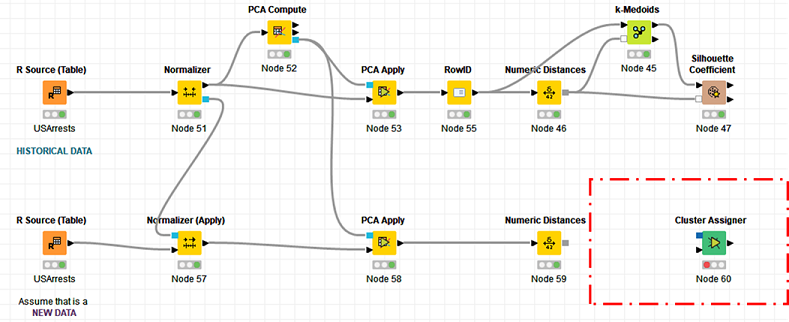
Hi everyone, I am trying to perform a K-Medoids cluster on new data based on historical data. This question is similar to this one, but I guess my solution cannot be done with a joiner node.
K_medoids Question.knwf (78.0 KB)
Best Regards
Hi everyone, I am trying to perform a K-Medoids cluster on new data based on historical data. This question is similar to this one, but I guess my solution cannot be done with a joiner node.
K_medoids Question.knwf (78.0 KB)
Best Regards
Hi @mauuuuu5,
To be honest: I don’t see how joining could be a solution to the problem. As your workflow highlights, the Cluster Assigner would rather need to compute a distance to the extracted medoids and assign based on the shortest distance. A join wouldn’t do that computation but check on equality instead, which isn’t what you are looking for.
Having said that: I don’t have a good solution available at the moment. You could try to get your New Data and the data of the second output port of the k-Medoids node into the same table. Once you have done that, you can compute a Distance Matrix for all pairs of rows (which now includes the medoids). With the Distance Matrix Pair Extractor you can extract all pairs and filter for the ones that contain one of the medoids. Grouping by the data afterward you should be able to find the shortest distance and assign the cluster to the row.
Best regards,
Stefan
Hi Stefan thank you for your response, I will try the solution which I guess is similar to this one in StackOverflow:
In theory if you know the medoids from the train clustering, you just need to calculate the distances to these medoids again in your test data, and assign it to the closest. So below I use the iris example:
library(cluster)
set.seed(111)
idx = sample(nrow(iris),100)
trn = iris[idx,]
test = iris[-idx,]
mdl = pam(daisy(iris[idx,],metric="gower"),3)
So below I write a function to take these 3 medoid rows out of the train data, calculate a distance matrix with the test data, and extract for each test data, the closest medoid:
predict_pam = function(model,traindata,newdata){
nclus = length(model$id.med)
DM = daisy(rbind(traindata[model$id.med,],newdata),metric="gower")
max.col(-as.matrix(DM)[-c(1:nclus),1:nclus])
}
I will try, thank you
Mau
It’s exactly the same approach, as far as I can tell. If you are successful, it would make for a great component to share with the community: Let me know if there are any blockers that I can help you with!
Hi Stefan, I manage to make a workflow. I matched the historical medoids to the distances, then the distances on new data were calculated and then assigned the medoids. I am sure that I did not assign the medoids to the closest distance as they were the same, despite that I did some modification on the new data.
I beg if could you please check the workflow, just to be sure of the process.
Best Regards
Mau
K_medoids Question.knwf (276.0 KB)
Here’s what I had in mind for computing the distance to each medoid for each new data point:
Hi Stefan, highly appreciated. @hitorijanai here is a more technical solution for the k-medoids on new data
Best regards
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.