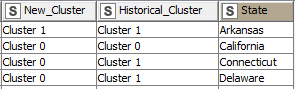
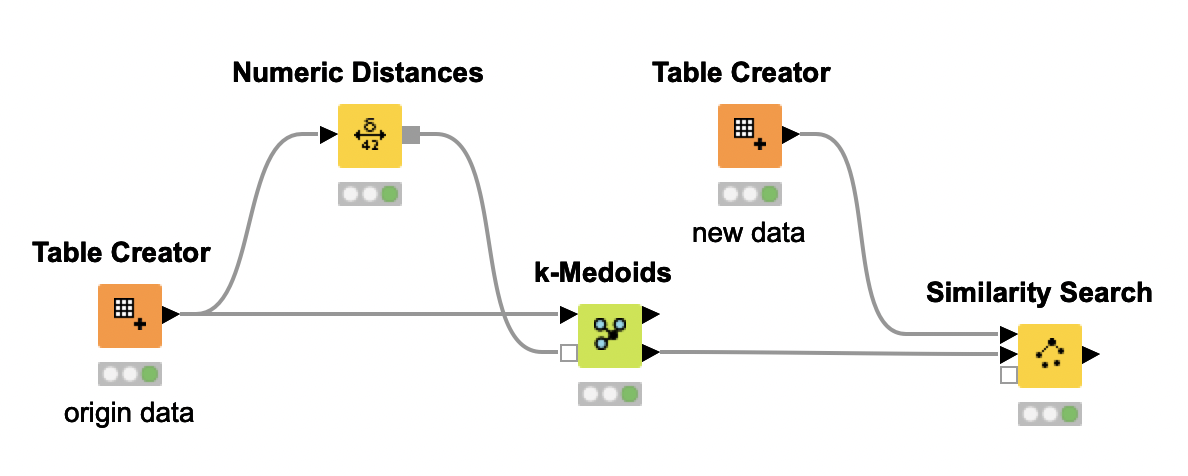
Hi there, I am attaching a workflow based on a solution to predict new K-medoids cluster labels on new data, this solution was provided by @stelfrichhere. I did a slight modification to the workflow to make a final comparison of the “New_Cluster” and “Historical_Cluster”, but the cluster labels do not match in most of the cases (60% accuracy), so I guess if probably I am missing something as it is expected to have more similarity.
Hi @victor_palacios, I am using an empirical approach to predict K-medoids clusters into new data, obtaining a 60% accuracy. I did a slight modification to add other algorithms, obtaining 100% predictions, when using the “Cluster Assigner” node
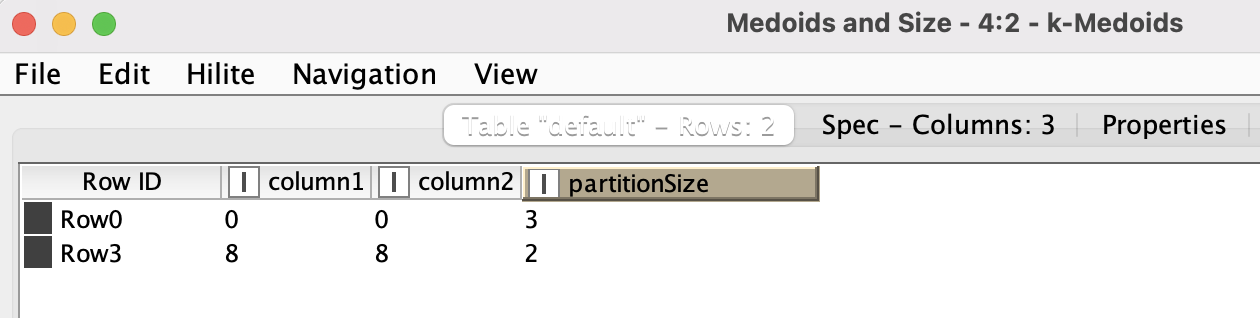
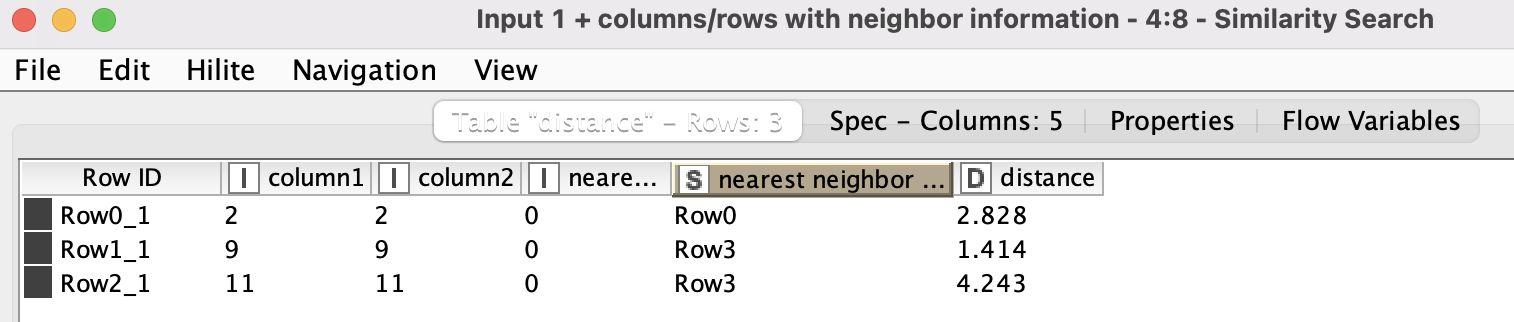
So I guess that I am doing a wrong calculation in the metanode, that is trying to make the same as the “Cluster Assigner”, but with the K-medoids algorithms.
