Building off my last thread, needing training with the platform, I was hoping someone could help me with the issue I am currently having.
I have data set of 3 million data point, broken into 12 or so csv files, i have not had issues loading up individual files and getting basic info out of them, but what I need to do i combine all 12 files to make one big file and pull a conclusion from there.
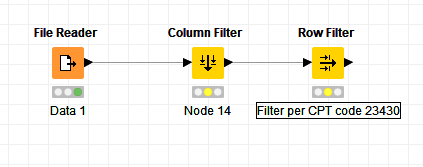
So far, I have done the attached workflow one at a time.
Again, i want to combine all the data and do one column filter node and one-row filter node to look at the whole data set. I was thinking the joiner node was the way to go, but I cannot seem to get this to work.
In doing so, I am likely showing my “greenness” as it relates to the platform.
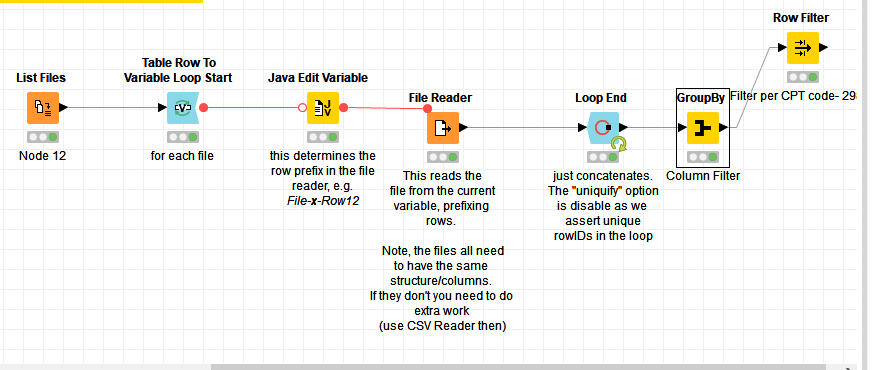
Thanks a million! This appears to have worked. However, I need to filter the one combined table and appear to be having issues.
After combining all the data, there is roughly 2.7 million data points. Yet, I do not think the group by node is reading all 2.7 million points. Is there a setting I need to look at to make sure the group by node is filtering thru all the points and not just one file? In fact, I know it is not as I have run test where I only hook up one file reader to the group by node and am getting the same amount of matches as the when all 12 points are combined
Attached is my current workflow. Any help would be greatly appreciated!
Okay, forgive me for being naive on this, i need the training class i’m going to do to get here in a hurry
I get that loop end is looking thru all combining all the data, when I start filtering, it is does not seem like the filtered table that is produced is looking at all 12 files. Only one?
Can you give me insight on why this might be, I can attach screen grabs if need be.
Ah. That might have been what was going on for the issue, is that I was using group by and not column filter!!
Regarding your suggestion to move the column filter, I am not sure this will speed things up because I will be changing that criterium often so I will need to run thru all 12 files every time I change something. Am I wrong?
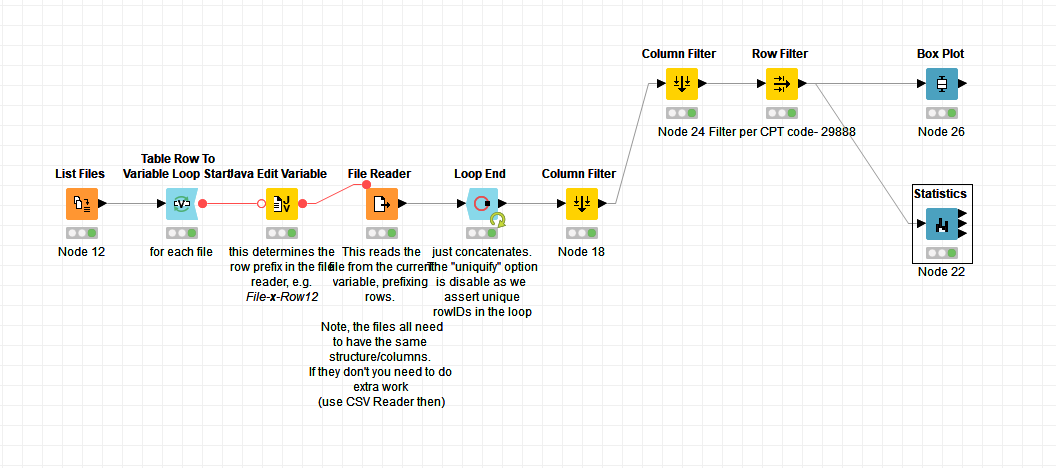
Attached is a screen grab of where I am at currently, it is doing what I need it do for now! One Column filter brings it down from ~170 columns to 10 or so that we might need. The other Column filter narrows it down to 2, which the stats are based on.
Now, my task is to figure out or to remove outliers, I just want the middle 50% of the data for the statistics, not the the the bottom and top quartile. Any easy suggestions for this?