I hope that you can help me with the following problem.
I have a table which lists recordings of technical data for motorbikes (e.g. speed, total cumulated distance, light on/off) over time.
These recordings represent trips, whereby a trip is defined as the engine was turned on and then off. There are 2 kind of trips. Trip A: The motorbike was actually driven (you have speed & distance recordings). Trip B: The motorbike engine was just turned on and off, without driving the bike.
I would like to do the following:
Identify all trips in this list of recordings (e.g. by attaching labels in a new column)
Calculated the time of each trip (time between turning engine on & off). If Trip B: Also calculate the distance it was driven
Identify the trips where the light was turned on and calculate the time for how long the light was on for each trip (Light on = 1; Light off = 0)
The two events (engine on/off) are defined as follows:
Engine On:
Counter: 1
Status: Empty
Total cumulated distance: 0
While the engine is on, the Counter will keep going up.
If the bike is actually driven (Trip A), the total cumulated distance will also increase.
If the bike was not driven (Trip B), the total cumulated distance should stay the same.
After turning off the engine, the Counter goes down to 1, Status switches to Empty and the distance to 0.
The next trip starts again with:
Counter: 1
Status: Empty
Total cumulated distance: 0
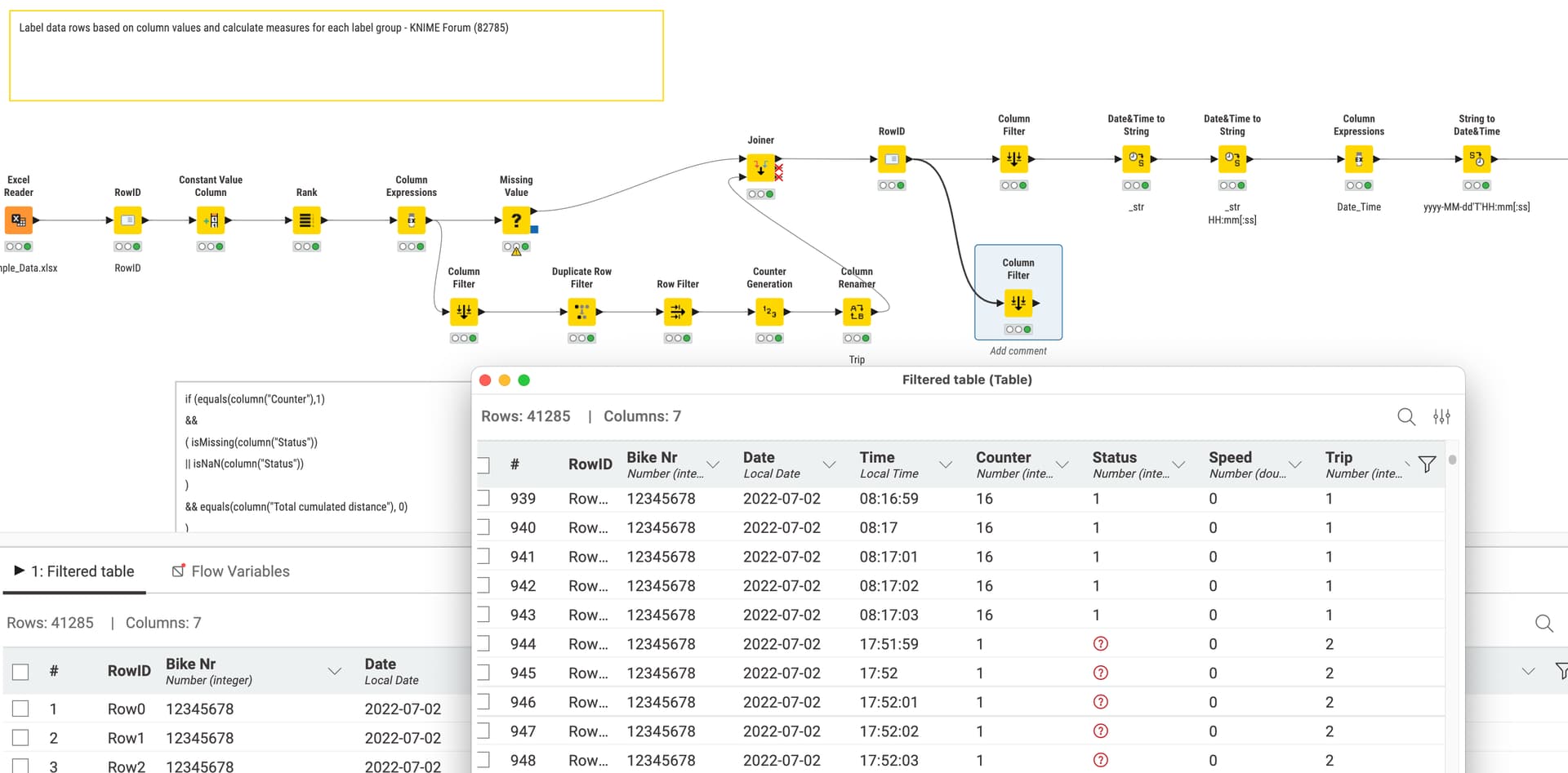
I was thinking about using a Rule Engine to attach labels in a new column (Trip 1, 2, 3, …). And then group over these label groups (trips) to calculate the driven distance and the time the light was on, but I cannot get it to work. Maybe this is a tasks for loops, but unfortunately I have never worked with them before.
I took a look at your data and am pretty confused. You said:
“While the engine is on, the Counter will keep going up.
If the bike is actually driven (Trip A), the total cumulated distance will also increase.
If the bike was not driven (Trip B), the total cumulated distance should stay the same.”
I can’t understand the pattern for incrementing the counter. Also the cumulated distances don’t seem to change with each time increment. What am I missing?
@rfeigel thanks for taking the time and for your reply. Much appreciated
