Hi all again,
When I run my flow using Windows Scheduler via a .bat file, it errors out on the Ungroup node with this below error and it just exits out. It does not complete fully. Then I open the file with KA desktop software on Windows, I see the error on the Ungroup node, then when I reset that node and execute, it completes fine in KA. How can I debug this? What does this error mean?? Am I out of diskspace, memory, too many characters??? too much data? Any guidance will be appreciated. Thank you!!!

Hi @alabamian2 , what do you mean that you see the error when you open the file with KA desktop?
Do you mean that you saved the workflow in execute state?
Can you reset the workflow and save it as reset, and try again with your .bat file?
1 Like
Hi @bruno29a , thank you for responding!! I appreciate your time and help.
I ran this via the .bat batch file using windows scheduler and the workflow seems to finish in the command dos screen but it is actually not fully executed. I have several email notifications thru out the workflow. I don’t have -nosave in the batch command so i can open the project file afterwards to see what it did and I see that error on the ungroup node as shown in the screenshot. I then can reset the ungroup node and simply execute manually without no errors. Errors seem to happen while being executed in batch mode but not in the knime analytics desktop software.
There isn’t any crash event in the Event Viewer of Windows and Windows Scheduler log or status show that the execution fully completed and the dos window has been closed. I have the suppress error option included in the .bat commad so that may be why everything closes even with unsuccessful completion with error on ungroup node. I have been researching and am not finding much info on debugging this error on the ungroup node. I’d like this node to fully execute in batch mode. Thank you!!!
Hi @alabamian2 , thank you for the explanation, so the executed state is the execution attempt from the .bat file if I understood correctly.
Can you share the results of the JSON Path (whatever will be the input to the Ungroup node)?
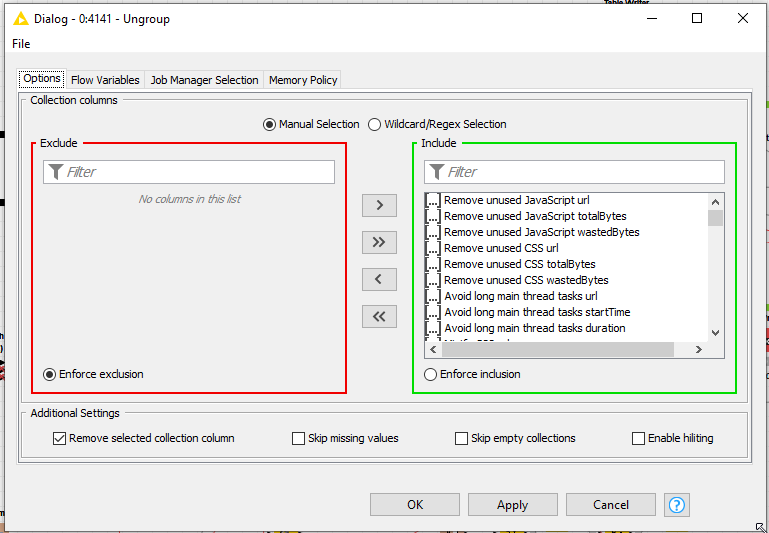
The message “Length must not be larger than capacity” is not about diskspace or memory issue. It has to do with the data. There might be no group to ungroup from the data.
2 Likes
Yes, @bruno29a. It’s big chunk of data so let me work on finding a way to share that data and workflow…will work on it now. Thank you as always!!! Really appreciate your expertise.
hhmm, how can I save the data from JSON Path node and share? It is parsing json files collected from Get Request REST API. Can I save the output data from JSON Path node into CSV? Let me try that. I’ll also try Ecxel file or json writer?
UPDATE - OK, Table Writer node seems to work for this. 
Hi @alabamian2 , yes, you can save as a table, or as Excel. Knime table is probably more precise as it’s exactly the same format as what a data node would produce.
2 Likes
I removed 2 cols (original json col from API and REST URL col since these 2 had API key and token embedded) and Table Writer created 1.5 gig table file. It did not upload here so here is the link to the file.
In the Ungroup node, I have all available items selected. As mentioned, I can execute this fully when I use and execute in the desktop version of Knime Analytics software. It cannot execute when run in the batch mode, seems like and that Ungroup node shows the error when I open the workflow in the KA desktop software afterwards.
If there is anything I can try and test, please let me know. Thank you so much!!!
Hi @alabamian2 , thank you for the data, but unfortunately I can’t open such a big file on my current computer, let alone loading it through different nodes.
