Since I am required to collect and correctly classify some KPIS on a monthly basis, I need support automating this process using machine learning.
Every month I receive an excel file containing a plenty of rows. Each row corresponds to an order placed by a customer. The columns, such as invoice description, order description and others, instead contain descriptive textual information related to each order. This information is currently read in order to fill in the last column, where I manually categorize each order to the product/service root to which the order belongs. This last task must be done accurately, given that even a single keyword in a single column among all can allow to correctly classify the root of each order.
I want to develop a machine learning model that automatically fills the classification column on the new excel files I will receive along the next months.
I hypothesized that he could learn to do it by identifying patterns and correlations between the classifications and keywords made in the previous files.
Briefly, I would like him to follow the same reasoning that I followed in classifying each order.
I kindly ask if anyone can advise me which is the best approach, the best ML method and which nodes are needed to achieve this goal.
Hi if I understood correclty couldn’t you just aggregate the columns and then map them based on whether the relevant key word(s) are in the text? Assumption would be you already are able to map all keywords to the relevant outcome
br
e.g rule engine node, rule engine dictionary or similar
br
I thought about this, but I’ve been asked to proceed using ML. Bringing you an example among the categories to fill in the last column I have “ICT” and “Security”. In a specific order within the column order description I could have the word hw/hardware that could mislead the algorithm (but even a human) that ICT is the proper category, but then in the colum Invoice description I find “antivirus subscription fee” or even the name of a specific security software. In that case doing it manually I would be sure “Security” is the correct service root.
That’s the reason why I have to train a model which performs the same text analysis I would, understanding why I chose Security instead of ICT, since in the example I brought a keyword match would give a correct outcome both in ICT and Security.
Still thanks for your help and for any further suggestion
I have always done this kind of thing by building up a collection of complex rules to be applied to future data. You are trying to do it the other way around… Essentially, you want to change the data manually and and then have a ML decipher why you made that change and then apply it to future changes?
I am no expert, but seems like a pretty massive ML challenge even with a crazy amount of data containing multiple instances every possible scenario.
I hope that I am wrong, because I definitely want this as well!
Yep that’s the core! I want the model to “think as I would”, even making my (human) errors, by filling the blank “root category” column that so far has been filled manually, row by row.
Luckily I have a lot of similar datasets I could train it with and I’m sure there are a lot of potential patterns. Is not so far from what I actually do: I check every word until I find the match, but I do it critically. I need the model to emulate my critical analysis, not failing with 2 potential correct keywords. Anyways, I don’t need it to be perfect.
Which nodes could be involved to reach a similar goal?
Here is a forum post that has a workflow and detailed explanation of text processing and classification. I haven’t had time to dive in myself yet, but it looks intriguing.
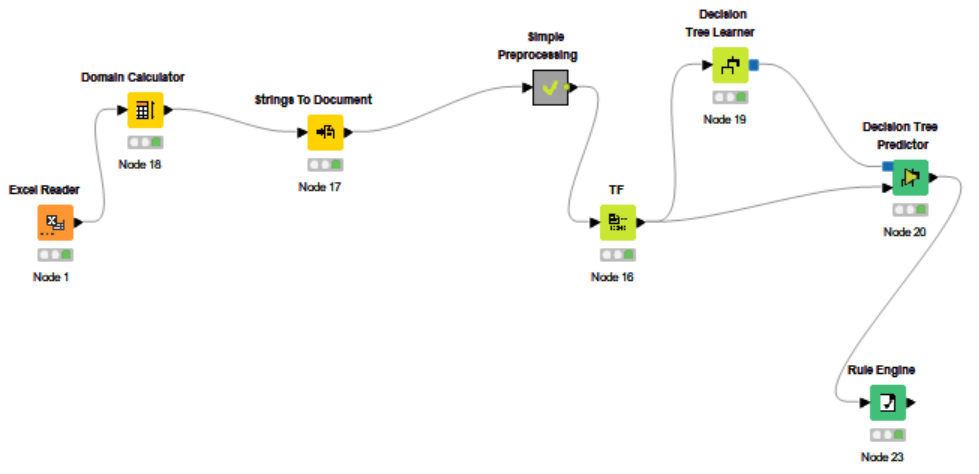
Thank you for supporting me, and I’m sorry for my late reply. I had to put this project aside for a while. I took inspiration from the post you shared with me to design my workflow, and this is the outcome:
The first picture shows all the nodes I’ve included in the workflow, while the second one focuses on the sub-nodes contained within the “Simple Pre-Processing” main node. So far, everything seems to be working well except for the Excel writing part.
To be more specific, I’m trying to set a rule that appends the new classification column in a new “Orders” Excel file that does not already have it. The column should be added according to what the decision tree nodes learned from the input Excel file with the classification column filled.
For now, it is not necessary for it to be perfect, it would be sufficient to see the algorithm “attempt” to complete the classification (by adding the related column), even if it makes mistakes. At the moment, I am not sure how to set up this rule in the workflow, and it is not clear to me whether it is necessary to close the workflow in the pic with the creation of a model to be implemented later in a new model as input for an Excel writer, or whether it is possible to add the Excel writer to this workflow.
It is hard to tell input / output format / calculation goals from this image… Can you share the workflow without confidential info? Writing the predictions to the table (or appending prediction columns) to an excel file within the workflow shouldn’t be an issue. How you go about it will depend on what your output format / goal is with the data of the excel file.