I face problem when combine about 20 xlsx files (assumingly has the same format of all columns and rows) using Excel Reader. Those files were taken from different people as they are supposed to provide some inputs into the files. sometimes the file owners made mistake by changing the format or forgot to delete extra column that they created. when I combine them, it shows error (red cross). I had to go through it one by one to find out which one and it is time consuming. is there a way to quickly detecting which files that cause the error and what error that it causes so I can go to the files directly and fix it?
Which version are you on?
In KNIME Version 5.x there’s the new Workflow monitor, which shows errors and allows you to click on them to take you straight to the node that failed:
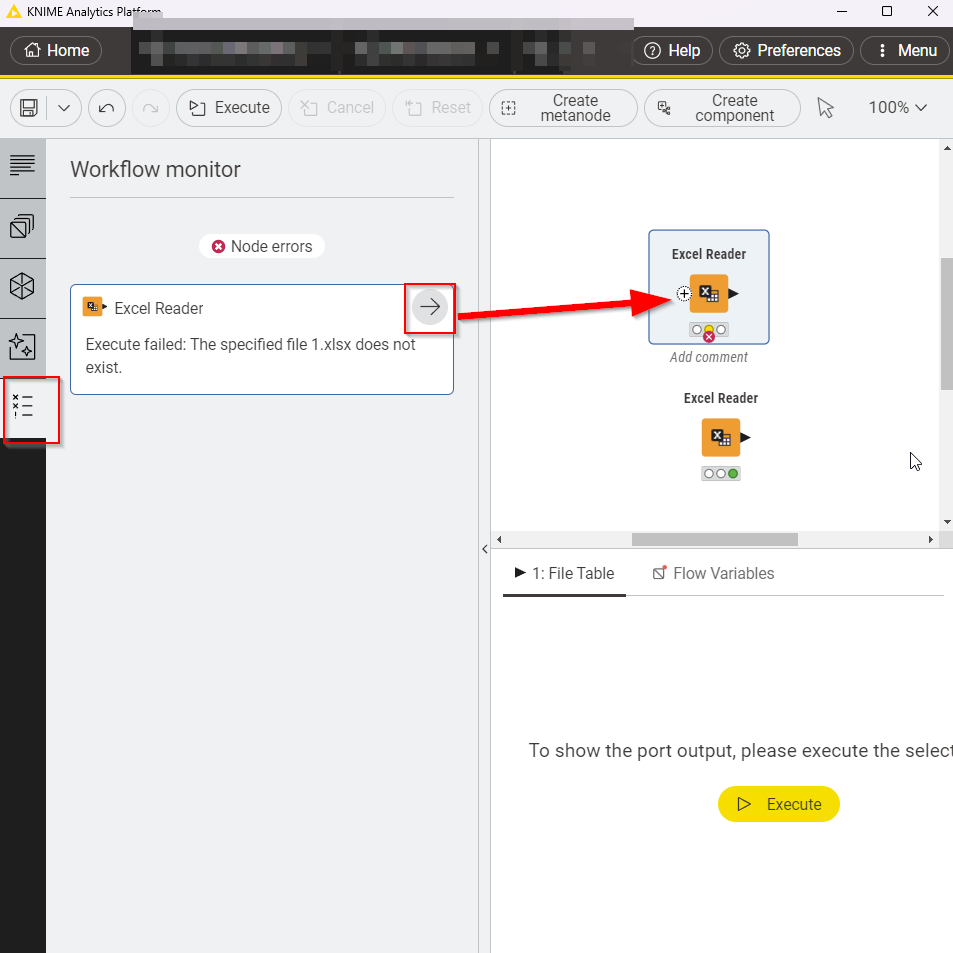
Thanks, Martin for this suggestion. However, let’s say among 20 files, there’s 2 files that has extra columns or different columns.
one file has additional columns as “Extra A, Extra B”
another one has additional columns as “Extra C, Extra D”
the workflow monitor will only tell me that there’s extra columns A, B, C, D. but I have to check one by one which while that these extra columns belong to
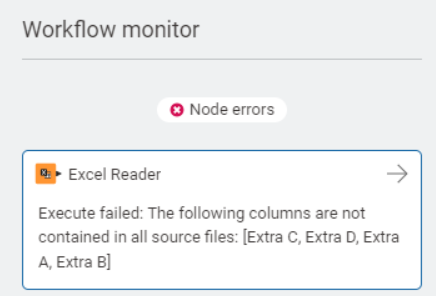
Can you share some details on your set up?
From how I read your initial post I assumed that you indeed have multiple Excel Readers set up (in which case the monitor could be helpful).
If you have configured one Excel reader to read all files from a directory or if you have one Excel reader that is nested inside a loop the solution may look different and indeed the monitor is somewhat useless :-).
