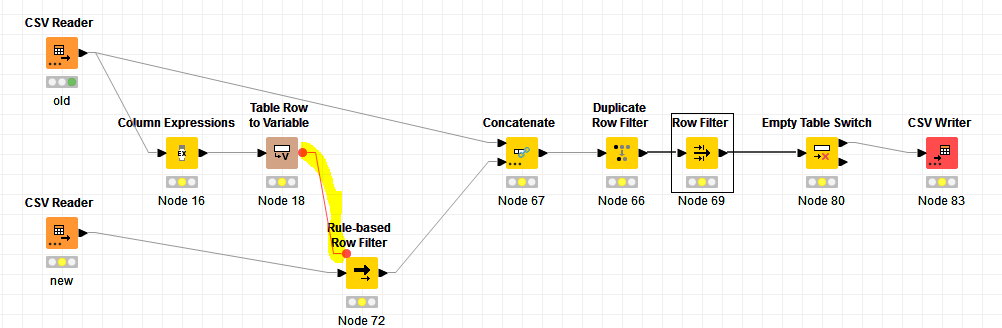
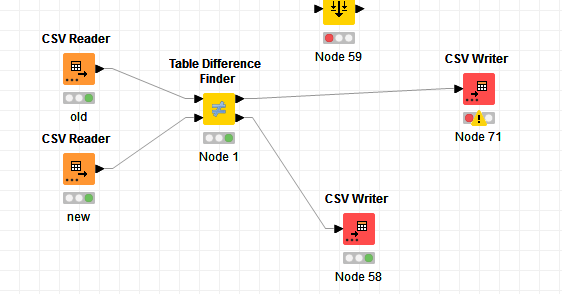
Hi there,
i am trying to compare 2 csvs if they are identical till a certain point of time. The file looks like:
14.09.2011 07:00:00,5.58,5.58,5.58,5.58,12549
14.09.2011 07:34:43,5.54,5.54,5.54,5.54,3418
14.09.2011 07:55:46,5.62,5.62,5.62,5.62,459
the first column is the timestamp of the data. The timestamp is unique in the table.and it is sorted in an ascending order.
The file is created by a knime workflow, that runs periodically, and creates a new file. The new file contains all the data that the previous (aka old) file contains, and of course, some new entries with newer timestamps (always in ascending order).
What i want to do now is to compare the new file with the old file to check for inconsistencies, whether the old data has changed. The last row of the old file mibht be different from the new file (since its actually an aggregation of a time span that might not have the full interval at the time the file was created) from the new file without beeing an error.
So what I want a process that compares if the new file contains the same data till Rownumber-1 of the old file, ignores the rest of the rows and reliably gives out an OK if that is the case. (Giving the OK could be an Popup window, or writing a file with the name OK etc, writing an empty table…) If differences occus it should write those differences in a csv file.
What wold be a good way of doing this? I am thinking now for a while about it but i don’t really get anywhere with this. I guess my main problem is in case of a difference to write both lines in a csv file…
I read in the forum about the “joiner node” but since i already know that from a certain row on there will be only differences it seems a very wasteful way of doing this (files are pretty large).
Great forum and i hope someone has an idea…
Greetings!
PS the attached file is some testdata just to illustrate.
Upload.txt (1.2 KB)