I’m completely new to KNIME. Actually I found less than 8 hours ago this tool searching in how to scrape categories and sub categories from a website and I reached this thread.. At least in theory what I try to do is similar, but was not able to reproduce the solution provided in that thread. I’ve imported the solution file and changed the initial URL from dusseldorf.shopdutyfree.com/en/ to zurich.shopdutyfree.com/en/ since dusseldorf it seems is not there anymore and failed.
That was only to try to understand, but my case is that I’d like to create a flow to get the addresses of each location in each state/city from a site like this and some site other with similar visual structure.
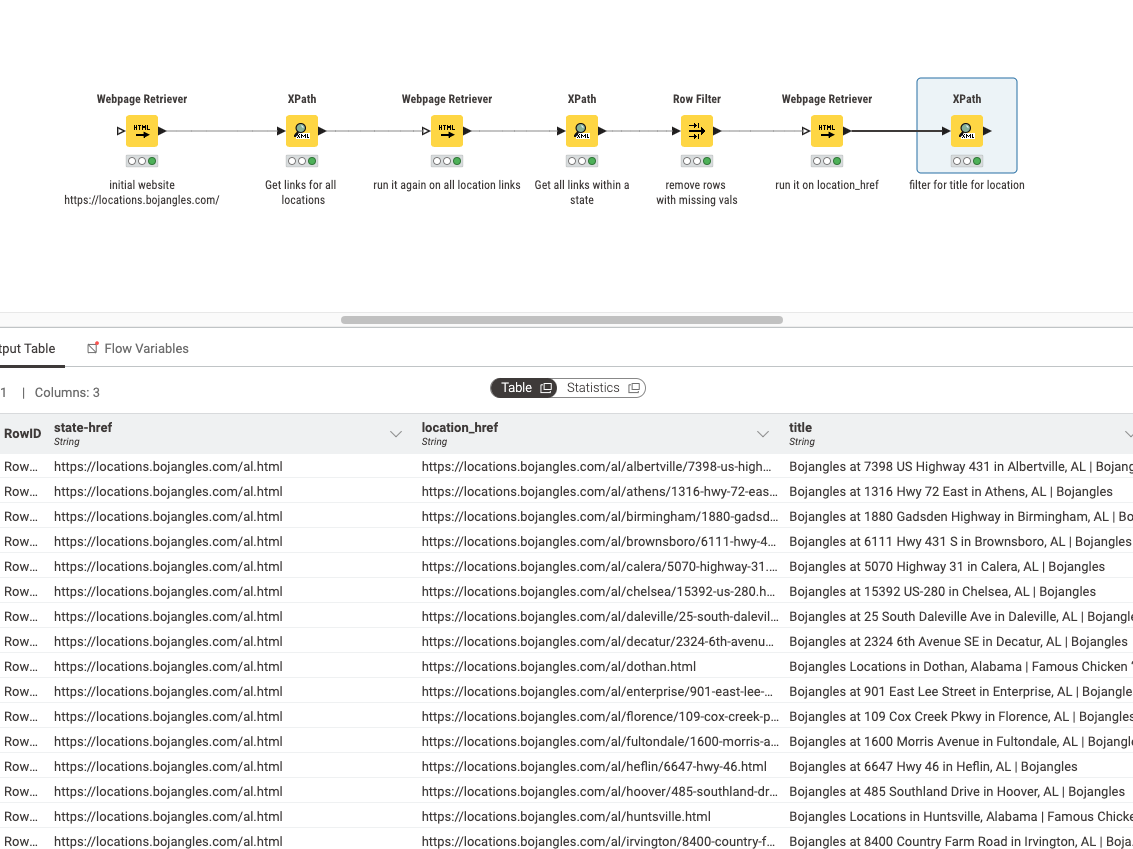
So just based of that website you wanted to work on to get addresses, I created a workflow to get you 90% of the way to what you want. It follows the same idea as the thread you linked, and we just first filter out for all the relevant hrefs. You will need to use the xpath node to do this. Here is some reference material on syntax for the xpath node.
You can see the process for extracting that info by using a webpage retriever → then parse the xml for only the info you want → run webpage retriever again on those links… until you get the info you want
I will leave it up to you how you want to extract the locations and handle any edge cases.
I’ve tried your solution. I begin executing each one and only first and second node are executed correctly, but the 3rd node (the second Web Retriever) shows this error
Additionally I’m curious about something. When I see for second node (Xpath), in “settings/XML-Cell Preview” I see that only the first line is the xml header and the rest is the HTML of that URL, but is different compared with the HTML I could copy from “rigth click/view page source” in chrome. Then, how is cleaned the HTML shown in “XML-Cell Preview” of Xpath node? Thanks again
So that error usually indicates some problem with the network, I can verify the workflow works as I have re-imported it and it runs fine on my end.
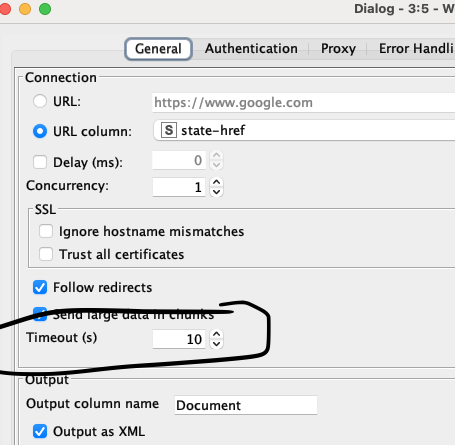
I would first try increasing the time for a timeout on the config on that second ‘Webpage retriever’ node:
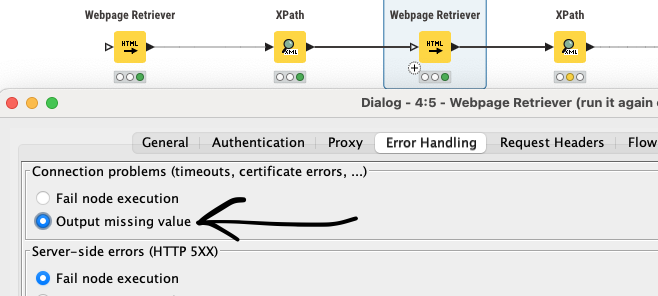
If that does not work, you can try changing the error handling to just output a missing value for that particular url.
It is more of a workaround, but it will give you an idea on which links are giving you a problem. Are you able to navigate to those links manually through your web browser? (you should be able to copy paste any of the links from the first xpath node to the browser)
For your second point, so the ‘Webpage Retriever’ node actually converts that HTML you see from using inspect to XHTML to follow XML rules (which is why we can use the XML query language on it through Xpath). I am not sure on the specifics of how the webpage retriever cleans and converts it to XHTML.
Thank you again @thor_landstrom. I’ve tried your suggestions and only changing to Output missing value works in first 2 Webpage Retriever. In the 3rd Webpage Retriever appears java.net.SocketTimeoutException: SocketTimeoutException even timeout is set to 20 seconds. Is weird since in browser it loads without issue. I’ll try to follow your algorithm with other tool. Thanks again!