I’d like to write an extension that accesses the table output values as seen in the gif. How can I do this programmatically? The idea is to make two nodes similar to the Capture Workflow Start and End Nodes that will collect and then create provenance data for the workflow.
Hello, you may be referring to the set of Call Workflow nodes? Please let me know if that is not what you’re looking for.
Not really. I’m looking to grab the tables output of the workflow segment as well as the node metadata. Preferably with the table outputs zipped with the node metadata. Something like below.
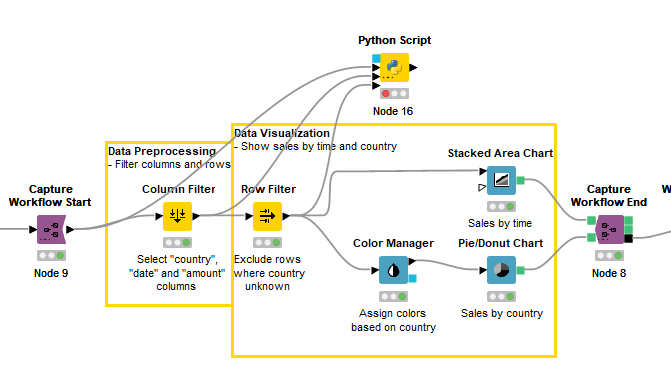
Hey @azsb1g19,
For an IT forensic solution, I created a workflow for the digital chain of custody that stores the data of a workflow together with the meta information and the workflow itself. Sorry, but the description is currently only available in German and in a somewhat older form.
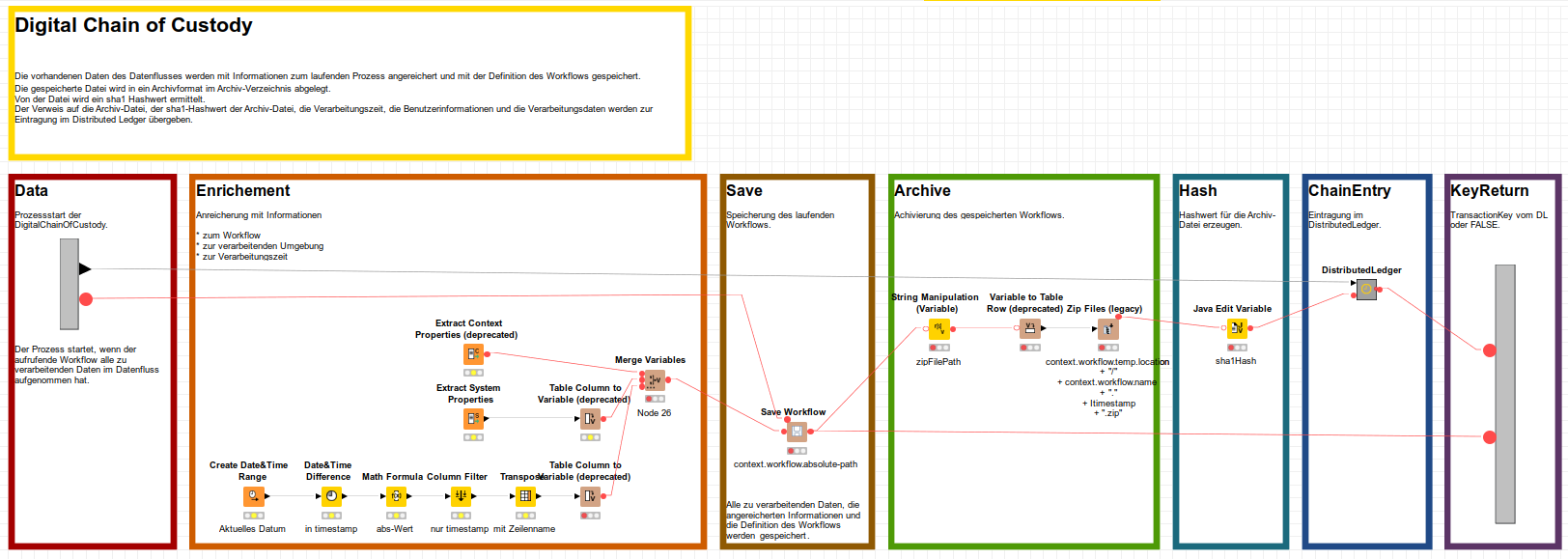
To summarize:
The existing data of the data flow is enriched with information about the running process and saved with the definition of the workflow.
