I am brining this up again as I still don’t understand how to join using streaming. Would it be possible to provide step by step example or a workflow to help me. Here is what I think needs to happen:
1-Install streaming node (not clear on how but I will do my due diligence here)
2-Set it up with the connector (I think I understand how to do this)
3-Pass the results from the streaming node to join for both sources (I think I understand how to do this)
4-Save the resulting table (which will still be pretty large, not sure if it needs to be saved on disk or I can view the results using DB Reader)
The two tables are on the same database. The join is based on key which exists in both table. What I would like to do is simple, connect the two tables so I can append information from one to the other.
The data sets are pretty large in both tables. One has about 5M rows and the other one has about 7M rows.
Some additional context: I will need to perform few additional joins based on the results from the first join to pick all the information required for an analysis.
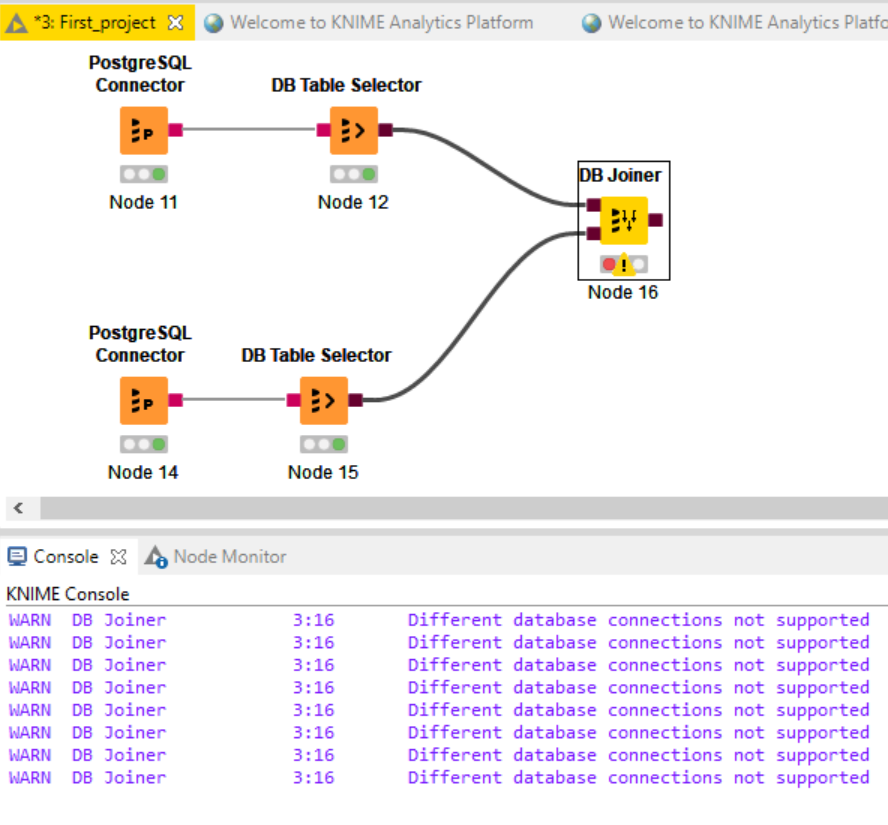
Question is what does that mean. If you can access them both by the same DB connector you might just use the DB Joiner – KNIME Community Hub node which in effect will create a SQL view. You can combine several DB (database) nodes so that the operation will be done on the database.
I do not think that a join using streaming is possible since the machine would not know which other possible values would be there. But that might depend on your actual data and what kind of databases we are talking about. Performance might also be influenced by things like indices (if they are being used).
In general it most often does make sense to do the larger database tasks on the DB. With big data operations my experience is that sometimes it can make sense to use temporary tables and do more complex operations in steps - while other databases (think Oracle) might have the option to optimise (nested) queries by themselves.
I think you might have to provide us with some more informations and maybe also talk to someone in or organisation who would know about performance tweaking in your database system.
If 5 or 7 million lines are large very much depends on the nature of the data just considering the number of lines a strong machine might be able to do that with a KNIME installation - depending on the complexity of the join.
Another thing to think about might be to do it in chunks and store the intermediate results (on a local machine Parquet would be a format that would be able to easily append intermediate results - also on a big data system). That again very much depends on the scenario.