I have a situation where I have either ORACLE or SYBASE db type, depending on what environment the KNIME job will run.
Depending on the db connection type the rest of the KNIME job will execute.
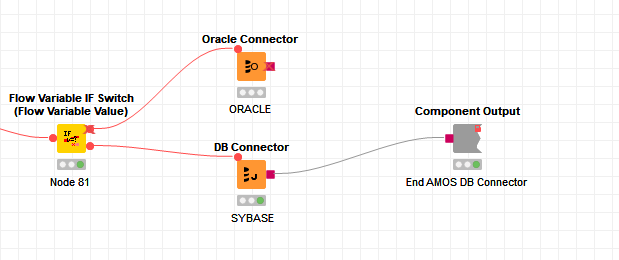
I have below issue now, where I want to pass on either the ORACLE or SYBASE connection depending on which one it is. Is there an option in KNIME where I can say pass on X or Y based on which one it is? I cant add two input lines to the next component.
Interesting. As far as I know, you can’t really use two different database connections for same data extraction node.
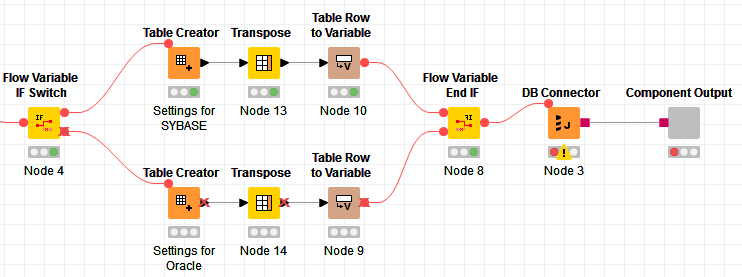
In this case, I would say, you need different data extraction nodes (eq DB Query) for each of DB connectors, and after that you can again merge your flow using end if.
The only alternative I can readily think of (and I haven’t tried this to see how practical it would be) is to use a single generic DB connector node rather than two dedicated (i.e. SYBASE and ORACLE) nodes but you would then have to populate all the driver, parameter and connection details using flow variables.
You would change the values of these connection flow variables according to database being used, and pass these values into the connector node. After that you would have the one flow.
It does of course require that all your subsequent data access will work for both databases (same table names etc). Given that the underlying database access models for Oracle and Sybase are quite different (use of “schemas”, versus “users/owners” etc, and variations in sql syntax), I would have thought this would either be very limiting or will be likely to add other complexity downstream. It might be workable though if you are limiting yourself to generic data access using the basic KNIME DB nodes and not hand-crafting any sql (with for example DB SQL Executor).
@Sjoerd if you have two databases that are not linked on a technical level but only thru KNIME there is one option by @tobias.koetter to use streaming nodes to transfer data between them. You might want to give this a try:
Only other alternative would be to download the data, do the join/concatination in KNIME and upload the whole whing again (if the data is very large that maybe is not the best option).
Thanks for your reply. The purpose of the task is to run data analyses on a database. Both database are of the same structure, so the KNIME job is the same for both (db queries are all generic). Its only the connection that needs to be selected, ORACLE or SYBASE.
“The only alternative I can readily think of (and I haven’t tried this to see how practical it would be) is to use a single generic DB connector node rather than two dedicated (i.e. SYBASE and ORACLE) nodes but you would then have to populate all the driver, parameter and connection details using flow variables.”
@Sjoerd, ah ok, now I think I understand what you want to do. Question is if you could develop the syntax in a compnent or meta node and then just use such a switch to activate one or the other branch. You would then ‘just’ have to refresh the content of the meta node/component.
Hi @Sjoerd , as always, there is more than 1 way to do things in Knime, and it applies to this case too, and the different proposed solutions are all possible solutions, with their own pros and cons.
The main 2 ways I see this to be done is basically:
Having 2 db connections, 1 sybase and 1 oracle, with an if switch before that that will decide which route to take, like what you have. This however, will generate 2 separate db connections in the workflow, and you will have to implement the rest twice, as you found out, you cannot merge the 2 connections. This is an unnecessary duplication - it’s inefficient and will be a pain to maintain.
Use only 1 DB Connector, a generic one, like @takbb suggested, where you can specify what type of connection you want to do, using the DB Connector node. This makes even more sense especially that the table structures are the same on either database, and if you are going to use SYBASE or ORACLE specific operations, there should be no problem. Something like this:
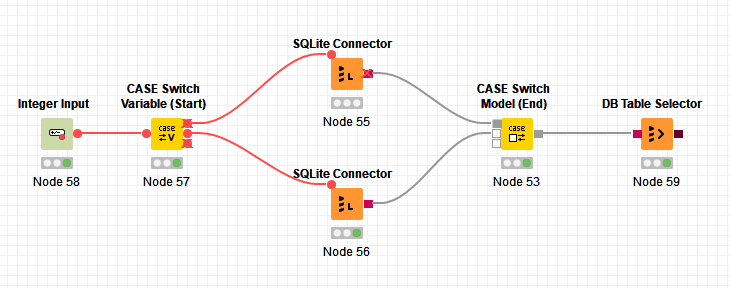
Hi @ipazin , this is a nice find!! Did not know that the CASE Switch Model could take a db connection (among other things - it seems like it can take any “square” input/output)
For the Database CASE Switch/End CASE (there’s also Databse IF Switch/End IF), I saw these nodes, but the reason why I did not propose them is because the input/output is not the same as the Connectors - Connectors have red square output, while the other nodes mentioned above have the other type of input/output (burgundy square), and it looked like @Sjoerd was looking for something with the red square output for the component.