I am new to KNIME (I am used to spreadsheet software like excel so getting used to KNIME).
I am trying a simple iterative calculation here to calculate probabilities of exit (survival up to a given age and then exit at the given age). The feeds are age at start, age at end and the probability table.
Attaching a simple example knime workflow and supporting excel sheet for background. I have attached an excel showing my desired output but having trouble achieving the iterative calculation on KNIME.
It seems a bit odd, are you sure you want the survival rates of previous IDs to be aggregated into the current ID?
Please also include the xlsx file that’s loaded in your shared workflow, or don’t reset the workflow when exporting. The workflow is of limited use otherwise.
For reference, this question is related to this thread:
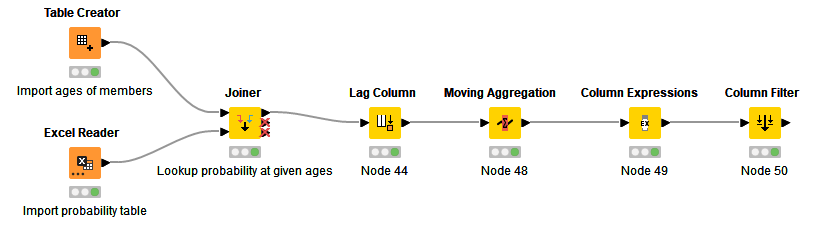
The approach I’d take is to zoom out and look at the big picture, then rethink how to do this calculation, step by step.
Here’s my thought process:
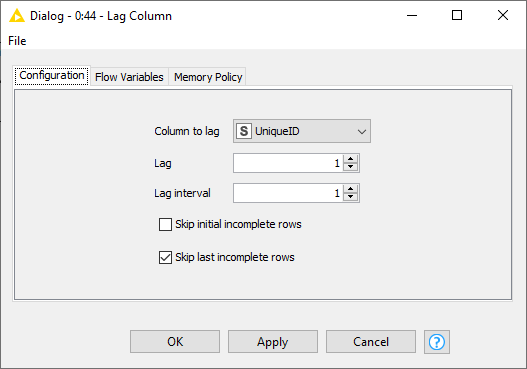
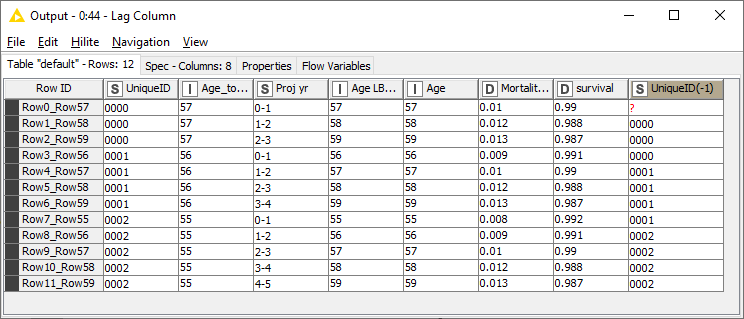
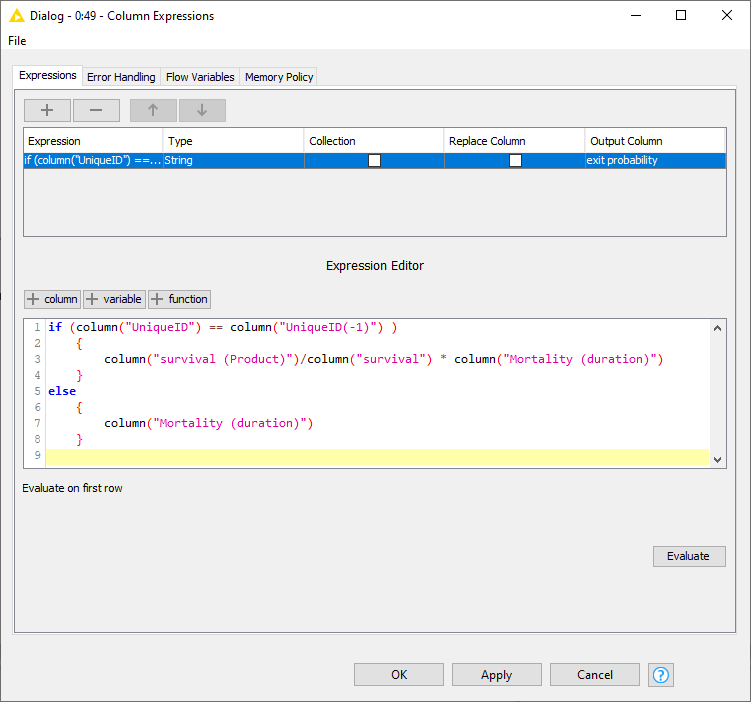
The formula you use in column H compares the value in the current row of the UniqueID column with the the value in the previous row. When I see this, I automatically think “Lag Column” in KNIME.