The saved file is stored in an archive format in the archive directory.
A sha1 hash value is determined from this file.
The reference to the archive file, the sha1 hash value of the archive file, the processing time, the user information, and the processing data are passed to a distributed ledger for registration. A transaction ID is returned and can be processed in the original workflow.
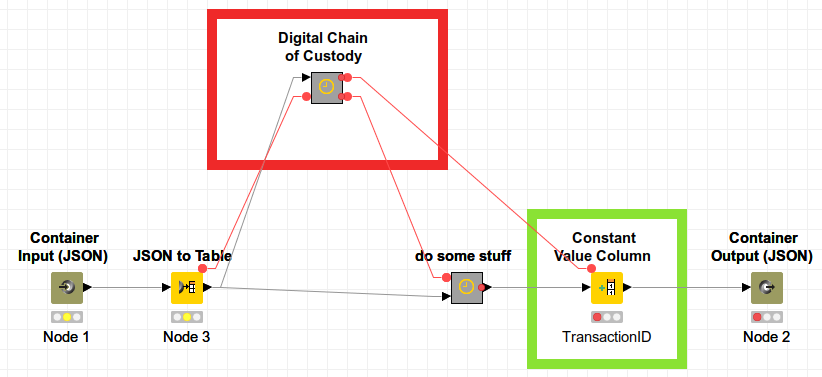
The DCoC Node can be used at any point in a workflow, at best, when all the data to be processed is available and before the actual data processing takes place, so that data storage is as economical as possible. Example:
Does this fit your query?
Best Regards
Andrew
1 Like
This works, where can I find this node?
Hi @azsb1g19,
it is for an older KNIME version. I would customize it, convert it to English and put it on the KNIME Community Workflow HUB. How fast do you need the workflow?
Best regards
Andrew
That depends how this How to extend an existing node? post goes. 2-3 weeks would be good if I can’t resolve this another way.
Hi @azsb1g19,
to avoid any misunderstanding, the digital chain of custody is a component node, not a single node.
Best Regards
Andrew
Hi @Andrew_Steel , technically speaking, what you have there is a metanode, not a component. As I was reading the thread, I was actually about to ask you why don’t you use a component for this.
As you said, this is something that you want to be able to just plug anywhere. The advantage of using a component is that it can be a shared component, which basically can be stored similarly like a node, and you can drag it from your Knime Explorer to any workflow that you want.
The other advantage is that is you keep it as a linked component when you use it, when you make modifications to the component, whatever workflows is linked to it will automatically be updated with the modifications.
You can think of Metanode as just collapsing code, just like you would collapse blocks of code, where the collapsed code is pretty much dependent on the whole code, and can come into conflict (variable, naming collision, etc) with other pieces of the code, while you can think of Component as independent library, or a function that can take input, do its things internally without conflicting with whatever is outside, and returning the results.
As for @azsb1g19 's request, can’t you just write the data to a Knime table via the Table Writer?
Hey @bruno29a,
You are right, of course. The version shown above is a metanode. It is a somewhat outdated version. The new one is actually a component node. I will put this node with a suitable description in the HUB. It will probably come in the next week. The difference between data lineage and a digital chain of custody will be described there too.
Best Regards
Andrew
2 Likes
I want to make something that generically writes all the data tables of a workflow segment (and then does something else with those tables). It would be tedious for the users of what I’m making to link up every node in a segment.
Thanks Andrew, could you post a link here when that’s complete?
1 Like
Hi @azsb1g19 ,
I see what you mean. Indeed it would be tedious if you had to manually write after each table. I believe that @Andrew_Steel 's component would not work for you either, since it would be capturing 1 table only. You would have to connect his component to each table that you want to capture, in the same way that I suggested - you can see what it’s doing and how it’s being used.
Just to further understand, when you say all data tables, do you mean ALL of them? For example, let’s say you have this workflow:

Do you mean to capture the results of all 13 nodes? All 13 nodes are data tables (output port is of type data). In fact, Node 9, 10 and 12 will have output multiple times since they will execute within a loop. Is it suppose to capture the output of all iterations?
Also, in what format would the data tables be saved? And how would you know which saved data table refers to which node of the workflow? Perhaps if you explain the purpose for this a bit further, then we could find an approach to help reach the solution.
