@DAmei you could use the slider to set a value between 0 and 100 - the lower the more strict the definition of a duplicate gets. In your example data there is a seeming identical value while the name is very long in the field. You will have to experiment with the settings.
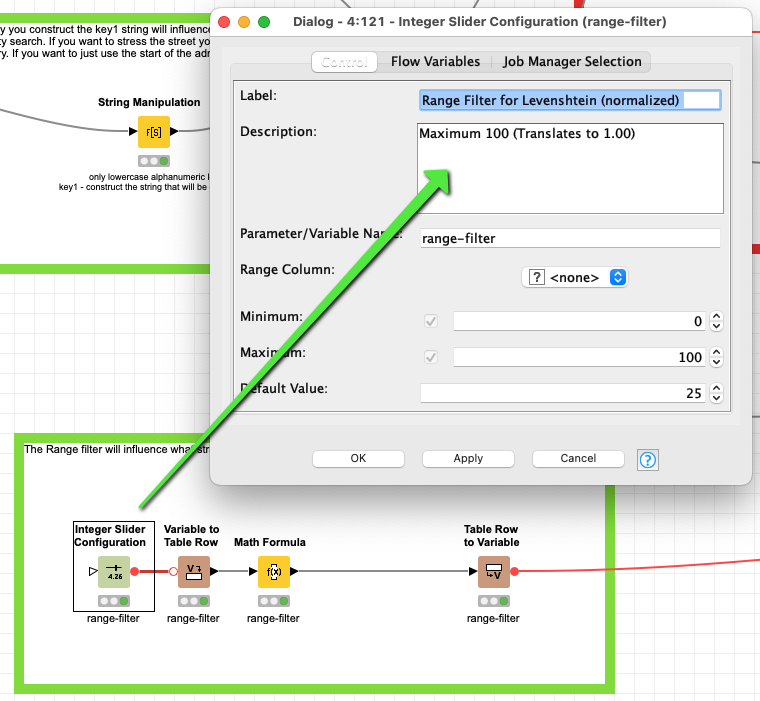
And also you might think about limiting the number of characters you would use to construct the company name. If you want to stress the importance of a component you could use that a few times, to give it more weight.
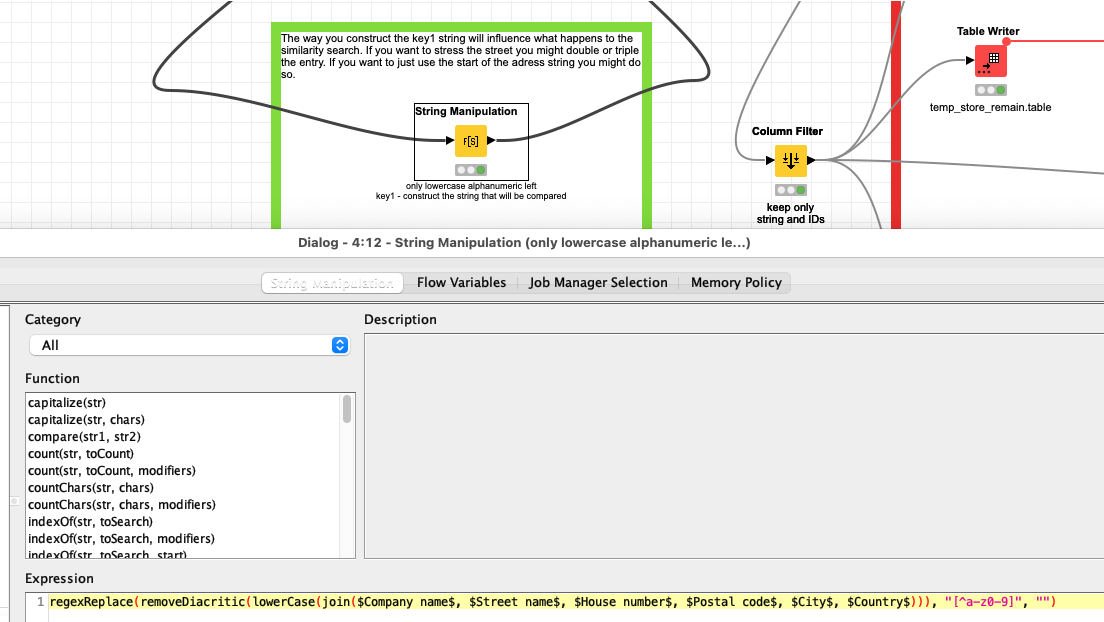
These would be examples to be shorten the names if you want to have them as duplicates.