Finally, there’s an IF…THEN…ELSE comparison combined with a calculation. When I see this, I think “Column Expressions”. We compare the value in the lag column with the original column, if it matches we calculate the product of the survival cumulative product and Mortality columns. If not, we simply return the value from the Mortality column.
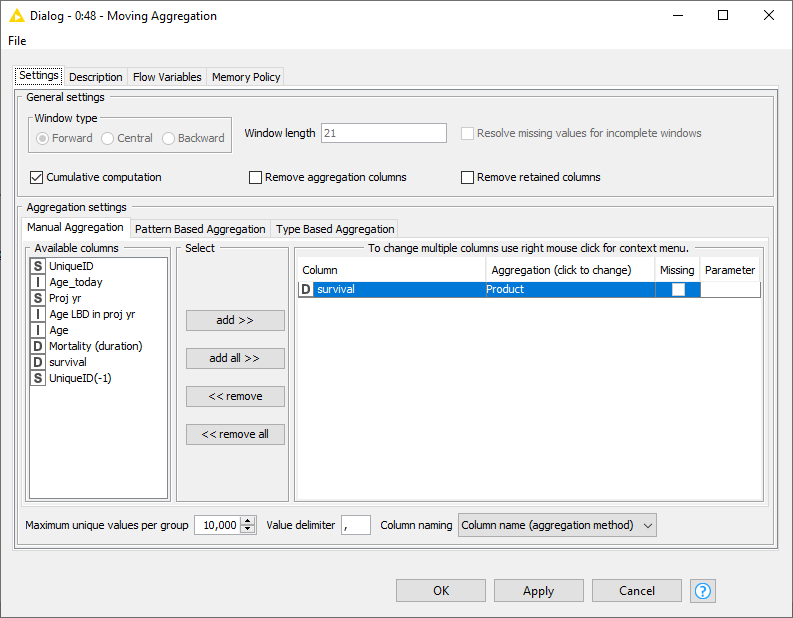
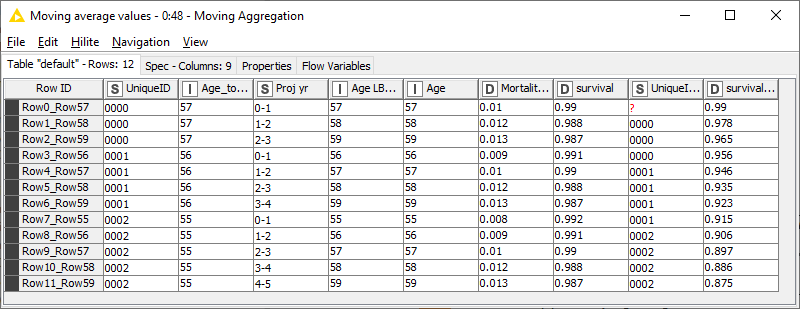
Note that the moving aggregation node calculates the cumulative product of the survival column INCLUDING the current row, which is not what we want. Therefore I divide that value by the value in the current row to get rid of that contribution.
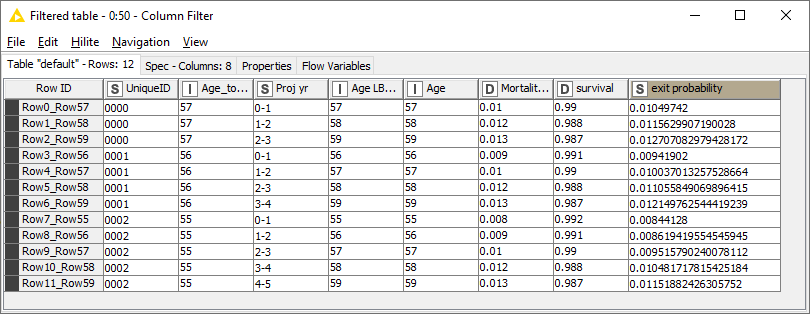
The intermediate columns can be filtered out to give the final result:
Hi guys, many thanks! Your responses are really helpful, and this will work for my case.
Just responding to the questions raised by @Thyme, the survival rates should cumulate for each unique ID and then reset for the next ID (I think @elsamuel 's solution has allowed for this). Also noted on the workflow settings and apologies for the inconvenience.