I’m trying to parse a couple thousand text files into a data table format. I can figure out how to have it process all the text files, I just need help with the formatting. I’ve gotten this to work using about 40 nodes, but there has to be a smarter way to do it than I have. I’m still relatively new to KNIME, so any help would be much appreciated. Please see attached: I want Example to end up in the Template format.
If you could even just tell me how I could have Example pivoted by the line breaks into these columns (with everything underneath staying as a row until the next line break), that’d be a huge help:
SOURCE|GENERATION|DURATION|TRACKS|MD5 CHECKSUMS|etc
Here I classified the sections of the file, while assuming the band is always in row0, date in row1 ,etc. I’d guess that the TRACKS and the MD CHECKSUMS are of variable length for each file.
If this is the case it will allow for some shortcuts, like certain hardcoding. Or not off course
I have the desired output with 16 nodes, but might require some tweaks depending on the abovementioned.
You hit the nail on the head: only the # of tracks and MD5 checksums are going to be variable # of rows.
All of the other fields are the same from file to file (although they may vary in length).
@siperwrx I think you will need some nodes and you might have to show more details about what could change and how.
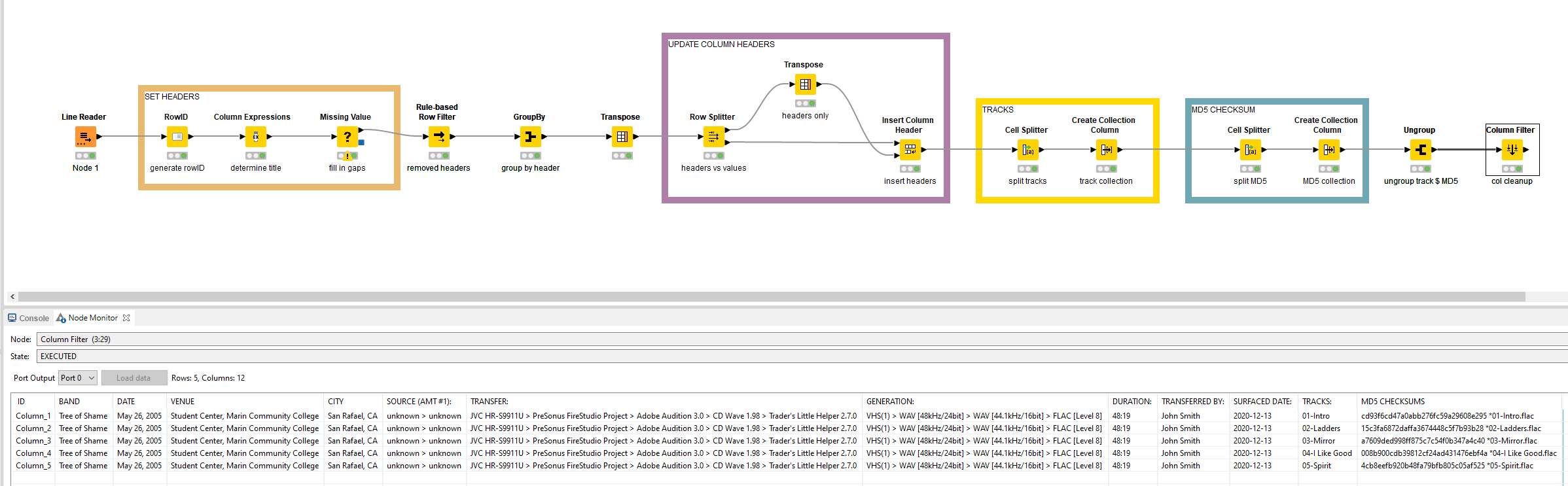
Most likely you will have to identify blocks of data and then transpose them (or not depending on the type). Here is a somewhat similar example to illustrate.
This is an illustration how to deal with blocks of data that then could be handled in different ways
Best to provide more examples that would cover the cases that might occur. I might have a look at the data later.
Below is what I had drafted as a way to approach it. Disclaimer: it only handles a single file right now, the one you provided. It will need more work to be able to process a bunch of files, but there are plenty of references out there on how to do that.
The nodes herein are pretty straightforward in their configuration without a lot of customization so I’d recommend just taking a look at this on how the data progresses. It’s visually divided into several sections.
Only noteworthy item in there is that I opt to find the headers via a Column Expression that looks for certain terms via the RegexMatcher function. Like mentioned before, this works well when you are sure that those will always be in there. For safety, I include a wildcard at the end in case small variations are used.
if ((regexMatcher(column("Column"),("SOURCE.*|TRANSFERRED BY.*|TRANSFER.*|GENERATION.*|DURATION.*|TRACKS.*|MD5 CHECKSUMS.*|SURFACED DATE.*"))) == true) {
column("Column")
}
Hey ArjenEX,
Quick question: if the Column headers in the text file are all there, but they’re in the incorrect order. What modifications would I have to make in order for them to still be parsed correctly?
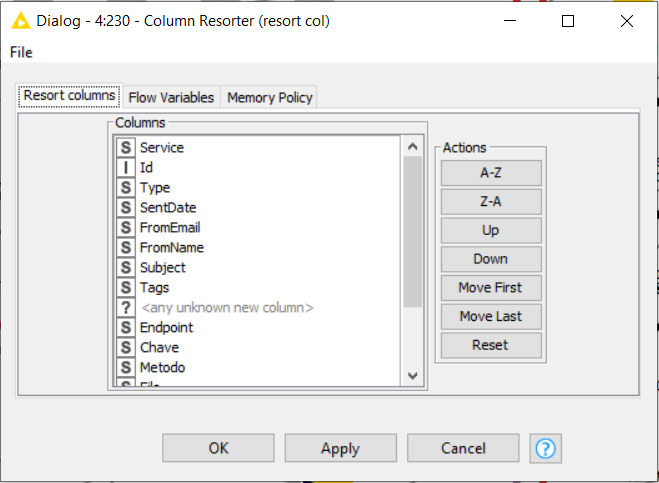
I believe that you need to reorder the columns to put at the same format to be easier to manipulate… you can use the node Columns resorter to set the correct formation and then, continue with the transformation…
As an example, you have the same columns but need to adjust it, I found this solution… the result will be the save as you wish.
In it’s most basic form, the Column Resorter is the way to go like @denisfi mentioned.
For more complex matters, you could opt to make it flow variable controlled by parsing a string list to the Column Resorter. It’s basically whenever the column order is determined somewhere based on a dynamic input. An example would be to sort the columns alphabetically, from high to low, etc.