Why put the scorer outside the loop and score over all folds? Doesn’t make sense in my opinion because part of CV is to also to see the variance between models.If it is big, then it’s harder to make any conclusion about how good your final model will actually be.
1 Like
Hi @UgurErcan
Thanks for your kind and prompt questions and glad you could follow the workflow I uploaded.
Concerning the questions:
1.
It is not a node from the “Node Depository” but a component. Please have a look at Components Guide to learn how to build components or metanodes. They are the equivalent of functions or procedures in classic code programming. If you double right-clic while holding the Ctrl key, you could get into and see how it was built.
Yes, indeed. Good you noticed that. The classic way of using the X-partitioner is along the X-Aggregator, but this shows that you can mix in KNIME different starting and ending loop nodes depending of your final aim. I could have used an X-Aggregator though ![]()
Sorry, I may be missing something but I do not understand your question. In my last workflow, I’m so far gathering the results of all the 10-Fold CV test sets and calculating the global average performance of the model. I’m not calculating the10-Fold CV training set model performance, if this is what you mean.
In the last version I uploaded, you have the 80/20 % CV version which is calculating the global model performance on the 20% test set as well.
Yes, you would just need to duplicate the part of the workflow “below” (the 80/20 % CV version) from the “random forrest predictor” (RFP) and connect the 1st output of the Partition node to this duplicate from the RFP node.
Please be aware that is good for completness to calculate the performance of a model on its training set, but the Test Set statistics are the one that should be considered in fine for model performance evaluation. I could develop this more but I try to stay simple at this stage of our discussion.
Before going further, could you please give a bit of context about your project if possible ? Is this an academic or a company project and what will be the use for instance ?
Please feel free to ask more questions if needed. I’ll be glad to kindly reply.
Best regards,
Ael
1 Like
Hi,
maybe I am missing something here. Your loop end seems to capture all outputs for all 10 iterations together. Your X Partitioner is set to draw randomly. So I would assume the scorer at the end is not scoring the right prediction sample to the right target value.
Could you please give an update on that?
And do you know whether KNIME support class weights?
Thanks
Actually, that’s what I thought. First we will divide the dataset with partition. Then, we will make x partitioner with the train part and do 10 cross validation. Then we will test with the remaining test data from the partition we received from the train. Thank you for your help, i learn many different things.
1 Like
Sorry for writing late today. Because there were exams. This is going to be an article, I’m actually trying to do it. I am an academician. What is your job?
Being late to the party I could offer these points
- you might want to employ H2O.ai models included in knime at least for benchmarking. I wrote an article about how to use the auto-machine learning package (always to be taken with a grain of salt I know) H2O.ai AutoML in KNIME for classification problems
- then you could try and use automatic feature engineering techniques like vtreat or featuretools and see what that could do (keep in mind to separate test and training) H2O.ai AutoML (wrapped with R) with vtreat data preparation in KNIME for classification problems (with R vtreat) – KNIME Hub
- then you could try and employ a technique like label encoding (terms and conditions apply and you should be careful what categorical variables you would transform H2O.ai AutoML in KNIME for classification problems - #11 by mlauber71
Then like other KNIMEs suggested it does make sense to read about machine learning in general and avoid pitfalls.
If you have to deal with (highly) imbalanced data you might want to read the links about that in my collection.