Unfortunately, I don’t know myself why the signals are recorded like this and what circumstances trigger the Counter to increase. That’s something only our technicians know. I just know that if there is a pattern like this:
Counter drops to 1, Status switches to Empty and Distance drops to 0, it means the beginning of a new trip and signals that the previous trip was finished:
Would it be possible to write a rule or create a loop that looks for this pattern and based on this labels the trips?
Regarding the distance:
The distance doesn’t necessarily change with each timestamp recording. That is the case if the bike was not moved (the engine is just running, without driving) or the bike was driven less than 1km. But I just checked the data and for the 3 trips that I manually labelled in the sheet “Table_Adjusted”, the distance increases between the beginning and end of trip, which is exactly the expected behavior. Hope I got your question right.
I was thinking if this problem could be solved with a WHILE-Loop, e.g.:
i = 1
WHILE Current_Row_Counter <= Next_Row_Counter & Current_Row_Distance <= Next_Row_Distance
[Current_Row, Label_Column] = "Trip " & i
END WHILE
i = i + 1
But I don’t think the WHILE code is correct yet and I also don’t know how to realize a WHILE loop in Knime.
@Er3n I think you can identify blocks of data like your trips like this:
You might define the start of a trip by using rules employing a lag function where the previous row is not null and the current one is and the previous counter is different.
You might have to look out for edge cases where there are very short entries.
I would strongly suggest that you talk to your techs and get a complete understanding of the data. Its always a little dangerous to model something without a good understanding of the data.
if (equals(column("Counter"),1)
&& // && means AND
( isMissing(column("Status"))
|| isNaN(column("Status")) // || means OR
)
&& equals(column("Total cumulated distance"), 0)
)
{column("rank")}
else {toNull("")}
@mlauber71 Thanks so much for your help! Your workflow worked excellently
While going through your workflow some questions came up. Would appreciate if you could enlighten me:
It seems you used 2 methods to create a rank: 1.) with Constant Value Node + Rank Node 2.) just with the Counter Generate Node. Is there a reason why you applied different methods?
Why did you use {} in the last two lines of your code for the Column Expression?
