (40.0 KB)
What I actually want is to stabilize an unbalanced dataset and make predictions.
What I actually want is to stabilize an unbalanced dataset and make predictions.
You said
This was missleading but now it is clear that is not XGBoost (which has no mechanism to deal with imbalance classes) you were talking about but improved versions as for instance Weighted XGBoost or Cost-Sensitive XGBoost.
I tried to do everything you said. But I didn’t know where to put the Normalizer (Apply)? can you have a look at the model?
KNIME_project.knwf (40.0 KB)
can you have a look at the model? please. Thanks a lot.
KNIME_project.knwf (40.0 KB)
Hi @UgurErcan
Please find a possible solution (not the only possible though) to your classification problem:
20210615 Help Me Random Forest.knwf (324.6 KB)
Essentially, what this workflow is doing is testing a Random Forest (RF) based on a 10 fold Cross Validation Test. Since your data is strongly imbalance, you need to deal with this problem. In this implementation, I’m balancing the training set inside the CV loop, so that the RF is less affected by data imbalance. Still, since your class (1) is very small, the training set lacks of enough information to be a good predictive model, but at least data balancing makes it a bit more resilient. I you do not use this data balancing, your model will be strongly biased towards the majority class, which is much less the case here. Still balancing data doesn’t fully solves the problem because of lack of enough data for the class (1) as I said.
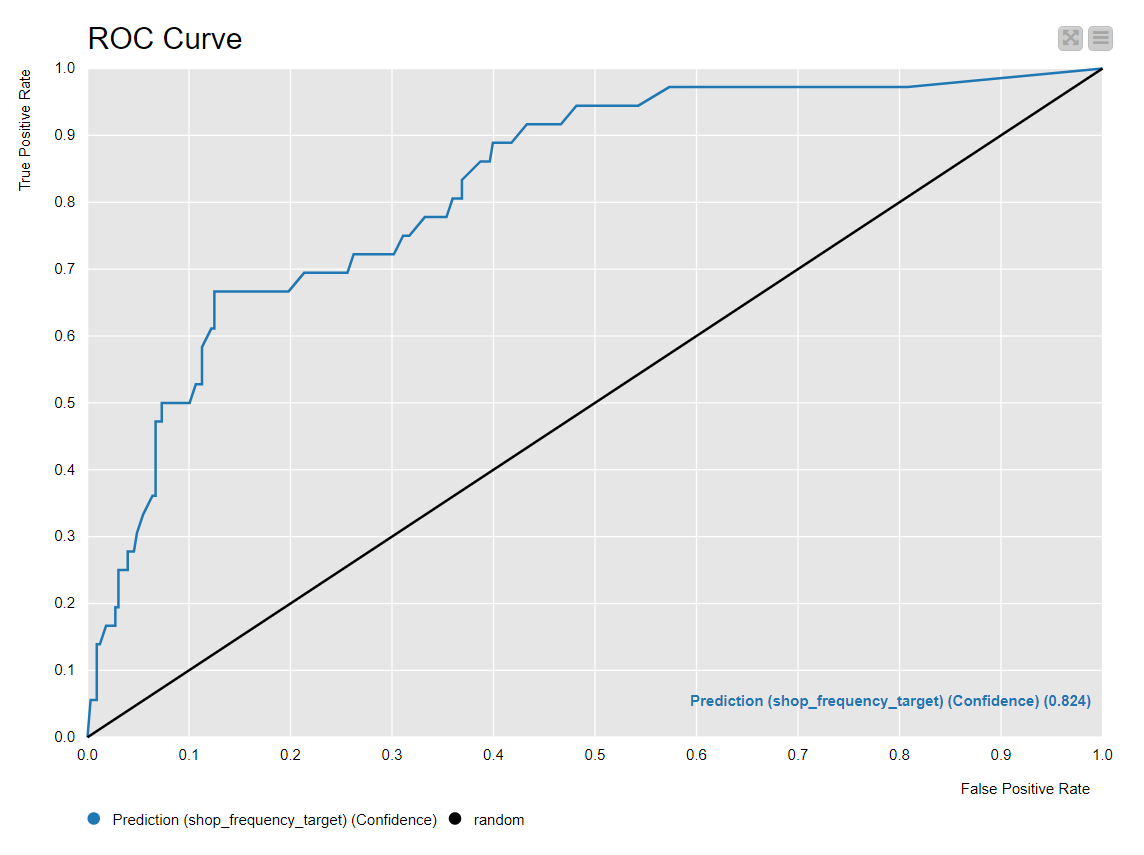
Here you have the resulting statistics from the 10 fold CV:
As you may notice, global Accuracy is not bad, but the model is not achieving good results on the minority class (1). I have calculated too the ROC Area Under the Curve based on Prediction Confidence from the RF, which is an statistics estimator unbiased with respect to test set class imbalance. This should give you an extra idea of the model performance:
If you are not familiar with this statistics estimator, please have a look at the following link about ROC AUC and other statistic estimators.
Obviously this is a starting point workflow which definitely can be improved. Please let me know if you have any questions about it.
Hope this helps,
Ael
2 Likes
Actually the Dataset is big enough. I only sent a small part of it for transfer purposes. Of about 10000 data, 1600 take the value 1, while the rest take the value 0. thank you so much. I downloaded and set up the model and tried it. But I want to have 2 classes here, test and training. I think you used a module called Balance Training instead of SMOTE.
This component called Balance is just for the training. You need to keep it as it is.
Perfect, good news  !
!
However, be aware that in your initial training set you labelled your classes 1 & 2. Please keep this numbering because my solution is dependent on it, so please rename your classes to 1 & 2. Otherwise the balancing will not work.
I guess you mean two sets : training and testing. No problem, I’ll post a Training-Test sets version too.
But before I post a new version, would you mind please to load and run all your data in the workflow I sent you and upload here the Statistics you obtain on it ? I am curious to know if they are consistent. Is this ok with you, to upload here the 10 fold CV results snapshot and the ROC AUC snapshot as I did here but with your full 10000 data samples? I guess you just need to replace the excel file and make sure that the classes are numbered in the same way (1) and (2) 
Thanks & regards,
Ael
@aworker You are right, sorry. I wrote wrong, it will be 1 and 2. When I apply the second data set, the was a problem (in Balance Training Set node). data_latest.xlsx (320.5 KB)
@UgurErcan no problem at all.
Please find a new version which contains both
- a 10 Fold CV version and
- a 80 % Training & 20 % Test sets version.
Results are consistent between each other. Please be aware that given this data, most probably your model won’t be able to predict correctly more than 7 over 10 times to explain things in plain english. Is this good enough for you ?
The updated workflow is the following:
20210615 Help Me Random Forest 10 Fold CV and 80 Training versus 20 Test sets.knwf (2.4 MB)
Please have a look at it, go over the configuration of all the nodes to understand how it works and let me know tomorrow if you have any further questions 
Hope this helps 
Best
Ael
1 Like
I saw some nodes for the first time 
-
I could not find the gray node in my knime. doing balancing
-
I assume x partititoner will be used together with x aggregator. I think you solved this with loop node?
-
In the solution with x aggregator, I think you gave the test and training sets only as scorers. You didn’t add a separate predictor to the test, why?
-
Can we get train results as confusion matrix in below solution?
1 Like