It’s a rare thing for me to ask a question here but I cannot seem to find an answer, I did check the resource which was knocked up in Google Sheets around tools to nodes but this one is not on the Sheet.
The Make Group tool creates groups from associations identified in 2 specified columns.
Below is taken from the tool example -
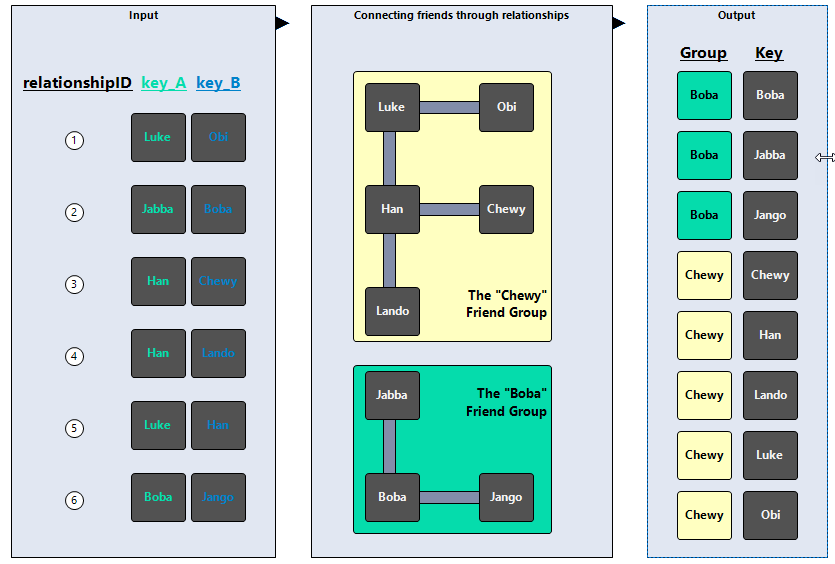
For the sake of this sample, let’s call this the Make Friend Group tool. The idea of this follows the gregarious logic that if Sally and Laura are friends, and Sally and Jess are friends, then Sally, Jess, and Laura are all part of the same friend group. And if Jess and Dan are friends, then Dan is part of that friend group as well.
The 2 keys are interchangeable, and the order is irrelevant – the important thing is the relationships that connect 2 things (friends) together. Using those relationships, this tool is able to put everything together and tell you who is in the same friend group. The group will be named after one of the members of the group almost arbitrarily, taking the first value from a sorted list of all the members in the group.
Let’s take a look at another set of relationships in the visual representation below.
Wishing I could open my old Alteryx designer now and take a look, but I’m no longer at a company with Alteryx and being a mere mortal I can’t afford my own copy…
So… when its working out groups, how many levels down does it go? In your example, Chewy knows Han, and Han knows Luke, and Luke knows Obi, so it determines that Chewy knows Obi.
If we also had that Obi knew Vader, and Vader knew Darth Maul (ok I’m stretching the definition of “friendship” a little here ), would it also say that Chewy knew both Vader and Darth Maul?
Hello Matt_D,
I have created a workflow that uses your mentioned example data and the KNIME Network Mining extension to extract the group of related nodes. You can find it here:
@tobias.koetter That’s a great example of how the network nodes can be made to work! Hope this is OK, but I’ve taken your flow (now that you’ve done all the hard work, ) and modified it a little. I’ve credited you and cited your original flow in this one.
I removed all data from the input file that wasn’t “known” so effectively reduced it to just a list of relationships without strength or colour grouping information (i.e. “no prior knowledge”). I also added a few more relationships to see what would happen.
I also wanted to see what could be done if we didn’t have any prior knowledge of "starting points (Object Ids) predefined in the SubGraph Extractor.
So I as I had taken colour coding out of the Table Creator I’ve removed the colour and visual output nodes from the flow.
The SubGraph Extractor of course needed a starting point for the subgraphs to find, so I produced a set of all the names supplied in the Data and told it to find all of the subgraphs.