It is although important to keep in mind what your data says and what business problem you want to solve and if your data will be able to say something about that - preferably in a reproducible way.
2 Likes
The X Partitioner is set to “draw randomly” but it does a random sampling -without replacement- which insures that all the samples are eventually sampled and none is taken twice. If you add a joiner as shown here below to my last uploaded workflow, you will see that this is the case and matches all the samples with an inner join.
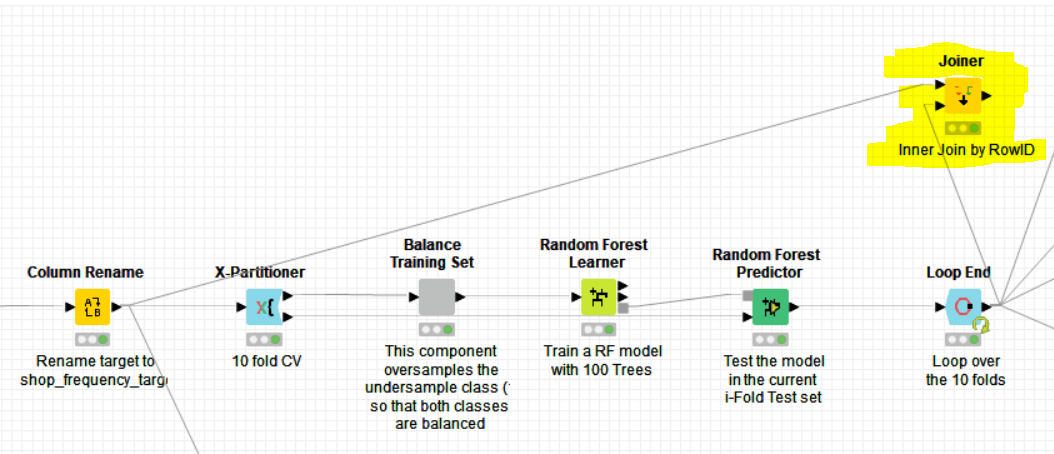
Besides this, the “loop end” configuration is set so that all the ROW ID should be unique, otherwise stops, as shown below. This can hence only work if the previous sampling is done by the X-Partitioner without replacement and all the samples are eventually drawn without duplicates:
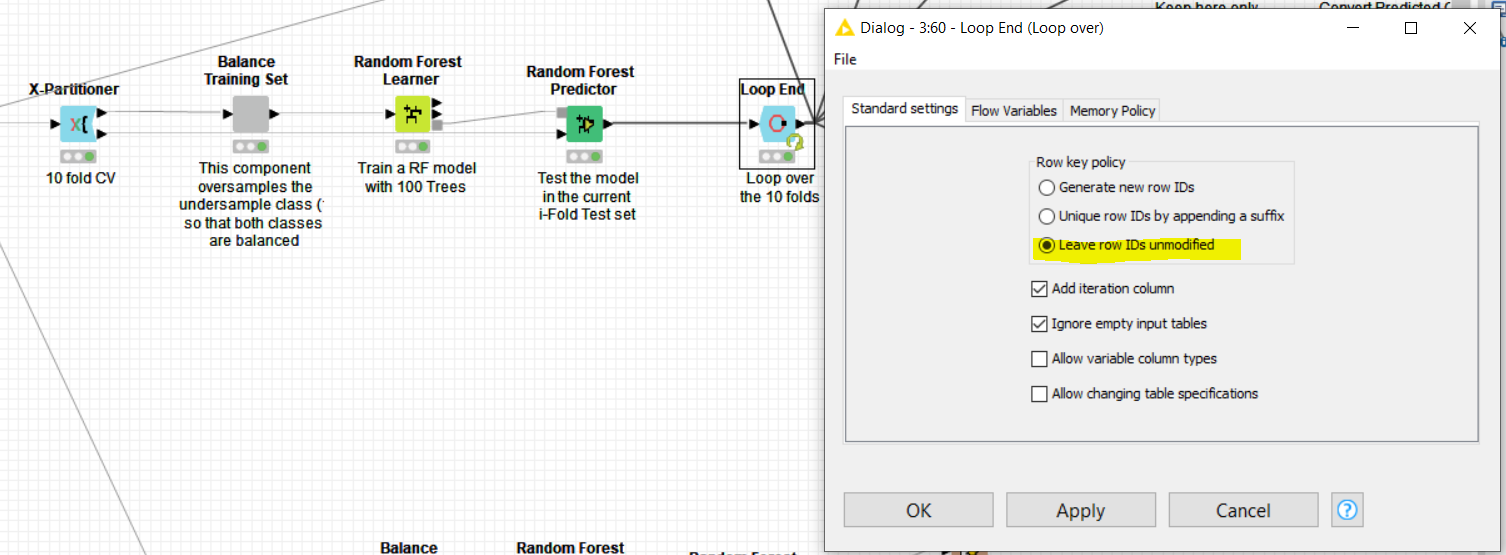
Hope this helps.
Best
Ael
Hi @UgurErcan
Thanks for your last answer. Is it possible to contact you by email ? If so, please let me know and I’ll get in touch.
Best,
Ael
1 Like
Hi @aworker Of course with pleasure,
1 Like
OK thanks
the workflow I downloaded had no joiner node so I was missing that
@aworker @Daniel_Weikert @mlauber71 @kienerj
Actually, I have another question. I want to predict a continuous variable according to various criteria (continuous, ordinal, nomina, binary, etc.). For this, I set up a SVM and ANN model, but MAPE values do not go below 35%. What would you recommend for this? XGBOOST or?
@aworker your workflow is working properly. Thank you.
@aworker @kienerj Hi again I’m busy nowadays. So sorry. Will cross validation be in training or testing?
If you want to predict numeric variables you might take a look at regression part of the machine learning collection
This article deals with statistics when you want to predict numeric values:
1 Like
Thanks for your collection. Is there a need to convert the outputs to number before apply a scorer node? (Used H2O for the famous adults dataset income >50k with Random Forest without converting the target “>50k” to number before training to get a feeling).
1 Like
@Daniel_Weikert for the regression example I use a house price dataset not the census income one. Also to see how good you model is you could use a numeric scorer.
1 Like
Yes but this implies to covert it to numer first instead of having a strin “>50k” and “<=50k”.
I was just wondering whether there is a scorer node to test accuracy based on strings
br
1 Like
Well you could evaluate a binary target (1/0, TRUE/FALSE) with the methods mentioned in the first article about auto-machine learning. If you have several strings you could try and use evaluation methods like LogLoss to see what a target with A, B, C would be like.
Or you might want to elaborate on what your question is 
1 Like
Thanks,
not necessary, normally I would use some kind of encoding Labelencoder or one hot encoding for the target.
Here I just wanted to see whether I could save some time ( with something like H2O Binomial Scorer)
br
1 Like
I do not see the point why converting a categorical target into a numeric one would be beneficial except in maybe very special cases, one idea could be that you would have an aggregation like % of sales in a region where you might convert single 1/0 targets into a percentage of success in an item (region) - but you might loose the individual information of single (in this case) customers when aggregation the signals also (average, median, standard deviation, skewness, ….). I would recommend for a start to use just the target.
Another thing is the label or category encoding of string variables. In my collection there is the example of label encoding (you have to be careful with that) and also special encoding with vtreat. I have a workflow using Dictionary or Hash encoding with the help of Python. I will upload that at some point.
You could always try to use some dimension reduction techniques on your training data and see how that goes. I have not yet used H2O PCA or Autoencoding but that might also be an option.
2 Likes