{column("rank")}
else {toNull(“”)}
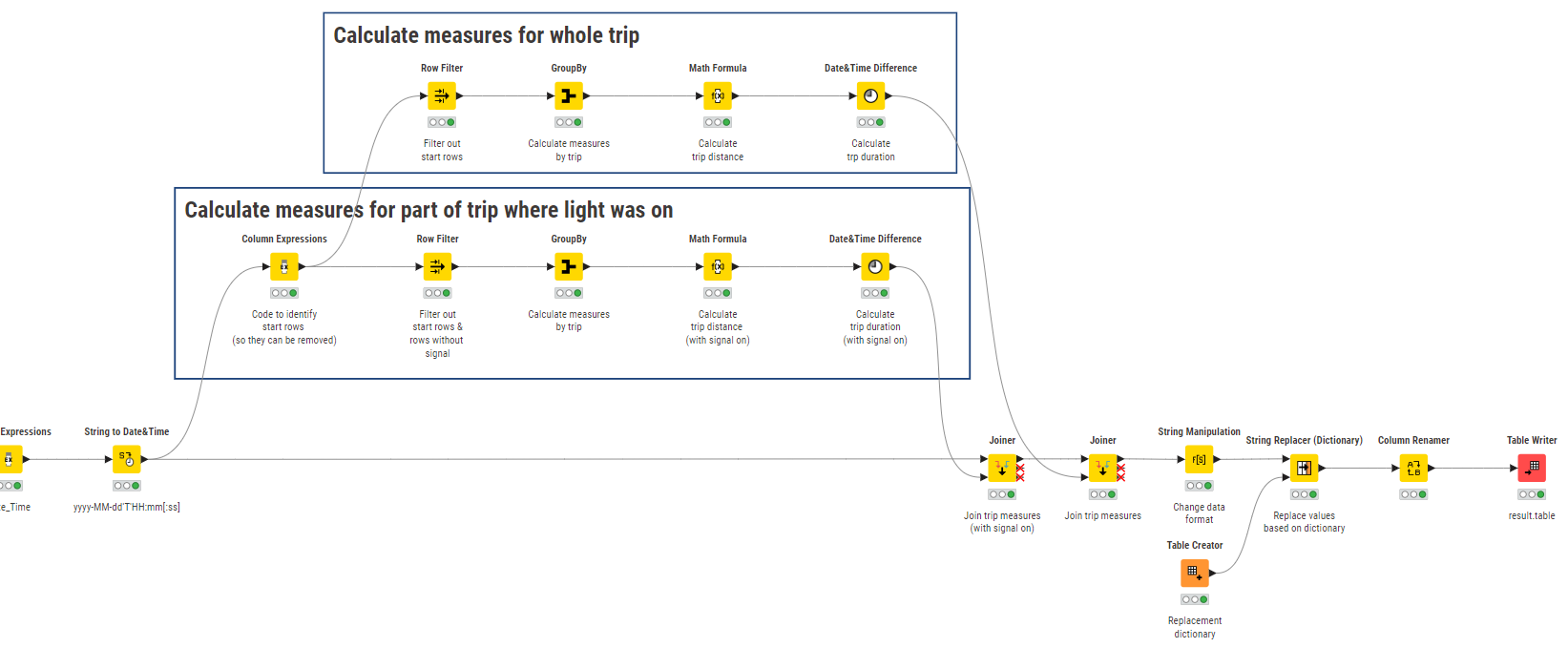
Workflow Update:
I added a few parts to your workflow to calculate the distance and duration for each trip, as well as the periods of time that the light was one within each trip:
I use a very easy way to calculate the measures (identify minimum and maximum and then calculate the difference). The assumption to this logic is, that within each trip the light was only once turned on and turned off. If within one trip the light was turned on & off multiple times, this logic would be wrong.
I’m currently thinking about a way to solve this. Maybe I could adjust your Column Expression code to identify periods of time where light was on within a trip (basically trips within trips).
This slightly strange construct with the rank allows for a long variable to have greater numbers instead of an integer one in case the list is longer. Maybe there is a more elegant way.
This is the syntax where the condition is in brackets and the setting of the value in the other ones. More on this here:
Concerning the trips within the trips you might have to try and use a loop or another construct to identify parts where the light was on. I would have to think about some options.