Hi @badger101 , no problem.
I don’t know how much it took me, probably less than 30 mins… It’s not a big workflow and there’s not a lot of data.
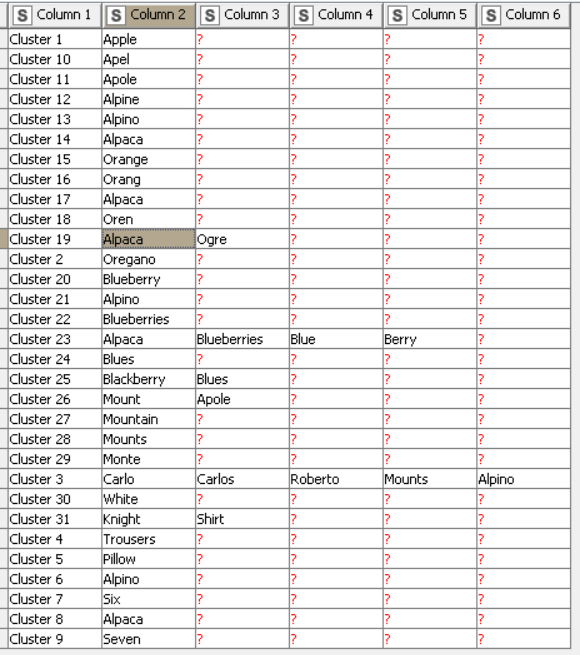
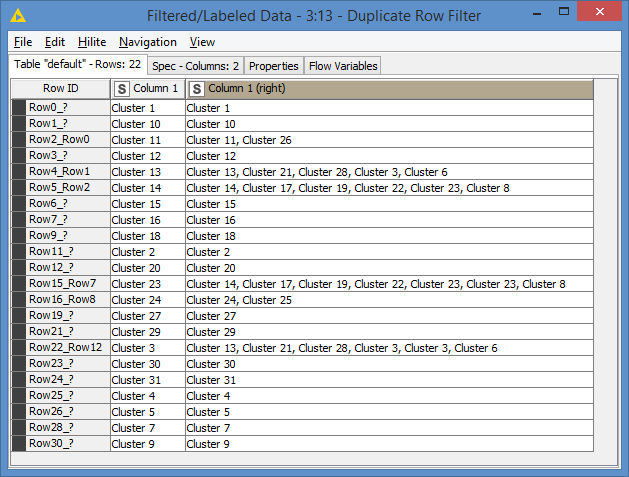
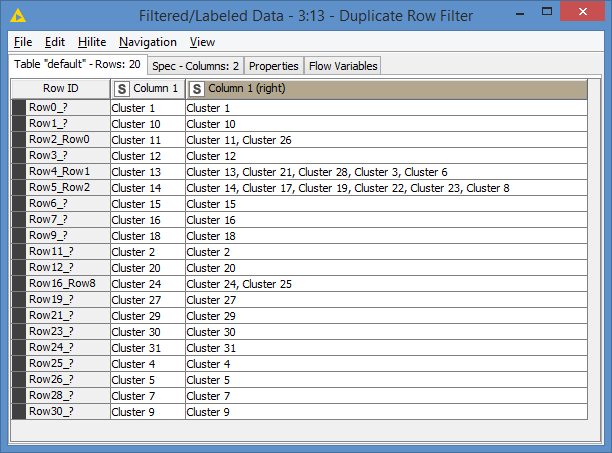
I had a clear idea of what approach I wanted to take since the beginning. Once this is set, it’s pretty easy after. That is why it took me just a few seconds what to modify (Node 12 + Node 13) after your additional clarification. Similarly for the duplicates, I knew exactly where to fix this (Node 8 had to be adjusted).
