I would like to compare different machine learning models ( SVM, random forests, Neural networks) for a multiclass database. I cannot use the ROC curve for this problem as I have more than 2 classes. I have from the scorer the confusion matrix and the Accuracy and the Cohen Kappa. There is also the F-measure, sensitivity, recall.. for every class.
Can I say that the best model is the model with the highest accuracy or I should take in to account the other parameters. Is it appropriate to take the average of the F-measure, recall ..over the different classes?
How can I measure the out-of-bag error for my model and how can I apply it for my models comparison?
The best measure for your models performance is heavily dependent on the problem. However, since you're dealing with more than 2 classes you have to keep in mind that only accuracy generalizes to more than 2 classes, although averaging the F-score, Recall and Precision measures can also be an option.
In case of both Random Forest and Tree Ensemble Learners the first output port gives the out-of-bag error estimates (more details in the node description), you can calculate the error using the Scorer node comparing the true class with the out-of-bag prediction. However, it is not possible to compute the out-of-bag error estimates for SVM and Neural Networks.
This depends on class distribution and the goal of your model.
if you have approx. same number of observations per class and all classes are equally important, then yes accuracy is a good measure. However if one class is much more common or much rarer then no, it can be very misleading as especially in case of a rare class, the predictions could be very bad while not impacting accuracy much.
Classic example: assume binary classification and 90% of observations are from one class, 10% from the other. A static model predicting everything as the majority class would hence have an accuracy of 90%.
Cohen’s kappa is a measure that takes class distribution into account and can be used in conjunction with accuracy. However it still depends on your actual problem if it’s a usable metric and there is no clear agreement of what a good value is (highly depends on the problem)
But the goal of your model is crucial accuracy might not matter much. For example in an HIV test you would want to avoid false-negatives at all costs even if it negatively affects your accuracy.
Don’t think so. I think what @amartin had in mind is to connect first output port of Random Forest and/or Tree Ensemble Learner nodes to Scorer node to get accuracy on out of bag estimations.
Thanks for your response. Sorry, I am not expert in machine learning and its nomenclature.
I got the point made by @amartin ; But, as I understand, overall accuracy given by the scorer node means all the correctly predicted cases (including positives and negatives) out of total instances. For e.g. in following example
total cases = 1016+874+63+87 = 2040; correctly predicted = 1890; therefore accuracy = 0.926 (or 92.6% accuracy)
Wrongly predicted data = 63+87, therefore error is 63+87/2040 = 0.0735
which obviously can also be obtained by deducting overall accuracy from 1 (or 100, if considering in percentage) i.e. 1 - 0.926 = 0.073
My question is for out of bag accuracy estimate, if we do the same thing (i.e. 1 - accuracy), do we call it OOB error or is it some other type of error?
If not, how can we obtain OOB error from the RF learner node in Knime?
Hi All, I’m new… coming from Alteryx Designer and trying to get up to speed on Knime… I have a data set where I’m training 4 models (Logistic Regression, Decision Tree, Forest, and Boosted) with historical data to see which is best at predicting loan default risk base on data we have available at time of application. In Alteryx I have a Model comparison “node” that takes the Union node of all the Learners Nodes and the other input takes a Validation set to test against. In the output you get a report with Fit and Error Measure, Confusion Matrix for each Model, and combines all for each of these charts (Lift curve, Gain Chart, Precision and recall curve and ROC Curve). This let’s me see which model worked best and run my new data set through the winning model… or I could continue to tune the data set to see if the performance of the models change… until I’m ready to select a winner.
Is there a similar node that does this in Knime? If no, how do I do this?
Alteryx and KNIME while superficial similar follow completely different philosophies. KNIME offers you the core building blocks to build your own algorithms. This means more “boilerplate” nodes but more flexibility. Alteryx offers ready.made “macros” with lots of hidden/blackboxy features but you get to do complicated things quickly with little flexibility.
Hence no, KNIME does not have such a node out-of-the box. You can however on KNIME Hub look for the AutoML component and look in this forum for help/instructions regarding it.
Having said that I don’t really like these black-boxy tools.Each model will most likley require a different way of evaluating it’s performance and thinking about which method to choose and why is a step to understand your data, model and their limitations.
Example:
I have a data set where I’m training 4 models (Logistic Regression, Decision Tree, Forest, and Boosted)
Why these models? Why not also SVM? Or KNN? Why 3 types of tree-based models? (xgboost will almost always beat the other ones and never loose “big”)? Black boxes prevent such type of reasoning.
For example you shouldn’t use tree-based algos if you have a lot of one-hot encoded categorical data.