At the other end of your part of the flow, that of course now meant that we had a subgraph for everybody, and we want just the distinct set with an arbitrary “origin”, so I then added a flow on the last stage to condense this down into just the distinct set of subgraphs, with each origin chosen arbitrarily from the sets.
My additional nodes for doing the simple work greatly outnumber yours that are doing a much tougher job. There may be other nodes that could have been used to effectively do the job that I’ve done in small steps, but hopefully they make sense. I’m always happy to discover that the work of 5 of my nodes can be handled by 1, but on the other hand the steps provide documentation of what they are doing!
[edit: I had previously included a set of nodes to find all names to pass these to SubGraph extractor but I now realise the SubGraph Extractor can be configured to use “use all objects”. I didn’t spot that before, so I’ve removed a whole bunch of nodes that I’d added to do just that!
No doubt next I’ll find there’s another option that can replace the nodes I added at the end but I like finding better ways to do things, and the best way to learn is to experiment! ]
lol… I just did… If I switch off “allow overlapping graphs” in SubGraph Extractor, I don’t need to reduce the set of graphs at the end so my final my other nodes are indeed also redundant.
“Sometimes I realise that my only purpose in life is to serve as a warning to others”…
Hi takbb,
this is awesome work. It is really not necessary to cite my workflow in yours I’m always happy when someone is using KNIME to great such awesome workflow and if they include some network mining even better
Happy KNIMEing
Tobias
Incredible job chaps but this still isn’t quite working as I want it, I know I emphasised on the friends element but I’m actually using this as a parent / child on a folder relationship, the data attached. id - parentid.xlsx (12.5 KB)
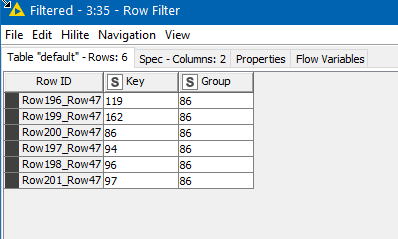
Running this through the workflow doesn’t produce the same results (correct) as Alteryx, id 86 is a good example -
I don’t know if you have found a solution already.I hadn’t seen you post as I wasn’t following the conversation.
Your new requirement has a couple of differences to your original one. Firstly, your input data can have blank relationships, which presumably means a given ID doesn’t have a parent. In this case I’m guessing we need to fix the data so that the ID is its own parent.
Secondly, the choice of group name appears to no longer be arbitrary, as you know have some “prior knowledge” of parents. That is what I am guessing from your 86 vs 119 example.
In an attempt to address these two issues, I have taken @tobias.koetter’s workflow and based it now from a copy of your example excel. It renames the columns to make them work with the original workflow, and changes the data types to String which seems to be needed too. It also populates parent_id with id if it is missing.
The SubGraph Extractor is reconfigured to produce subgraphs for ALL objects, and to allow overlapping subgraphs.
At the far end, the columns are renamed to Group and Key, but additionally the original data set is used to identify the parents. A parent is any ID that appears in the parent_id column following the fix of missing parents. By joining the full set of subgraphs with this list, you are returned those subgraphs for the actual parents.
You can see the full set at the Column Resorter node just before the end of the workflow, or if you enter a String in the String Input node “Choose a Group” the (default is 86, for convenience) , the final result is the filter for just that Group.
There may be other better ways to do this. I’m new to these network nodes, but I hope that helps.
Hi @Matt_D,
you can also make the edges directed by selecting the Create directed edges option in the Object Inserter node. I have adapted the workflow to demonstrate this. This time Boba is no longer connected to Jabba because of the direct edges that indicates that Jabba knows Boba but not vice versa. You can find the updated version here were I have only changed this setting:


 ), would it also say that Chewy knew both Vader and Darth Maul?
), would it also say that Chewy knew both Vader and Darth Maul? but I like finding better ways to do things, and the best way to learn is to experiment! ]
but I like finding better ways to do things, and the best way to learn is to experiment! ]
 I’m always happy when someone is using KNIME to great such awesome workflow and if they include some network mining even better
I’m always happy when someone is using KNIME to great such awesome workflow and if they include some network mining even better