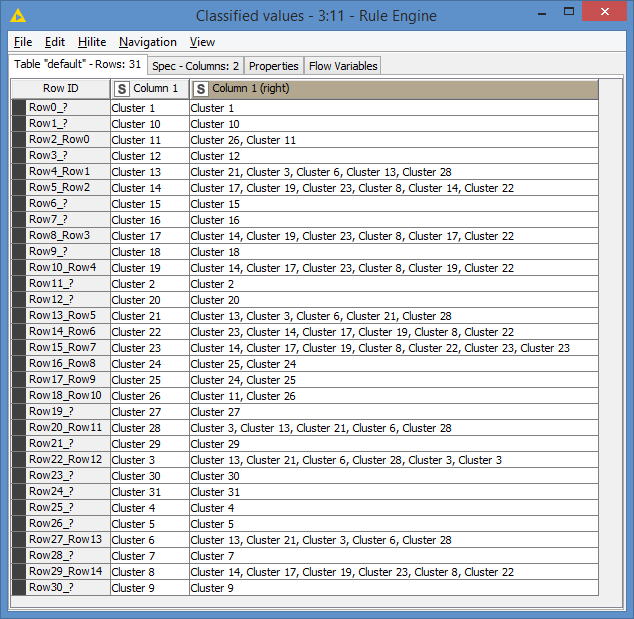
Of course, you can uncover some challenges as you start implementing, but in most cases the challenges are solvable. For example, I was trying to find a way to “merge” my results after the 2nd join. I started going towards Rule Engine in my mind, but then realized that doing a Concatenate will do this for me.
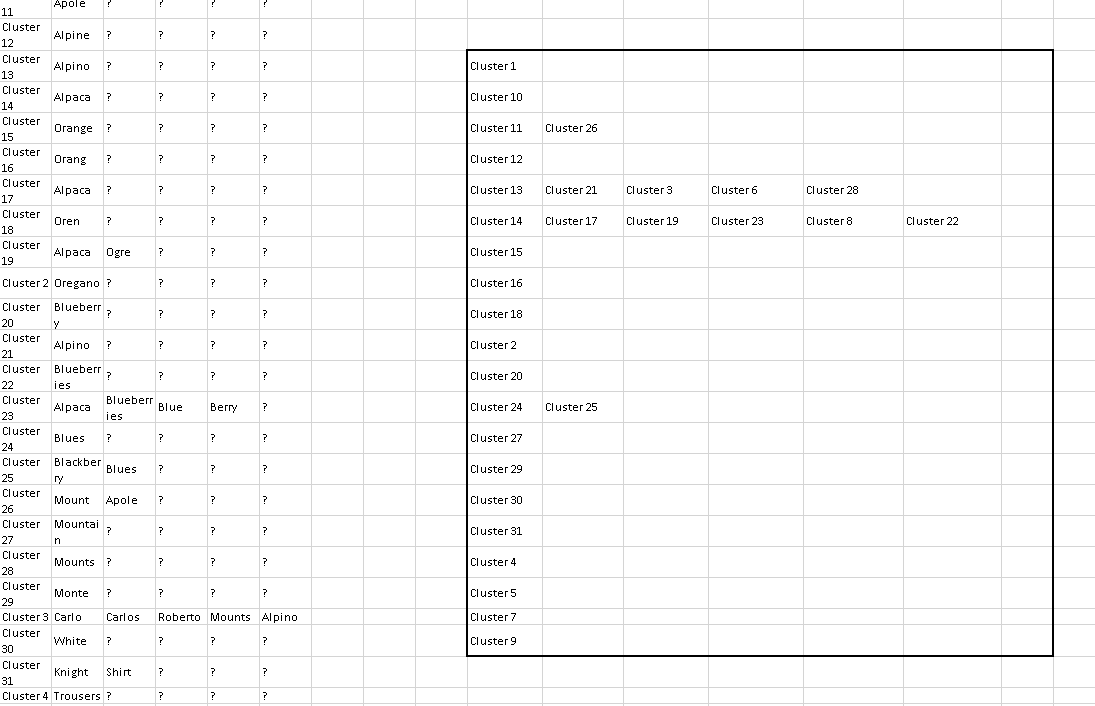
I can see why you used the Cross Joiner node - it’s basically a 2-way relation, but using the Cross Joiner will break that relation, or rather create a relation between every record.
The proper approach is using 2 inner joins, or at least that’s the approach I used.
These 2 joins being inner joins meant that they would include only those who had a relation, hence why I needed that 3rd join which is a left join in order to include those that did not have a relation.
I think this can still be optimized where we could eliminate the left join. There are 2 ways I can see this:
- Convert the inner joins to left joins, with additional transformation
or
- Modify the data at the beginning by adding a relation between each Cluster to itself
This was more of a “lazy” way since it was quite late.
The work itself took about 30 mins (Analyzing, thinking, implementing), but that spanned probably over an hour or so with the back and forth for clarification and my Knime and system being very slow (I’m running with about 2% space capacity  )
)