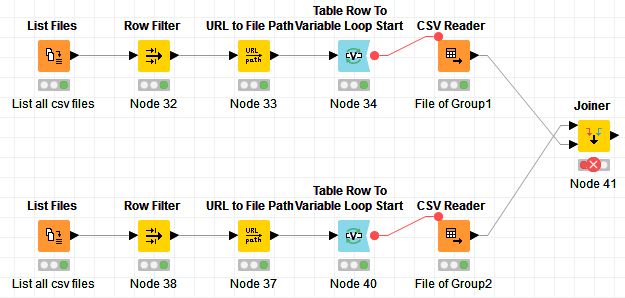
I have two file groups, both are including several hundred CSV files.
Now, my task is simply to merge two files from each group, and then export the result to new files.
The solution would be to use a Joiner node to merge with a key column in a dual loop.
But I don’t know how to create and control a dual loop to do this operation.
As a test I simply created two loop (not dual) to read files from each group, and then try the Joiner.
This operation receives the following error.
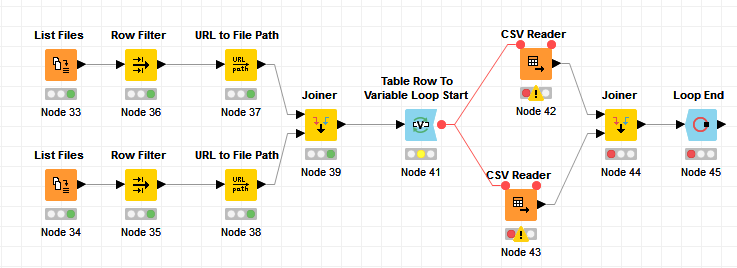
You are right, the error should be solved if I end the loop before Joiner node.
But I have anther thing to worry about.
Each group contains csv files larger than over 4GB. The total file size is very huge.
If I end the loop right after CSV reader, I think all files will be operated on memory here.
Is that going to be operated properly?
I’m not sure about that, so currently I’m considering finding a way to do the merge in loop, operated file by file.
The target is to merge the columns from each file. The merge key is a Date&Time column which has been prepared in each file. I don’t know whether there is other nodes instead of Joiner can do this or not.
Maybe to end a loop for only one CSV Reader (in a dual loop) would properly work well?
I don t know the structure of both csv files. But if the total records in both files matches and they are in the same order on your key-column then you can use a Column Appender node instead of a Joiner node. This will speed up the matching part.
Thanks for your reply.
I have tried what you have suggested and finally failed. But I think perhaps it can be done if I could make some change to the workflow.
I will prepare for uploading my workflow later with a part of data (which has been normalized), help to understand the data and the workflow operation.
Thanks for your advice.
The total record and the key column are different, so Column Appender should not help in this task.
Please find the workflow with the data which I will upload in next reply.