I need to left pad a string to be able to use it as join criterion, but I was not able to find such functionality in KNIME? I know the String Manipulation node but this does not sport padding... do I need to write a Java snippet?
I could create the functionality by a Java snippet but I am still interested in knowing whether there is an out-of-the-box solution. I am rather concerned that if such a common transformation is missing, many more are missing and KNIME is not quite up to the task of ETL... sure it is not advertised as being one. My code is (derived from https://stackoverflow.com/questions/13475388/generate-fixed-length-strings-filled-with-whitespaces):
int width = 10;
char padding = '0';
return new String(new char[width - $PID$.length()]).replace('\0', padding) + $PID$;
I'm not aware of a direct function that does this, however a Java Snippet (simple) with the code return String.format("%010d",$PID$); is hardly any more complicated than a single node. There are solutions in R, python and any other integration KNIME offers available on the internet as well.
Personally, I agree with you. That's something that might be worth to add. However, there are thousands or even millions of possible ETL steps out there, and although there are so many different nodes in the Analytics Platform and even more in the community extensions, there will always be an ETL step that is not there as a dedicated node. Also it might be in there, we both just haven't found it yet.
The forum is always a good place to look for some pointers or neat solutions to a certain issue. Feel free to ask whenever you're looking for a certain functionality or elegant solution, or just send me a message.
While that’s certainly correct for a single string padding operation, it would still be useful to have padLeft and padRight functions (similar to the ones available in Groovy, for example) available in the String Manipulation nodes, for combining them with other string operations. This would avoid the need of having an additional node just for the padding, or moving the entire string manipulations into a Java snippet.
So how about adding the PadLeftManipulator and PadRightManipulator classes to the org.knime.base.node.preproc.stringmanipulation.manipulator package here:
Of course, already now you can do some padding in the String Manipulation node, without the need for a Java Snippet node, but it’s a bit cumbersome and not very readable, e.g. to pad an integer to four digits with 0s:
Am I misunderstanding the examples in the String Manipulation node? one example is
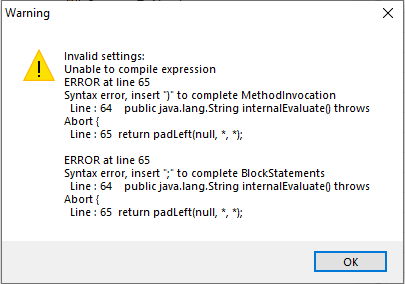
padLeft(null, *, *)
which should resolves to null … but this causes an error
what I’m most interested in is using the * wildcard for the size of the string
* in these examples represent any size or character and not a wildcard pattern. So above example means that padding null string with any size and with any character will give you null string. Can you give us some example with data to better understand what are you trying to do?
I think I’m using the wrong function… I was tired and not reading or rather comprehending… I was looking for a concatenate and missed the join so I thought I could use padLeft if it length could be variable based on original length but then that would not be a pad… that would be concatenate.
when you are tired your ability to get stuff done has diminishing returns
Feature request. I realize this is alot of overhead but it would be a very powerful selling point… Interface Language that is beyond spoken language… English (SQL user) or English (Excel user) or English (Marketing User) or English (Data Scientist)
Background: I had worked at a company where we acquired a company where the native language was not english. It supported a number of languages but the interface always felt like it was poorly google translated to English. Using word not commonly used in competitor apps. It always felt like it was not only translated from another language but also used Engineering terms but the target audience were marketers. This made onboarding new users especially tough.
How it relates to KNIME:
For instance using “join” for concatenation in String Manipulation node is a little odd as both SQL, Excel, Google Sheet and other competitors use some form of “concatenate” as the wording.
This would be a big undertaking and maintenance effort but perhaps could be crowd sourced by the community if you build the framework in the app then the community can create custom translations for other users to download and use. I know there is little likelihood this will get traction but thought I would throw it out there. It could really help expand user base.
KNIME is talking with Java and ML accents. It is not end user tool and recently even moved in programming tool area not in direction of end users tools.
Ex.
If the target niche is programmer… that makes sense. I’ve observed most programmer perfer to stay in code for production and use other tool for rapid prototyping… I have seen other apps that aid programmer by giving them an interface to build up complex logic but then allow them to see what code is generated behind the scenes which they can examine and optimize.
But if the niche is Data Scientist… the question should be asked is their primary language the programming language (not sure if they use consistent terms) or something other set of apps they use to manipulate data. I don’t know the answer to this.
