Hello,
I need to make a grouping according to the name of a column that is in a flow variable, I am trying the following:
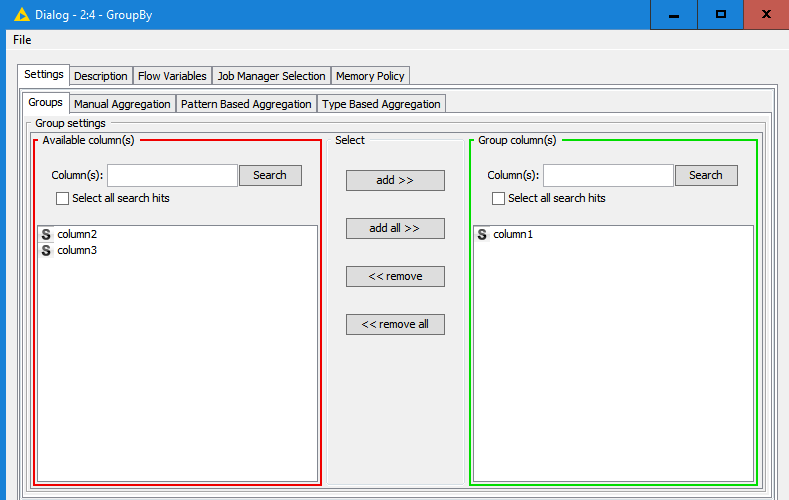
How could it be done?
Thank you very much, sorry for my level of English
Hello,
I need to make a grouping according to the name of a column that is in a flow variable, I am trying the following:
How could it be done?
Thank you very much, sorry for my level of English
It is a bit tricky, but you need to manually add 1 grouping column, and then switch to the flow variables tab. There will be a setting with a 0 as label. Select this to be controlled by your flow variable. (There is a similar here for adding an attachment to an email by flow variable - "Data to report" node generate report with dynamic names using this method)
This slightly strange comes about knime doesn’t have array flow variables
Steve
Hi Jev,
yes as Steve pointed out it is quite tricky to control the groupby node with variables.
How about renaming the column instead? You can rename the column before with the column rename regex. And control which column is changed via a variable and afterwards change the placeholder name back.
This was done similarly here: https://hub.knime.com/knime/spaces/Examples/latest/06_Control_Structures/04_Loops/03_Looping_over_all_columns_and_manipulation_of_each
Cheers, Iris
Hi, thanks for answering, but I do not understand the solution. I return to expose my problem.
I need Using variable variables to set GroupBy grouping columns, for example:
variable flow: name_column
value name_column = LAST NAME.
I need to group by the LAST NAME column.
Thank you very much, excuse the ignorance, I am noteworthy in this.
OK, here is a very simple example:
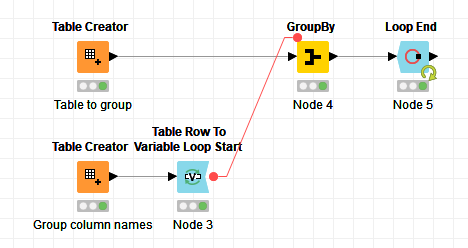
Firstly you must make sure the Table Row To Variable Loop Start node is executed before trying to configure the GroupBy node.
In the GroupBy node settings window, add a column (any column at all - doesnt matter, as long as you have a column there!):
Now, switch to the ‘Flow Variables’ tab, and expand the ‘grouByColumns’ [sic!] and then ‘InclList’. in the ‘0’ box, select the variable you want which will contain the grouping column name (NB, if you didnt do the previous step then there will be no ‘0’ option here):
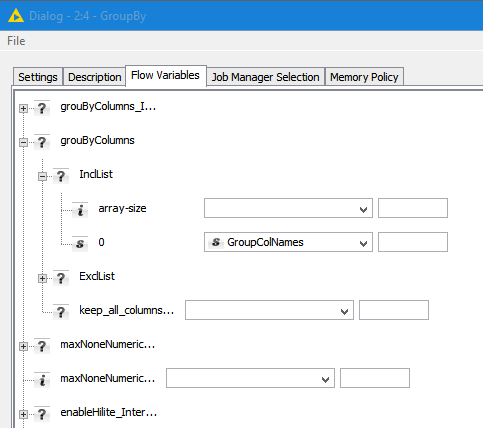
If you got this right, then at the bottom of the main ‘Settings’ tab, you should now see:
You are now ready to try it.
The very simple example show here is attached.
Groupby with flow var.knwf (13.2 KB)
Steve
Thanks roughley!
Thank you very much for answering, it worked perfectly, another question
It is possible in the section “Manual Aggregation”, that the group by the name of that column entered in the “table creator” to group and make a sum of that value.
Hello,
For anyone still looking for a way to dynamically assign all the parameters in the GroupBy node (specifically the grouping columns, the aggregation Columns, and the aggregation methods), I made this example on the hub of it working.
Cheers!
-Stephen
Hi @srauner,
I’m trying to use the GroupBy node dynamically in both the grouping and aggregating columns. In your example, you specify the aggregating columns manually in addition to do it via flow variables, but that contradicts the reason to use variables in the first place…
The node cannot be configured when both grouping and aggregating columns are only specified through variables. Moreover, if I specify the grouping columns manually to be able to configure the node, and the aggregating columns via variables, together with the aggregation methods, and the column types, the node yields an error when trying to load the variables. See the attached modified workflow.
GroupBy_FlowVariables_mp.knwf (46.3 KB)
Hi @mpenalver ,
The flow variable will overwrite the manually selected value.
In addition in some cases, you might need to select something manually first, and then be able to use the flow variable, probably because of what I said above. It’s how Knime behaves generally, that is the variable is there to overwrite the manually selected value. If you don’t select anything manually, the flow variable is either unusable (that is you cannot specify a flow variable), or Knime simply has nothing to overwrite.
Thanks @bruno29a. I don’t know whether there is a technical reason for the need of a preexisting manual setting, but from a user’s standpoint that need seems both unnecessary and problematic. Since I can specify an array of columns to group by, and another array of columns to aggregate, together with their types (not sure why this is necessary, since I believe columns names must be unique) and aggregation methods, the node should have all the information required to perform the grouping. Moreover, in some cases, like the one I’m trying to implement, neither the name nor the number of the columns to both group and aggregate are known in advance, so manual specification is not an option.
Hello @mpenalver,
This workflow is more to show how to make it possible. It is a bit hardcoded (on needing to create reference tables for different aggregation methods for example). However, if needed for an end-user application could be improved using our selection widgets with refresh capabilities.
Cheers!
-Stephen
After inspecting KNIME’s source code, the problem seems to be that the configuration structures created through the node’s dialog pane and through a flow variable differ for the aggregation columns’ types. When the columns are specified through the dialog, a DataType instance is created including the column’s cell class name, which is copied to a ConfigBase instance within a Config instance (org.knime.base.data.aggregation.ColumnAggregator.saveColumnAggregators). However, the content of the flow variable is copied immediately to a ConfigBase instance (org.knime.core.node.workflow.VariableTypeRegistry.overwriteWithVariable). So, even if its content is also the column’s cell class name, the retrieval of the configuration for the aggregators (org.knime.base.data.aggregation.ColumnAggregator.loadColumnAggregators) fails because it expects a Config instance instead of the ConfigBase instance it gets.
This problem appears to occur with any node using aggregators.
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.