New to KNIME. I’m trying to test out web crawling using HttpRetriever and htmlparser, but I can’t get past the HttpRetriever proxy error: statuscode 407. I have configured the network setting and it works fine with GetRequest node, and that route worked. I found some similar topics but it was not clear to me if HttpRetriever could work behind the firewall. Any clarification would be highly appreciated.
Hi there,
in general we rely on the KNIME-specific configuration for the proxy server, so if other nodes which access the network work just fine, the HttpRetriever should do as well.
As this is obviously not the case: Could you post an anonymized screenshot/description how your proxy configuration looks like?
Thanks!
Philipp
1 Like
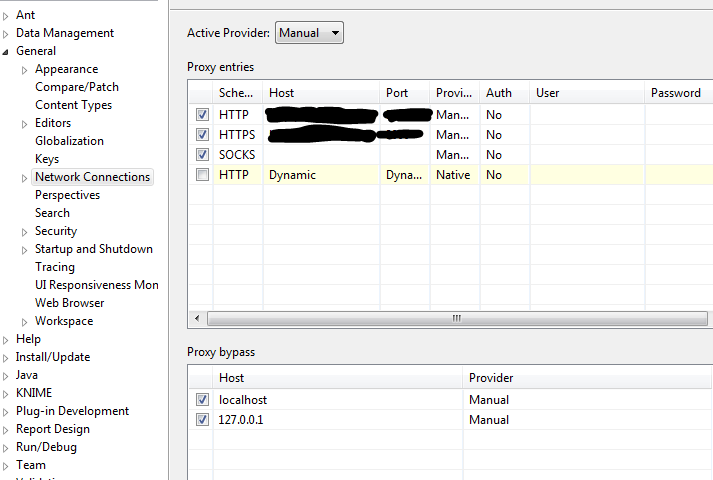
I’ve just given this another try in my local environment using a squid proxy. There, everything was working fine and I can at least rule out any regressions in the HttpRetriever node.
Debugging this kind of issues is unfortunately quite tough, as it’s hard for me to simulate your exact proxy configuration. Could you probably run your workflow again and check the log file whether it contains a line which says Using proxy: host=… (or alternatively whether there’s a line which says Using no proxy, which should not be the case)? (please make sure that file logging is set to DEBUG; here’s some instructions where you find the logfile).
Btw; HTTP status 407 actually means “proxy authentication required”, but in your screenshot there’s no user/password configured for the proxy. So, sorry for repeating: Within the same environment, other functionalities which are accessing the network work fine? (e.g. the REST nodes, or also the KNIME-integrated update functionality)
If you could share the relevant parts of your KNIME log with mail@palladian.ws that would probably help to get some more insights. If that’s not possible due to privacy concerns, I fully understand.
1 Like
@leahxu Do you have any input for me?
1 Like
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.