There is a shortage of Data Scientist as compared to open and anticipated roles at companies so giving programmers the focus is smart to tap into a pool of technical talent. Selfishly being a citizen data scientist I would love some attention for those of us users that have a business / engineering data analyst background but have long forgotten code (#FORTRAN but I heard it is coming back)
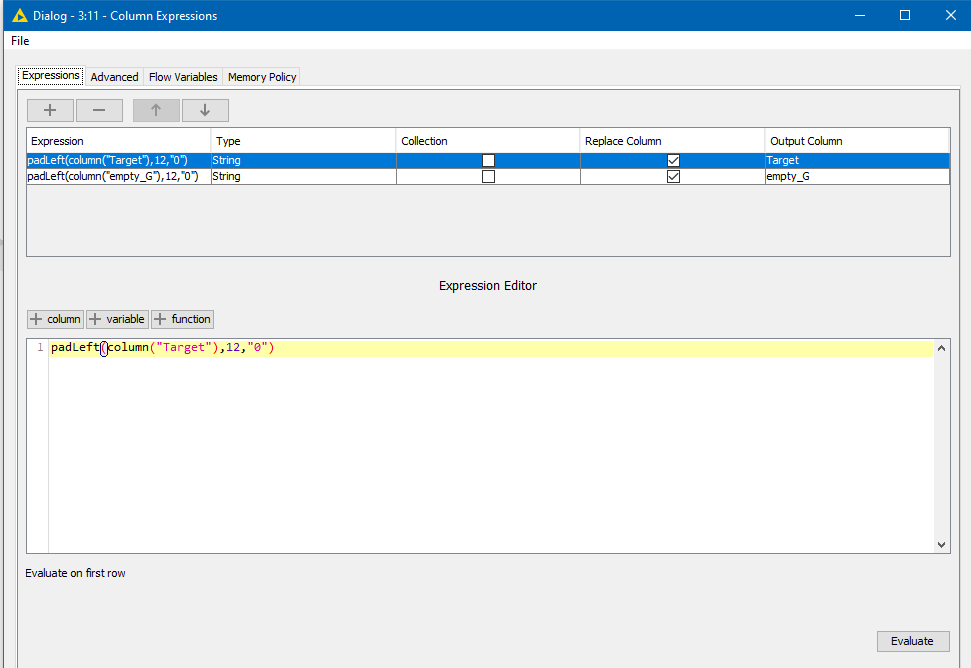
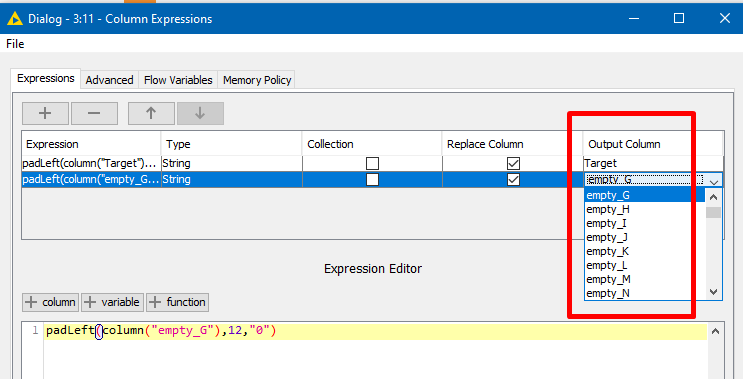
I was able to shorten the expression using < padLeft(column(“Col01”),12,“0”) > meaning, I want all cells to have 12 digits and the ones that do not, add a zero as a prefix.
Any help is appreciated. Thanks!
J.
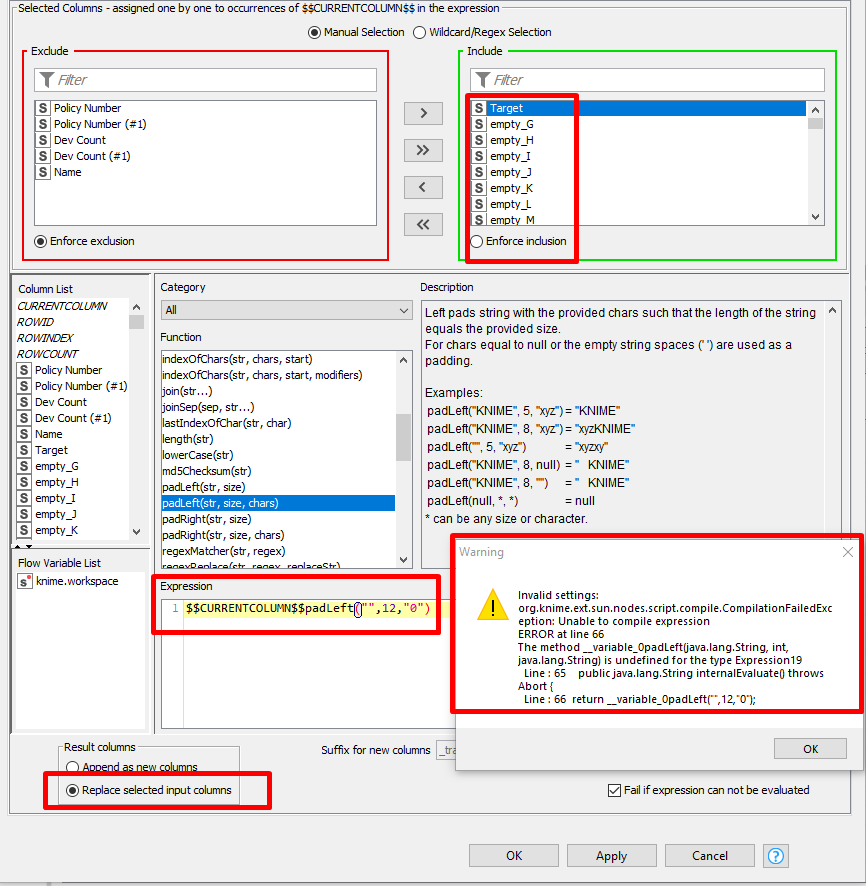
Here’s what I am doing, but since I have 200+ columns, I am looking for an easier way
I would like to add 0s to the left of the strings that do not have 12 characters. Some do as shown towards the left. However, the way I am doing, I am having to create a line as an output column for each column, as since I have a couple of hundreds… it becomes harder to do it manually