Hi all,
Thanks in advance.
Hey there,
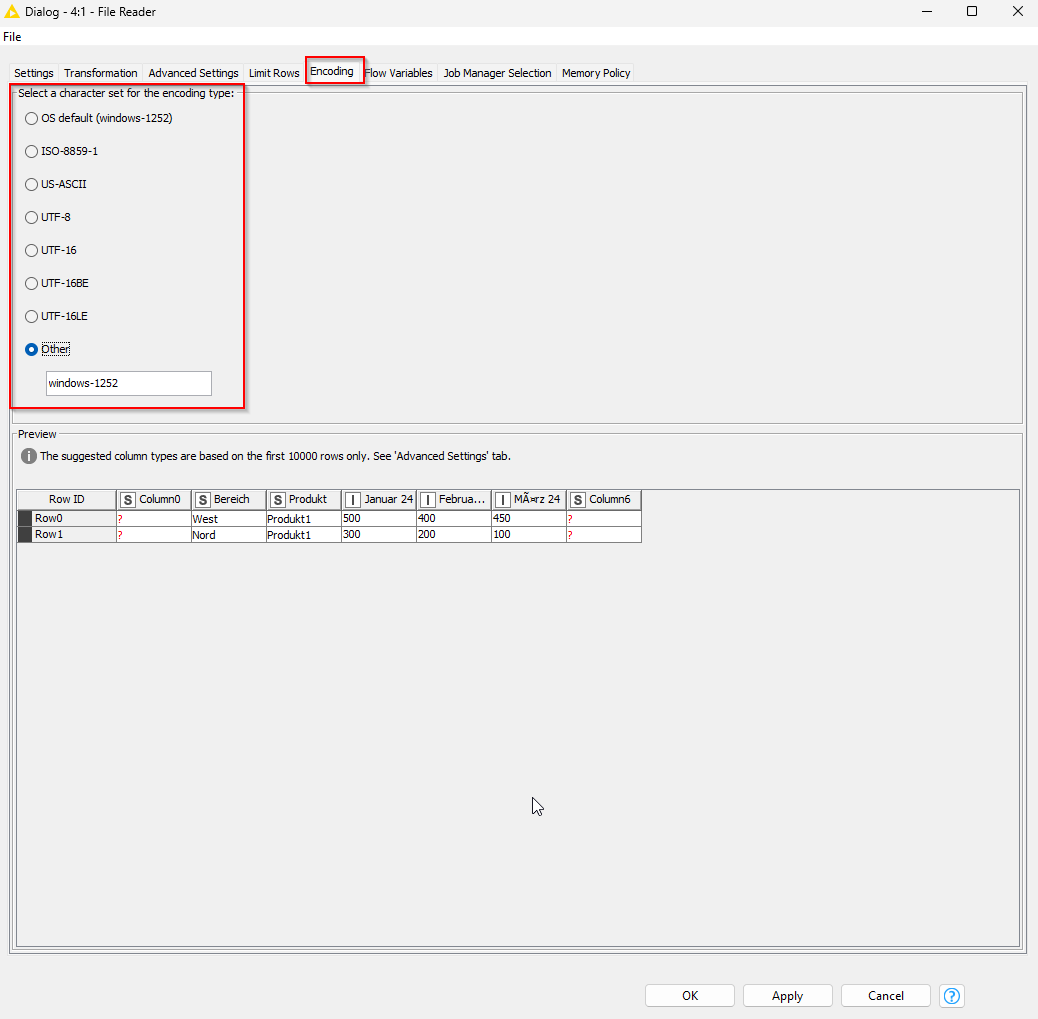
Likely an issue with the encoding selected by File Reader Node.
In configure dialogue can you go to Encoding and see what setting you have?
If you have english and arabic characters I think selecting UTF-8 may solve your issue…
1 Like
Hey @gokulpnair ,
Have you tried Tika Parser node. It would solve your problem
If you insist on using File Reader Node, you can reference below example
Hi @michael19602016 -
That’s an interesting problem! Our existing nodes that detect languages (Tika Language Detector and Amazon Comprehend (Dominant Language) ) do so for either strings or documents, but for the entirety of the field that is input. So one approach might be:
first convert your strings to documents (using language independent whitespace tokenization)
extract sentences from those documents
detect the language of each sentence
branch based on the language
continue analysis downst…
Regards,
2 Likes
Thanks @MartinDDDD & @yogesh_nawale for the inputs. As suggested by @MartinDDDD tried with UTF-8 and the language rendering worked fine. Thanks
1 Like
system
July 29, 2024, 7:54am
5
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.