You have quite a lot of records there it would seem and quite a lot of columns of type collection - that’s insane 
And you use the same file when running via the UI and via command line?
I tried to reproduce your error, I created a few collection columns (6 in total) with different “structure” (it’s more with different dimensions). When I ungroup, there is no problem, Knime is able to dynamically adapt to the dimensions. If a dimension is smaller, it simply creates records with some column as missing values.
I would not expect any error there, since you did not have any errors when running it via the UI.
I have not tried the command line. Can you share what you run as command line?
2 Likes
Hi @bruno29a , thank you for your help again. I was googling and looking thru the forum, etc and I came across your posts and solutions in other topics. Just wanna say thank you for your support.
After batch mode failed to complete, I simply open the same workflow project file using the desktop version of KA software on the same computer holding all the same data and files from the batch execution and I reset the Ungroup node and execute and it complete fine with no errors. It’s just an odd thing but this is preventing me from running the automation on schedule completely unattended.
This is what i have in the .bat batch file that i execute via windows scheduler.
“C:\Program Files\KNIME\knime.exe” -consoleLog -reset -nosplash --launcher.suppressErrors -application org.knime.product.KNIME_BATCH_APPLICATION -workflowDir=“D:\knime-workspace\SEO\PageSpeed API” -preferences=“C:\Users\Brightline\Desktop\KNIME PageSpeed API task scheduler\KNIME preference 03052021 3pm.epf”
whatevername.bat and you can run it also by simply clicking or executing the file. You can remove the last portion for .epf preference file reference. I have it to keep consistent.
I wish Knime lists error details for each node here.
Hi @alabamian2 , can you remove the suppression of errors to see if we get any additional information?
Also, I’m not sure about the epf preferences. I understand you want to keep it, but for the sake of trying to get the execution to work, could you remove the -preferences argument altogether and run it to see if it runs ok?
If we still can’t figure it out, we could try the hard way, which would be column filter all, and keep adding columns after each execution. So try with 1 column, execute. If it’s successful, add a second column and execute with these 2 columns. Then add a third column, etc to see where it fails.
I hope you don’t have a huge amount.
If you have a lot of columns, you can always do 1 column first, then do 5 columns, then 10 columns, etc and see where it fails.
2 Likes
Hello @bruno29a , thank you. Great suggestions. I updated the preference file to today’s state (by re-exporting and updating the reference) and am running the flow now. It takes several hours and I wanted to test with the real data set so I should know tomorrow am how it goes. And I will set up another test with your suggestions (thank you) and run it again. I totally follow your logic and it’s a very effective way to debug. I’ll follow your direction. I’ll report back tomorrow. Thank you so much!!!
Alright @alabamian2 , let’s see how it goes.
2 Likes
Hi @alabamian2 , if it takes long to run, one thing you can do for the test, is to fork the data like this and set up separate processes for them, and let the workflow run overnight, and see which one or ones failed:
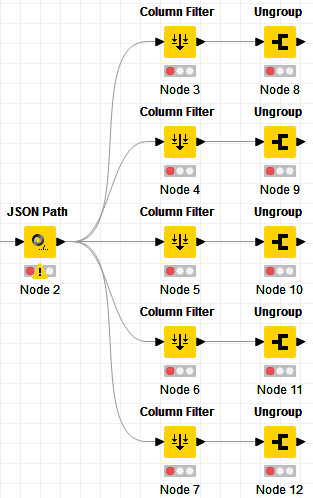
You can separate the data in groups of 5 columns.
It’s still weird that it would run successfully via the UI, but not via the command line.
1 Like
Thank you @bruno29a for checking in during weekend. I’ve been running tests for the past 2 days with unclear outcomes. This workflow in question continues to fail in the batch mode while other batch projects and scheduled workflows complete successfully (even while this big problematic workflow is running simultaneously in a separate command prompt window). Today, I’m going to filter the data set to much smaller chunks for rapid testing in the batch mode. I hope to find some threshold of the amount of data it can process and then will incorporate your testing ideas to further isolate the issue. Thank you for checking in and I’ll report back the progress with much more concise questions or problems than just saying it does not work. Thank you so much!!!
Hi @alabamian2 , no problem. Looking forward to hear about the results
1 Like
Hello @bruno29a , after running multiple tests, I ended up adding Chunk Loop node and Loop End node around that Ungroup node and set the row count to 2000. That seemed to have done the trick and I was able to run the entire workflow with full data set in the batch mode. Still not sure exactly what the problem was, but I’m going to set it to run for a few more days to monitor this. Odd…
Thank you so much for your time and support.