1 Like
Hey @bruno29a,
it is not quite correct that with the DCoC component only 1 table is written. The DCoC component is designed to store, at the time of inclusion in the surrounding workflow, all the data generated up to that point from all executed nodes, together with the environment variables and the definition of the workflow itself. The question is at what point in time it is incorporated. For forensic use, the time would be when all the data to be processed is present in the workflow. For reasons of economy of storage, that should be as early as possible. Resuming a workflow stored in this way should always produce the same result. So in your example, the right place to include the DCoC component would be the output of Node 1, since all the necessary data is already available at that point. However, I can also attach it to the output of Node 11. Then all the data of all executed nodes will be stored. And yes, in the case of the loop, the last results of the nodes in the loops are stored.
Best Regards
Andrew
Hi @Andrew_Steel , thanks for the additional information. The component is still storing data of 1 table only, which is the node that it’s attached to, just like if you attached a Table Writer to a node, it will collect the data that the node that it’s attached to has produced.
For example, if I attached a Table Writer to Node 1, it will get the results of Node 1. I can also have another Table Writer further down, let’s say at Node 7. It will write the results of Node 7 - yes Node 7 is the results that have been processed from Node 1, 2, 3, 4, and 6, but the Table Writer will not be writing the results of each of these Nodes, only the Node 7 if it’s attached to Node 7. Similarly with your component, it will only write the results of Node 7, not the individual results of Node 1, 2, 3, 4, and 6.
My understanding is that @azsb1g19 wants to be able to retrieve the results of Node 1, 2, 3, 4, 6 (and other) without having to plug the Table Writer, or your component manually to each of these individual nodes.
You are correct, I would like to capture the results of all nodes that have output ports of data tables. The tables and their corresponding node metadata would be fed as inputs into another node that would process these and output a PROV-mappable structure.
Naturally, this is a very space intensive operation.
What I’ve been trying so far to grab this data is to rewrite the Integrated Deployment nodes to capture workflow segments so that they include this data - but the execution contents and port objects (the inputs) of node containers is inaccessible. Which is why I was wondering what that context menu in my first post does, and if I can grab the data in a similar way.
to further explain the Digital Chain of Custody concept, as a type of Data Lineage:
Starting point:
When you (partially) execute a KNIME workflow and then save it, all output data currently held in RAM from executed nodes are stored in the workflow. You can find this data in the node directory in the port_x sub directories of the output ports. When you call this workflow the next time, these data of the executed nodes are available to you again.
This save function can be achieved automatically in the running workflow by using the Save Workflow node. This means that all data of nodes that have been executed up to the deployment of the Save Workflow node will also be saved.
Implementation:
This fact is exploited by the DCoC component that contains this Save Workflow node. It can be used like a Save Workflow node itself. All data of the nodes executed until the DCoC component is used were saved and transferred to a ZIP file, together with the meta information of the workflow and with its data. The original workflow is paused until the workflow is saved and the output Port_1 turns green. After that, the workflow can proceed to the end.
For the forensic requirements, the actual digital chain of custody, the saving has been extended by some aspects. Before saving with the Save Workflow node, additional meta informations were added to the workflow datasets with the Extract Context Properties and Extract System Properties nodes. In addition to this data the current time is recorded as timestamp.
After the workflow is saved, all this information were saved in a ZIP file. A sha1 hash value is created for this file. With the sha1 hash value and further components, e.g. previous transaction IDs, a transaction ID is generated for this individual workflow, with which the datasets could be extended at the end. The output Port_1 of the DCoC component provides this transaction ID.
Whether the hash value together with the transaction ID is entered into a database or a distributed ledger or is not used further at all is then a matter of taste.
Applied correctly to basically all workflows, this allows a relatively tamper-proof, reliable, reproducible and, through the KNIME concept, easily traceable process of data lineage. Data can be tracked from origin to completion result and back to origin, and even decades later if other circumstances are taken into account.
I hope with the deployment of the component in the coming week and some more background information on the subject, the application possibilities will then become a bit clearer.
Best Regards
Andrew
2 Likes
Hi @Andrew_Steel , thank you for the additional detailed info. Sorry, I missed the fact that you were using the Save Workflow node. I was focusing only on the data port of your component (metanode) as the discussion was about saving the data tables.
1 Like
Hi Andrew,
I was also wondering if this supports distributed workflows?
Scott just posted a link to the Workflow Summary on a different thread. Might be useful for you as well @azsb1g19.