One thing you may want to try is to use the Transformations tab to uncheck “” - this may actually exclude New A, B C etc…:
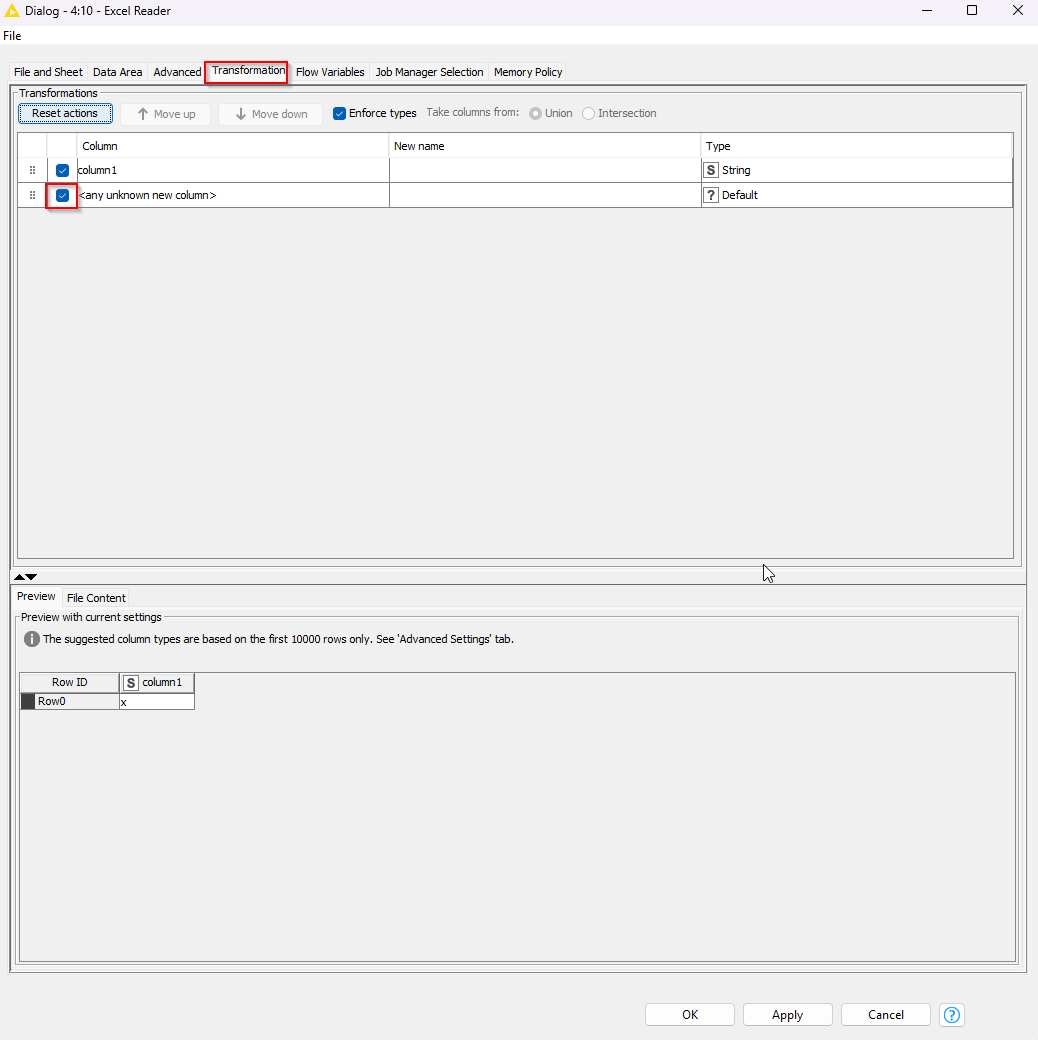
@MartinDDDD ,
In my case it does not appears like yours. Mine is empty both “File and Sheet” and “Transformation” sheet.
I have create testing files as below.
2 of the 4 files has extra column. If you put them in one folder and read them in excel reader, it will cause error.
your advice is really appreciated ^^
File 1.xlsx (9.5 KB)