In the screen shot notice that all the training data is given as input for the models (50 rows). This means the models are cheating (they’ve already seen the data and know the answers to the test/holdout set). In ML, we’d say the Weka Learners are overfitting the data. In contrast, the k-medoids is trying to find a pattern instead of memorizing the solutions so it gets a worse score (I suspect. It could also be that k-medoids is simply a bad model).
Make sure that your training and holdout set are different otherwise you cannot trust the results of your models. As well, 25-50 data points is not enough for a machine learning task typically. At minimum, I’d only try to train a model on thousands (ideally millions of data points) to find patterns especially those relating to crime which are typically controversial to model.
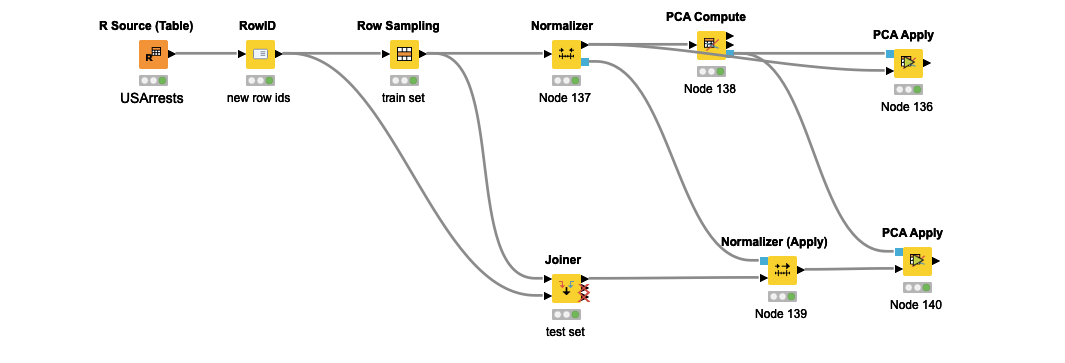
I’m attaching a way to split the data since the historical and the new data are actually the same from your R Source Tables. Notice the join is an antijoin so that you only get different rows with respect to your random sample. K_medoids Solution Forum(4).knar.knwf (21.4 KB)
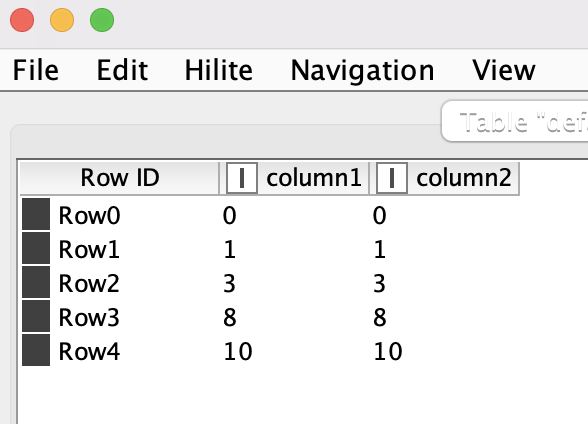
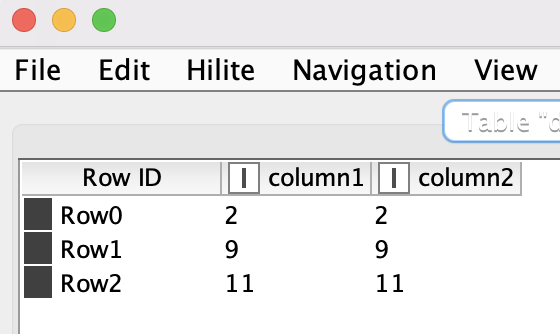
Hi, Victor thank you, for your help and advice, forgot to mention that I am using dummy data. My question or problem is how to assign Kmedoids clusters on new data? (since there is no Cluster Assigner node for Kmedoids)
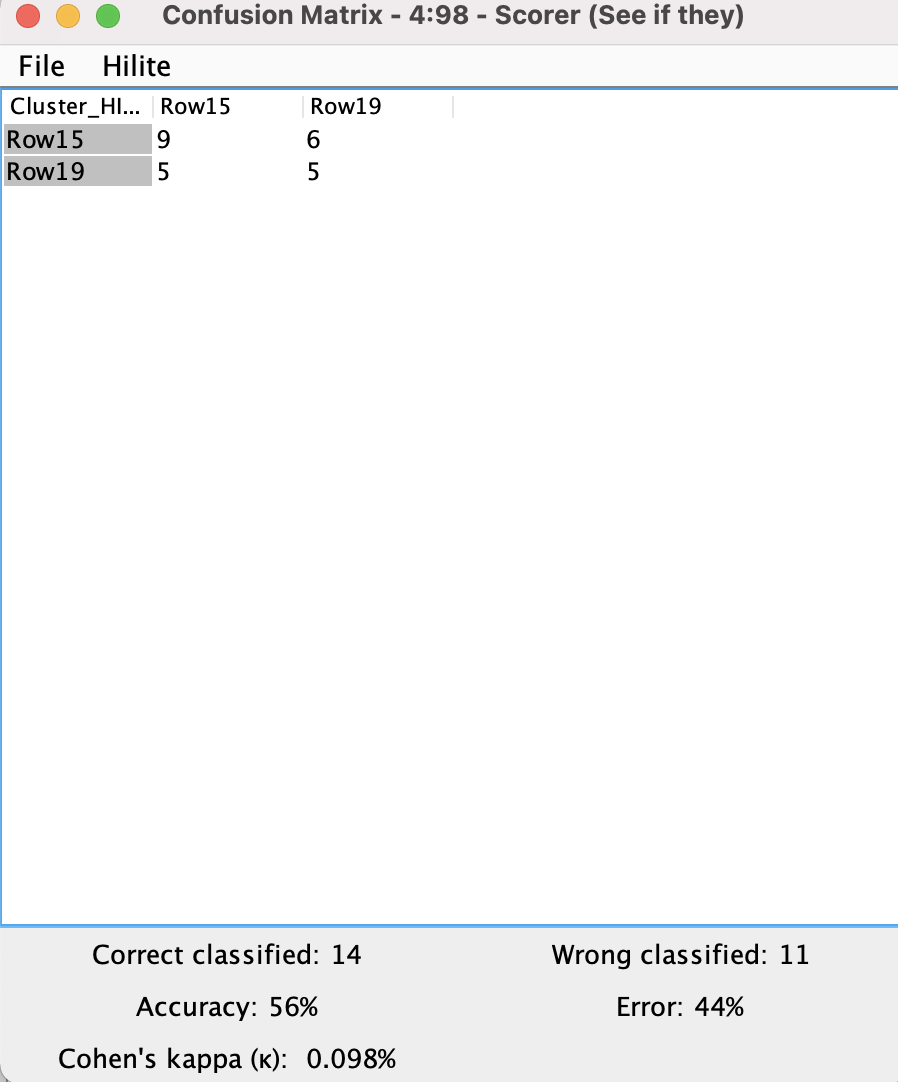
The first question was raised here by someone else, but the solution provided was not correct. Then I asked another question and someone from knime helped me to assign such clusters based on a forum response in Stackoverflow. After that I did a slight modification to the workflow to be able to compare the historical cluster versus the monthly cluster. Finally, I runned the solution (meta node that mimics the Cluster Assigner node for Kmedoids) but the cluster labels do not match in the same degree (60%) as the Xmeans (100%) and EM (100%) did, implying that the Kmedoids predictions are not correct.
