I am hoping you can assist me in determining whether my model is overfitting. My model’s accuracy is more than 85%, but when I use new data, the accuracy drops to less than 70%. I have seen suggestions about using a loop, but I am not sure why or how to implement it. If anyone has any answers, can you please explain why and how to do it?
thanks all, any help will be helpful.
It would be helpful if you provided the model you’re using and some details like how the data is partitioned, how balanced is the data (if applicable), etc.
hi refeigel, thank you for taking the time to help me
I will try to upload the workflow. However the size of the data is large, and I do not know if it will be accepted.
But can you help me how to know if the model has overfitting because I have to learn it for the future?
@mohammad_alqoqa maybe the original data is somewhere on the internet or on Kaggle and you can link in addition to providing your workflow. Or you can use a sample to see the configurations.
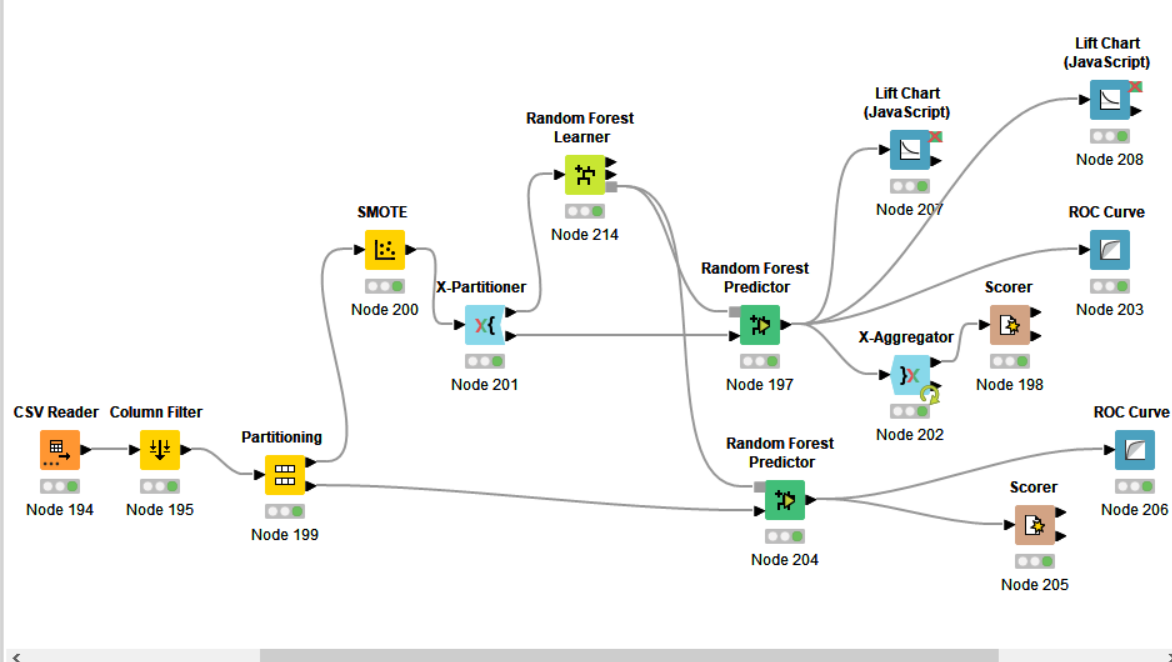
I’'m not an expert on this so hopefully @mlauber71 can weigh in. I’m curious why you’re using SMOTE since your data is not very unbalanced. You’ve got the SMOTE node before the X-Partitioning node which may cause overfitting. From everything I’ve read you should use SMOTE only on the training data.
When I changed the location of SMOTE as you told me, the result became 70% for the test data and less than that for the new data.
When I deleted it there was no change.
Note: The reason I use SMOTE is to increase the size of the training data.
Are there any suggestions? So that I don’t forget the main reason for OVERFITTING, is there a way to discover it?
you leave out several variables from the dataset. I assume this is a deliberate decision
also when you split the data you do not set a seed so the splits might not be exactly reproducible
to prevent overfitting in Random Forests (or other tree based algorithms) two parameters to check are the allowed depth of the tree, maybe limit that to 6 or 8 or try a parameter optimization. Also you might try to enforce a minimum number of values that must be there in a node
also you can try increasing the number of rounds you allow maybe try 2000 or something
You can also try other methods also with data preparation (think vtreat although they might not help you that much in this case):
Since you have only numerical data as features there might be a possibility that if you try something with deep learning you might come across different perspectives.
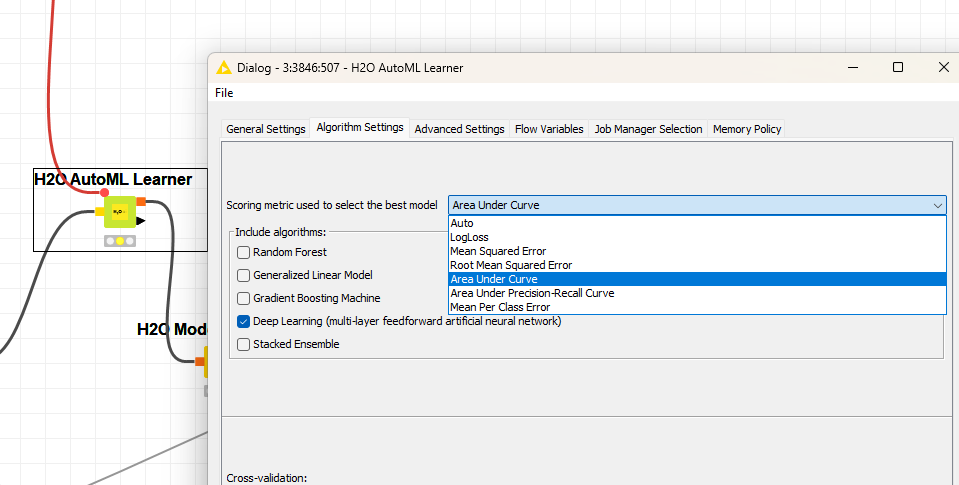
With the H2O.ai AutoML node you can easily let KNIME try some DL without too much effort, Maybe let in run for an hour and see what happens:
You also might want to think about the metric you want to optimize. With AutoML you can let the node decide. Maybe in your case you can start with classic AUC.
Could also be a case for a hyper parameter optimization - but KNIME does not (yet?) support categorical hyper parameters out of the box. You could try some Python code (I have prepared with XGBoost, LightGBM - one would have to expand the objective to test).