File 1.xlsx (9.5 KB)
File 4.xlsx (9.6 KB)
File 5.xlsx (9.6 KB)
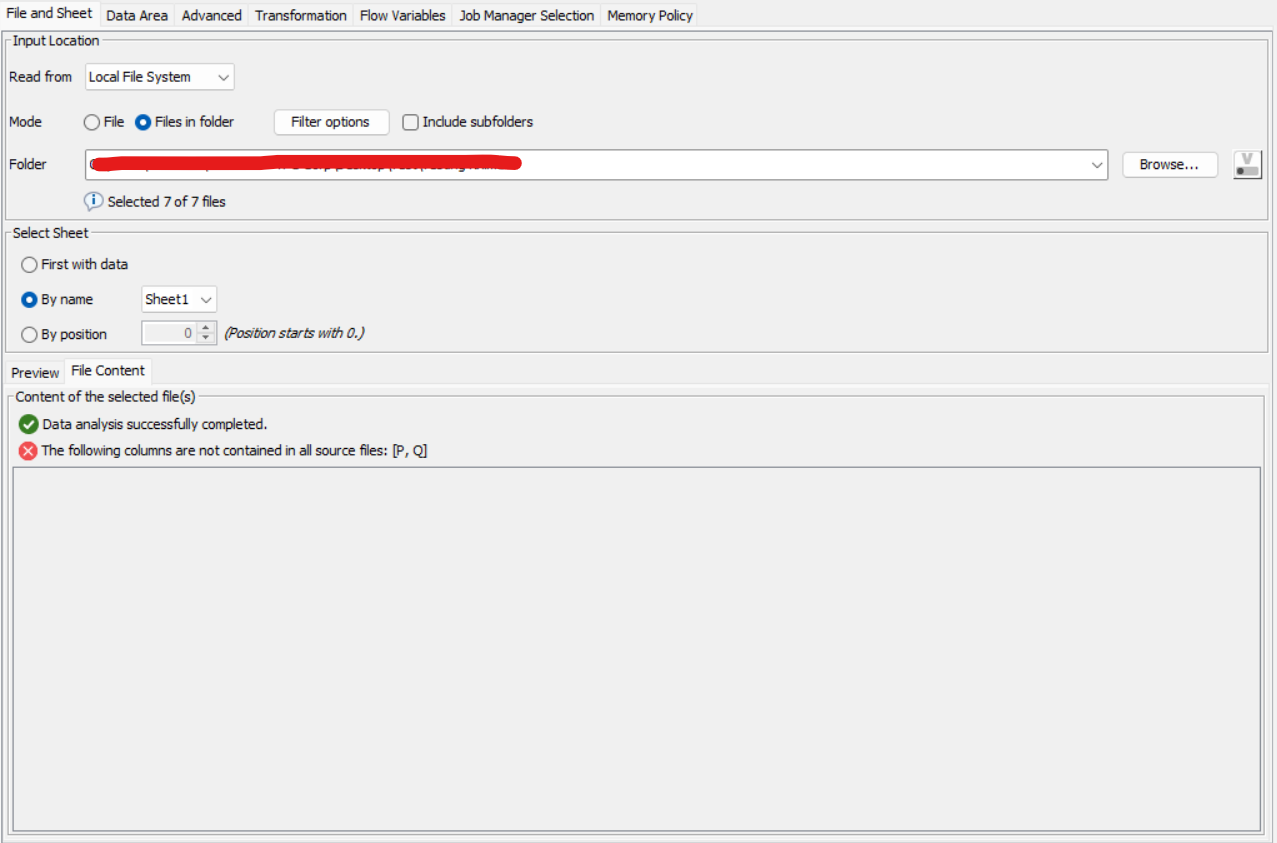
Thanks for the data - indeed for your set up my suggestion from before is not working - this would only help inside a loop.
I found a way where you don’t need to worry about an error being thrown or columns to be added “to the right”:
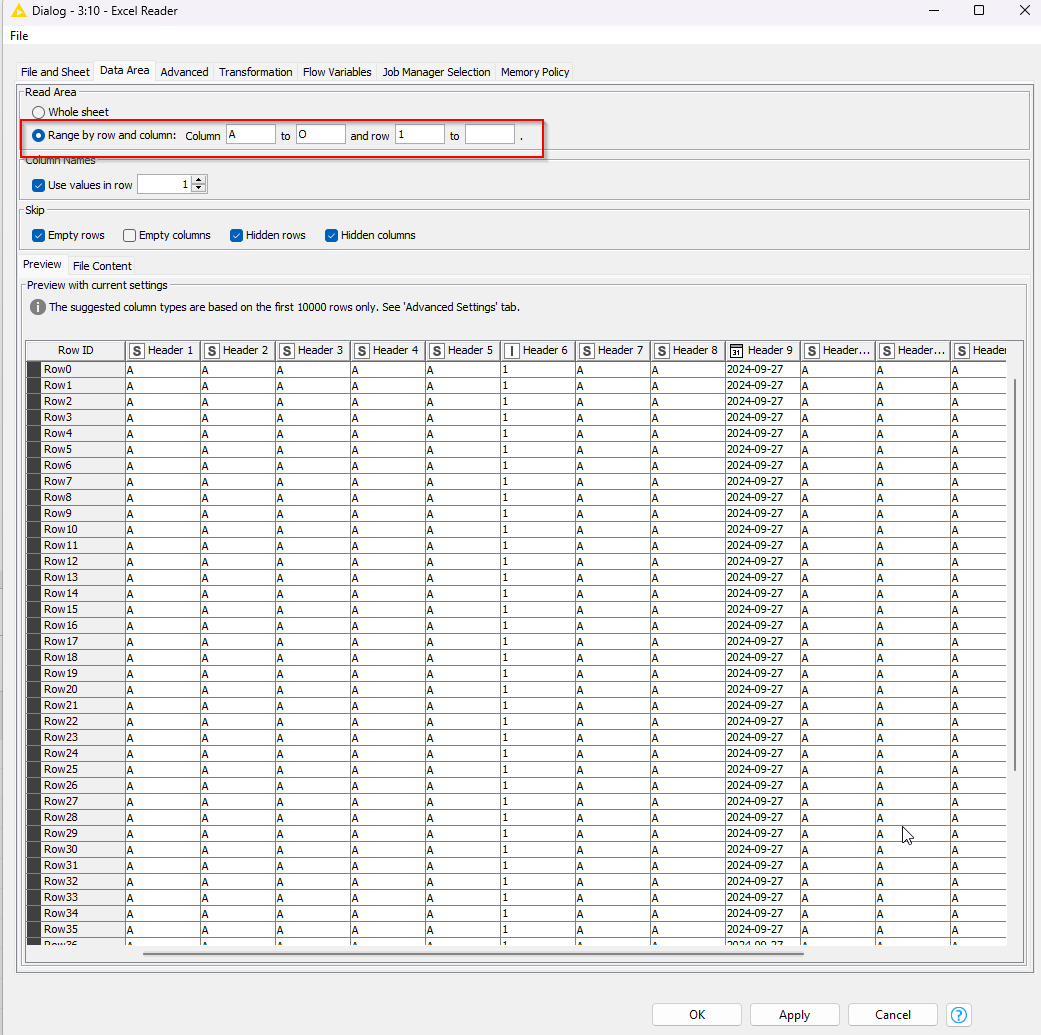
Go to Data Area => check Range by row and column. Based on your test data, only columns A-O are relevant so I limited reading to those.