Thanks for the suggestions. I’ll take a look at the components. Are components collections of nodes? like a meta node? Sorry I’m a newbie to Knime. This was part of an assignment which I assume was to help us see how each variation of tree-based models are different. In testing so far I have found the Random Forest model performs better on validation data it’s never seen before vs Boosted (at least in Alteryx)… but that may be my inexperience in configuring.
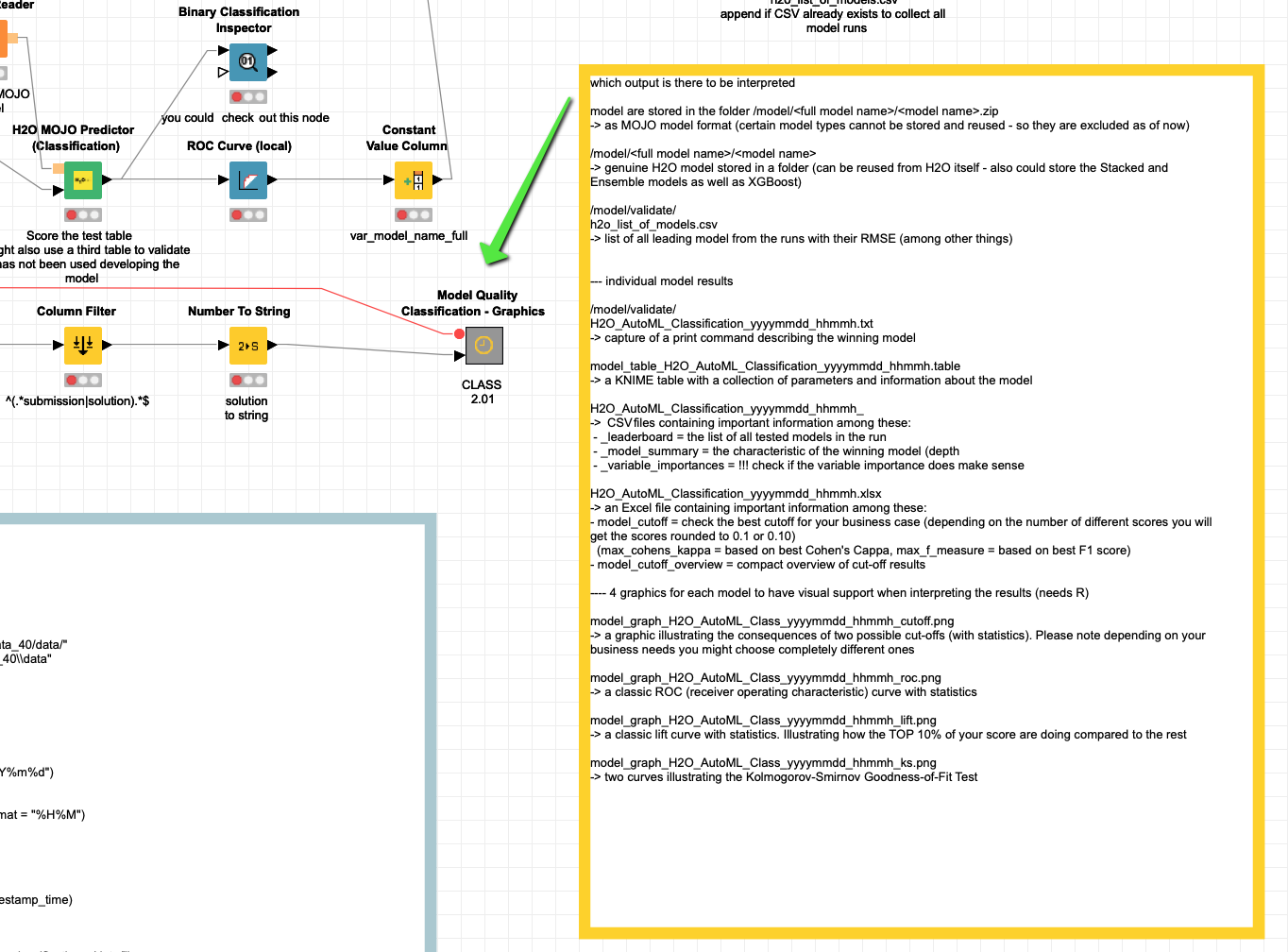
I created two Meta nodes for binary and regression models that would run a certain set of parameters and create some graphics (you would need some R packages). Input would just be a solution column with the truth either as 0/1 string or the number and a “submission” which is the score from 0-1.
You could collect the results from the statistic tables and see which model is best. But you might want to be careful since what is ‘best’ might depend on your business question and which cutoff you would come to use. The Meta node does suggest an optimal cutoff but you might want to include some costs (for misclassification).