Hi iperez, Thanks for your answer and sorry for not coming back to you yesterday, i was experimenting a lot with your solution. It’s an interesting one I built a working solution yesterday, so thanks to you. But i ran a bit into trouble with it (but more the general question how to store a “data driven calculation” in a “flat” flow variable in Knime.
I made a separate Post about it since it’s a broader more general question in case you are interested you can find it here:
The solution i built yesterday thanks to you looks like this:
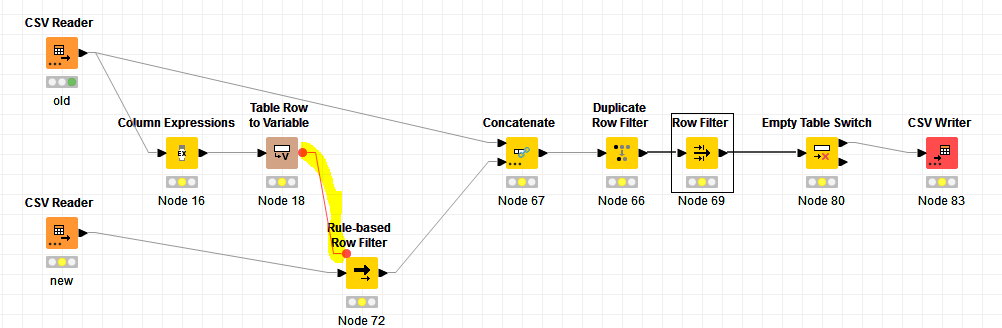
The problem occured on the yellow marking. But interestingly the it did work in the end anyhows ![]()
So the approach (as you can probably already see) was to take the rowcount of the old csv, and by cutting out the newly added rows (since its ordered by time of entry) in the new file. So basically reproducing the old file out of the new file then concatenate… and so on.
The endresult was right but has some drawbacks:
One Disadvantage of concatenate is logically that the lines are not directly underneath each other (or side by side), i mean logically first comes all the line from file1 than all the lines from file2.
But it was very handy to learn how you used the “Duplicate Row filter” mark “unique” rows. Something i would have not thought about. This was very slick to know for future tasks.
Thanks and have a good one!