I know this still does not address your original question. I think only way to truly make it easier to find which file is causing the issue (in a case where people start adding columns in the middle of your spreadsheet instead of only “to the right”), is to write the files file-by-file inside a loop. That way once a file is failing you can track the filename via the flow variable you are passing to the Excel reader.
Hope that the above method fixes your troubles though!
1 Like
@MartinDDDD
Today I have learnt this trick which is very useful for me ^^
This will help me survive. ![]()
you are right. If the extra column will be added in the middle instead of to the right, I might have to find another trick.
But is there a way we can notify KNIME to make “Workflow Monitor” shows both file name and extra columns that causes error in later updates?
I think this extra feature will be very helpful.
I love KNIME.
I love this community.
Thank you so much Martin ^^
1 Like
You are very welcome!
There is the Features & Ideas category - you can open a topic with your feature request there (maybe link this topic as a reference):
People can then provide feedback and “upvote”. I have it from good authority that the KNIME team really cares about community feedback and leverages the Feedback & Ideas section (amongst other things) to prioritise there backlog.
4 Likes
Hi @mysteri_guy , Following this topic gave me inspiration for a new component:
You can see it in action in the following workflow
I included your files (renaming the second File 1.xlsx) in the demo workflow’s data area.
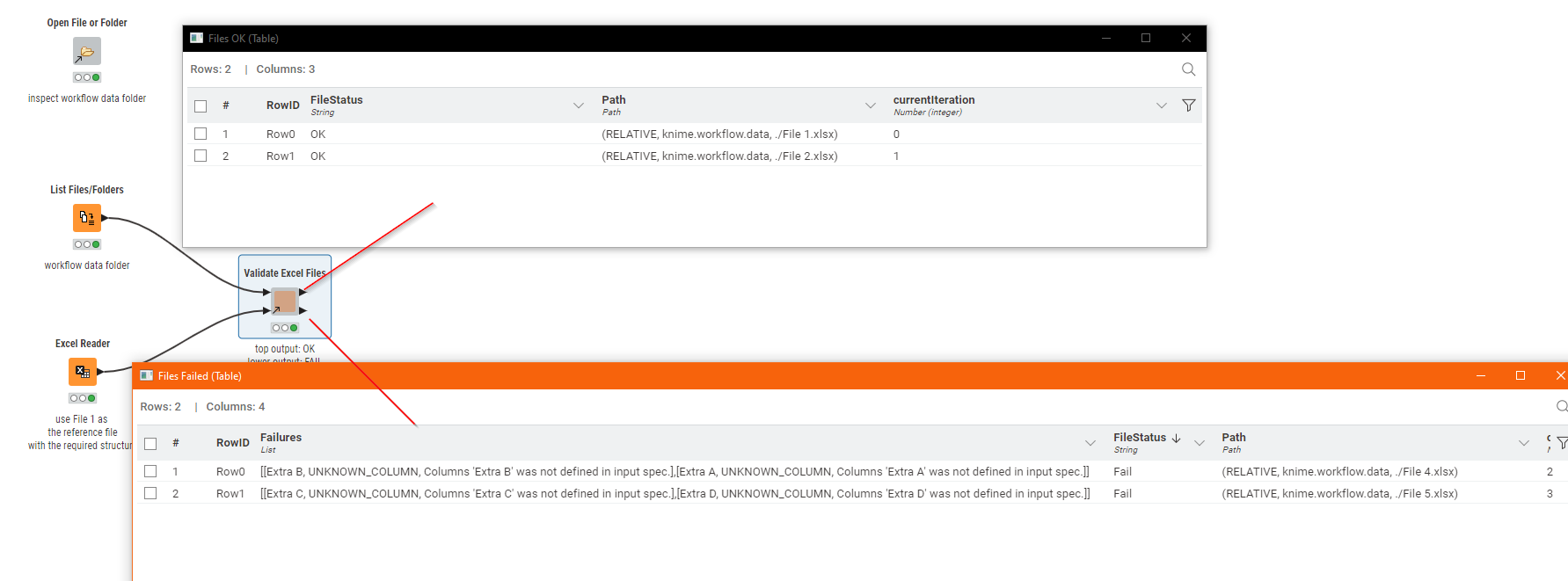
What the component does is make use of the Table Validator (Reference) node which can compare a table with a reference table and return details of any errors in the table specification (e.g. missing/additional columns).
Putting this in a loop, we can test each excel file in a list of supplied paths and compare them to a reference table (or a known “good” file) to build up details of which are OK and which fail.
This is the internals of the component which you can of course have a play with in the above workflow, or adapt to your needs if it doesn’t quite do what you require:

My thoughts are that you could use this component as a “pre-processor” to ensure your files are in the correct form before then embarking on the main process. For expediency, at the moment the component assumes that the supplied Path column will be named “Path”. I may add this as a configurable column selection in a later version.
