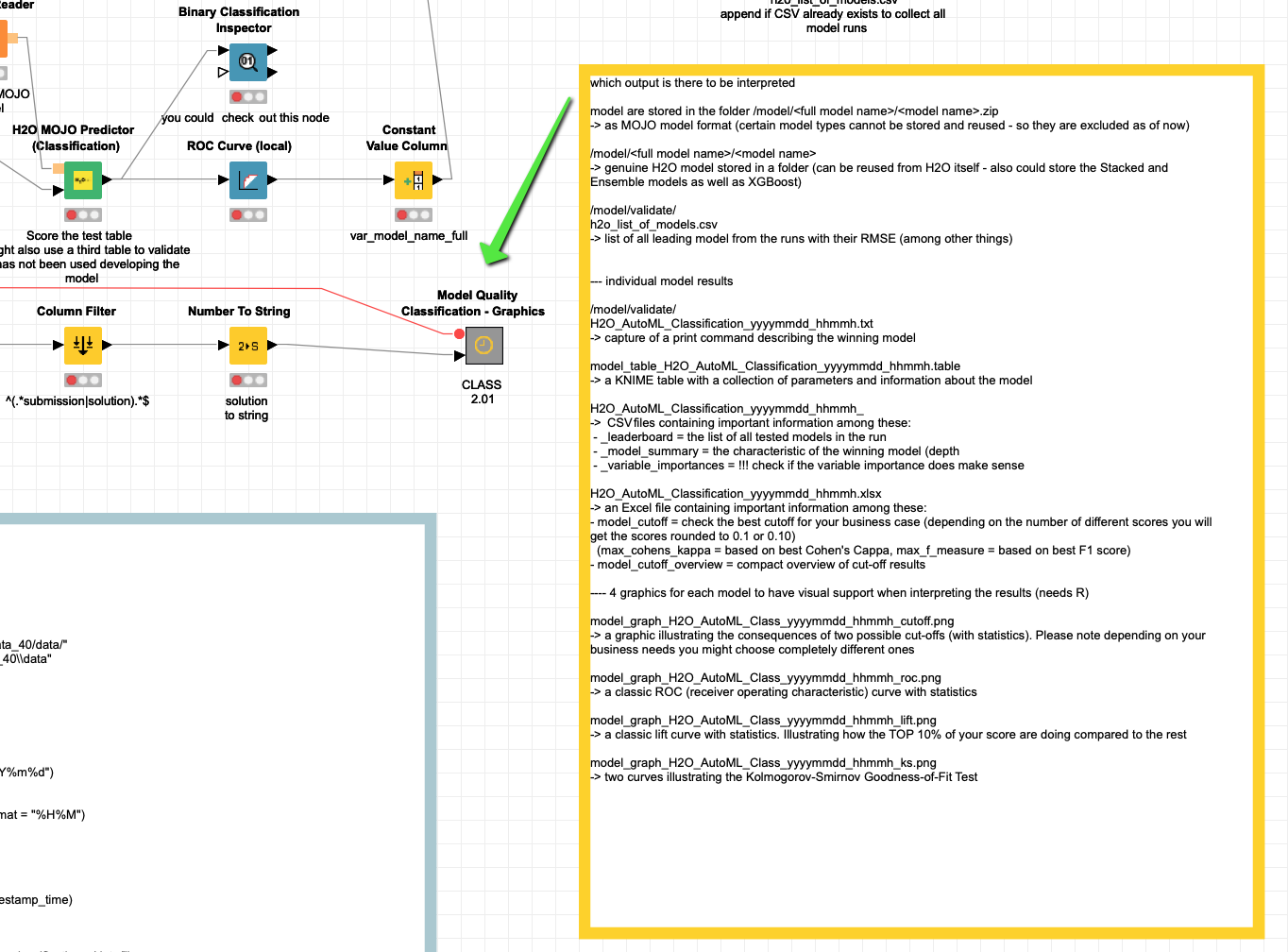
I created two Meta nodes for binary and regression models that would run a certain set of parameters and create some graphics (you would need some R packages). Input would just be a solution column with the truth either as 0/1 string or the number and a “submission” which is the score from 0-1.
You could collect the results from the statistic tables and see which model is best. But you might want to be careful since what is ‘best’ might depend on your business question and which cutoff you would come to use. The Meta node does suggest an optimal cutoff but you might want to include some costs (for misclassification).