I appreciate the workflow that you provided me, but in this case I cannot split the data between train and test, since I have to assign the labels on “new data from the same individuals” not on “unseen data from unseen individuals”. For instance, in my real case the cluster is trained with data that has montly frecuency with two years of information (24 months) for 1000 individuals, then when a new month arrives I apply the Cluster Assigner node to see the individuals that changed its cluster (Historical Cluster vs Montly Cluster). And in most of the cases the individuals remain in the same cluster, but I cannot do that with the Kmedoids since it does not have a Cluster Assigner node.
(1) Can you share real or fake data similar to the problem you want to solve? I’d like to see exactly how you set that up because of (2).
(2) the workflow you gave me had a serious error with respect to Machine Learning: the train set included the test set. Are you sure you are not doing that in your real life case?
(3) the k-medoid’s algorithm could simply be performing worse than the other algorithms and is not necessarily “wrong” - it’s just not great.
(4) You have the historical cluster and this month’s cluster and you need to compare historical cluster to this month’s cluster. How are you making sure that the centroids found in the new data map/match the historical clusters? Are you doing any kind of similarity checks? For instance if you were doing 2 clusters “a” and “b” how would you verify that new clusters created are similar to “a” and “b” centroids?
I just want to make sure I fully understand what you have/haven’t done.
The workflow in RAR with the data is uploaded here
My example does not use train or test set, as is an unsupervised problem, I just used the scorer node to check the accuracy of the cluster labeling
In the example that I provide both the: X-means and K-means have similar Accuracy and Silhouette, but the K-medoids have bad Accuracy with similar Silhouette, which implies that the labeling to the new data is probably not correct.
This is exactly what the metanode should do, but the results (accuracy) show that the cluster assignation is not correct while the Silhouette is similar to other algorithms that have a decent accuracy.