Edit: An additional thought, with the above you can quickly abort downstream processing if any files fail validation, by adding a java snippet onto the lower port of the component. Code the java snippet as follows:
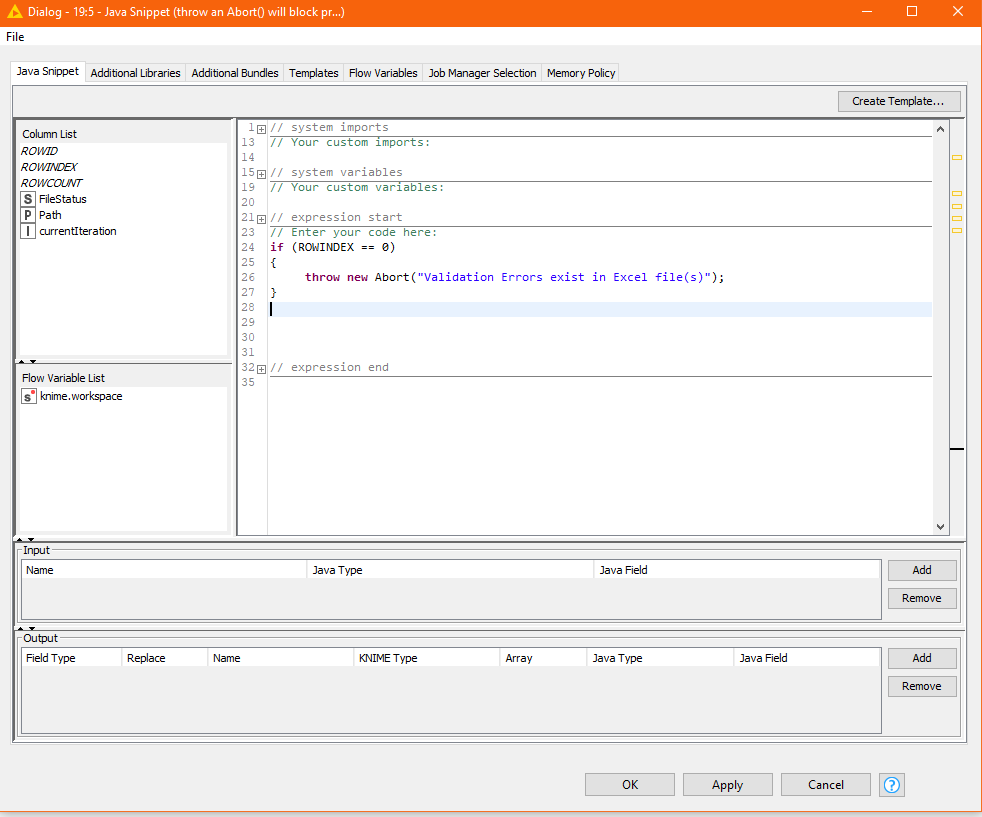
if (ROWINDEX == 0)
{
throw new Abort("Validation Errors exist in Excel file(s)");
}
Then if none of the files fail, the java snippet simply warns that it has created an empty table (as there were no rows in the “failed” set of files), and further processing can continue.
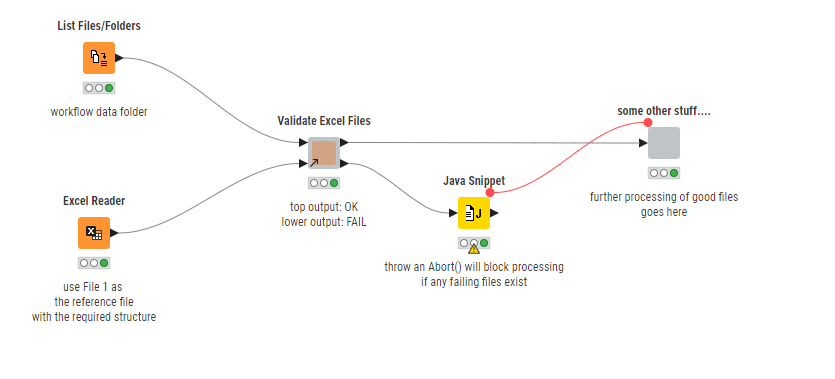
But if there is at least one failed file, the java snippet will create an “Abort” which will block the flow:
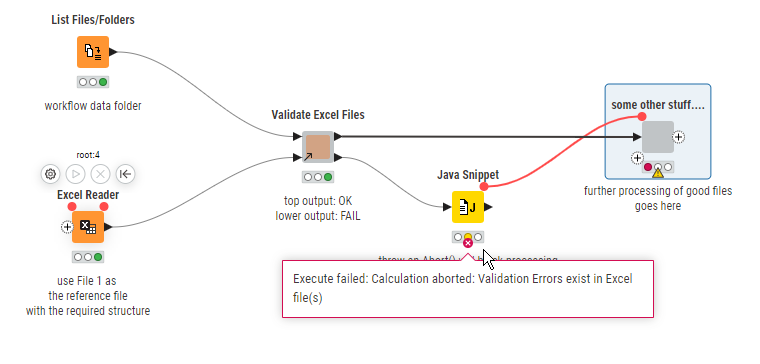
3 Likes
Thank you @MartinDDDD and @takbb,
the concerns above has been solved through the Validate excel file node.
However, as I further explore to read the good files into one data, I face some difficulty as I am only able to read each file address at a time and new one keep replacing the old one when I put them in loop.
but allow me to move this to different topic as I already recieve help and got solution to this topic.
Really appreciate your both advice
2 Likes
Hi @mysteri_guy , glad you have found your solution. I’m adding this here because you already got the general solution to your additional question on the other post but I have uploaded a more advanced version of the above component, which may assist with your specific workflow.
This component has a third port onto which the collected data from all the successfully validated xlsx files is returned, so unless you have some specific Excel Reader settings you need to set, you don’t need to re-read the files.
The new component also has additional config options, and validation (for the required sheet not found for example)
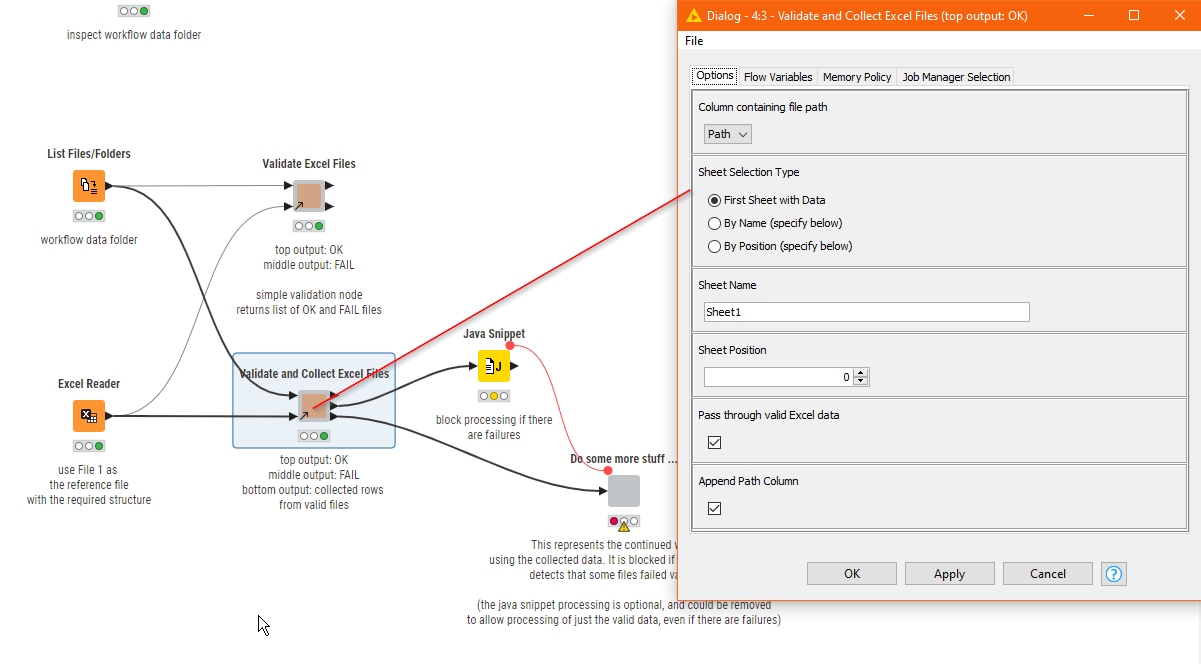
I updated the original workflow I put on the hub, with the new component to demonstrate it.
1 Like
Thank you @takbb for the upgraded solution.
I am actually quite new (about 2 months old in KNIME). There are many rooms for me to explore and I hope you don’t mind my below questions.
I noticed you have come up with new nodes whoch couldn’t be found in Nodes pool in KNIME 5.3.2.
- Is my assumption correct that new nodes can be personally created and customized by any user?
- Will such exclusive nodes be added to official knime in later updates? I also notice some customized nodes were created before but never got integrated into node pool in official KNIME updates. Could you advise is there some reason i should take note?
- If point #1 is true, is there a way I can find guidance to further explore this?
I really love KNIME. Being able create new nodes to accommodate any specific nodes is eye-opening and far reaching for me.
But maybe it will be come my mental goal. Maybe I keep learning and might be able to reach this level one day.
Thank you
hi @mysteri_guy , well welcome to KNIME ! I hope you find it as interesting, useful and rewarding as I and many other people find it.
Let me explain a little… KNIME has nodes, which you will find in the node palette and you can also add additional nodes by installing “extensions”, and these nodes will then appear in the palette in your KNIME installation.
But KNIME also allows you to build workflows and group together some of the nodes in a workflow into what are called “components” and these are a bit like you might think of macros or procedures in a regular programming language.
They aren’t nodes as such, but rather a packaged collection of nodes, but they do look and behave to an extent similar to nodes.
What I have uploaded to the Community Hub are components, rather than actual nodes. And by uploading them to my public area on the community hub, I have made these components available to anybody who wishes to use them.
But as components, they don’t appear in the Node palette, and if you want to use a component again and again in different workflows, you either drop it from the hub into each workflow, or you can copy/paste from one workflow to another. So components are reusable packages of nodes, but are kind of “second class citizens” as they don’t get to live on a convenient palette. (Note to KNIME team - I wish they did!)
It is true that nodes can be created by any user, provided that you install a development environment and any necessary extensions to enable this. New nodes can be written using Java or Python but do require some technical knowledge. You can create nodes for your own use, or build an extension that ultimately you can make available to other people if you wish.
However, as mentioned above, I haven’t created new nodes, but rather have created components. Components can be created by any user of KNIME without requiring a development environment, and are built totally within the regular KNIME Analytics Platform application. Components can be quite complex, and can be made configurable, although there are greater limitations on what you can do than when you are building fully-fledged nodes. Once you have built a few components, you can find them quite quick and easy to build.
Components such as the ones that I build are never added to official KNIME releases as they are simply a packaged collection of existing nodes, and don’t appear in the node palette themselves.
Nodes which are built directly from java/python using the required frameworks could potentially be added to an official release, but the core nodes in the KNIME releases are most likely (always?) built and maintained internally by the KNIME developers. Third party nodes form extensions (partner extensions and community extensions) which can be installed separately through the “install extensions” menu, provided that they have been made available to the update sites.
Some of the extensions are created by close technology partners of KNIME, and get more thorough testing by the KNIME team, while others are provided through the wider community. see KNIME developers.
Certainly. Starting with components, you can find a guide to building components here.
You may also find this video a useful quick introduction:

There is also a Components “Cheat Sheet”
Finally for components, there is this useful guide to best practice for component building. It was written back in 2022 and so the screenshots are the older “classic UI”, but the points made and suggestions given are still valid
For the more advanced topic of building actual nodes there are two avenues to explore, java and python:
JAVA: https://docs.knime.com/latest/analytics_platform_new_node_quickstart_guide/index.html
PYTHON:
https://docs.knime.com/latest/pure_python_node_extensions_guide/index.html
The general documentation link for KNIME is here:
https://docs.knime.com/
I was formerly a java developer but have yet to set about writing some actual nodes, although I have some ideas for when I get some spare time.
So even as a former programmer, the ease of component building is a great thing for me, and an appealing feature of KNIME. If I ever come across a piece of processing that I think could have wider appeal than just the “current workflow”, and also may also be of use to others, I package it up as a component and share it on the hub. I already have uses of my own for the excel validation component that I uploaded for you! ![]()
I hope the above has been useful, and look forward to seeing your future components or nodes that will benefit both you and others! ![]()
5 Likes
Wow… this explanation is not a little ![]()
I benefit a lot from your advice.
This will help me clear so much fog on my road to be a better KNIMER.
Let me spend some time to explore further.
I am so greateful for you guys’ advice.
Love this community.
3 Likes
HI @takbb
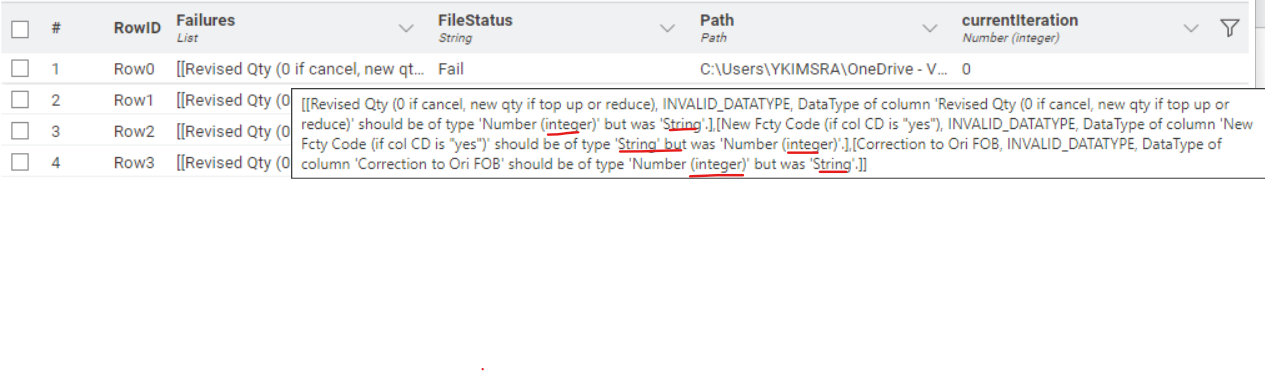
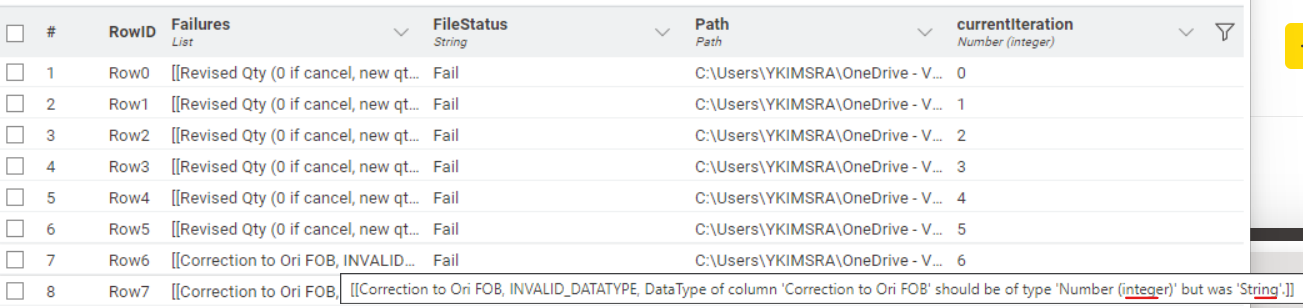
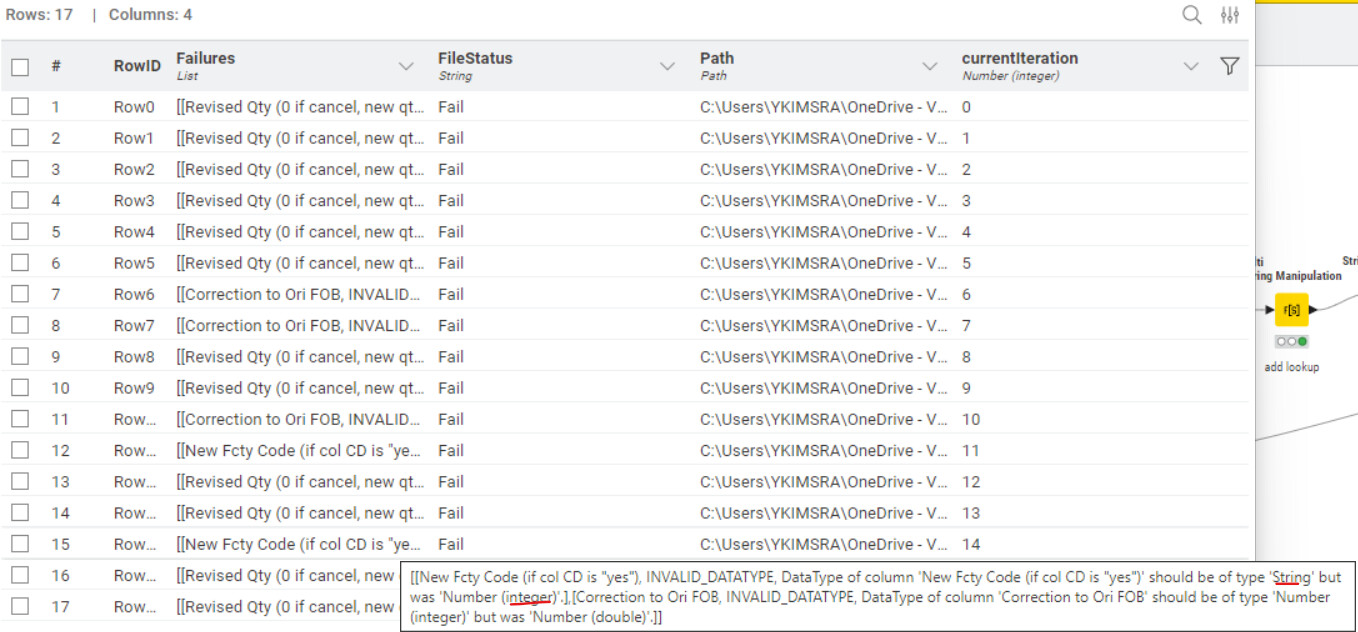
After doing the testing in real data, I found that some files that are ok to combine in Excel readers, are categorized to be failed files in the component above.
When I check it was because the data type difference (Number integer VS sting VS Number double) from that reference file and the list files.
The reason the list file can be combined in normal excel reader might be due to the configuration in “Transformation” sheet that I change data type all to String.
but in the listFiles/folder node, I can’t do the transformation since it shows on the path type only.
The number data in those columns are not used to calculate and can be change to either string or number
Instead of going to the source file to change it one by one, is there a way I can set a data type in reference file to be a data type that can accommodate both string and number?
or any configuration to ignore this?
I remember in Power query, there’s a data type “Any type” that can accommodate all type of data. what is that Any type in Knime language?
Thank you
Hi @mysteri_guy , I will modify the component to handle this. I need to work out a good approach, which may be simply to return all data as String from the Excel reader (which is effectively your “any” type), and then your onward workflow can handle it.
I am thinking to add an option that will allow you to choose if the data is to all be returned as String, or an attempt should be made to return it as the same data type as the “reference table” that is supplied on the lower port. When I get a chance later I will give you an update.
1 Like
Hi @mysteri_guy , please update the “Validate and Collect Excel Files” component.
It now has additional options which will hopefully allow you to work with your files.
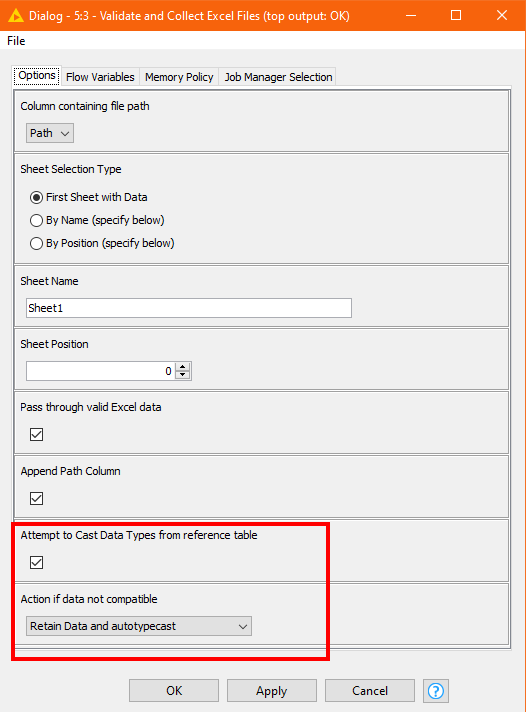
New options, from the component documentation on the hub are as follows:


3 Likes
Thank you @takbb.
Allow me to test and explore it further.
Really appreciate your advice ^^
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.