I have a problem that I am finding quite difficult and I am still relatively new to KNIME. I am trying to calculate the closest important day to every other day in a group (country in this example. Each country can have one or many important days (or none). I am finding comparison between rows that are not immediately above / below each other to be complex.
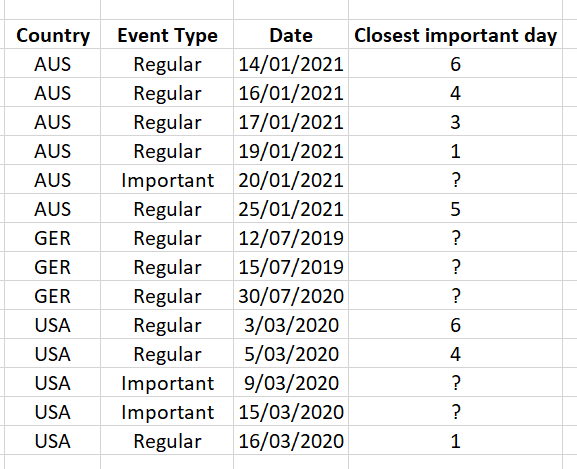
In my example: for AUS, there is one important day (20/01/2021), the “Closest important day” column needs to be generated, expressing the (absolute value) number of days each regular day is different from that important day. GER has no important day, so the “Closest important day” column remains “?”. USA has two important days, which means each regular day that falls under this country must have its “Closest important day” column calculated with respect to the closest one to it.
May be this other related post could help you to find a solution to your question:
In the above post, a workflow shows how to convert the dates into absolute integer numbers which allows to easily compare dates and know which ones are the closest.
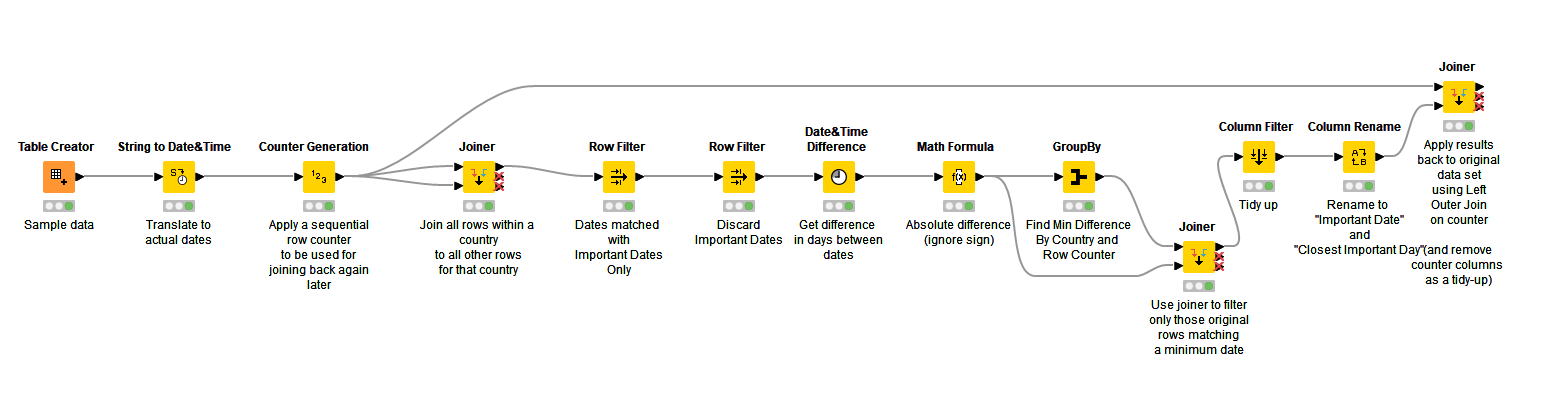
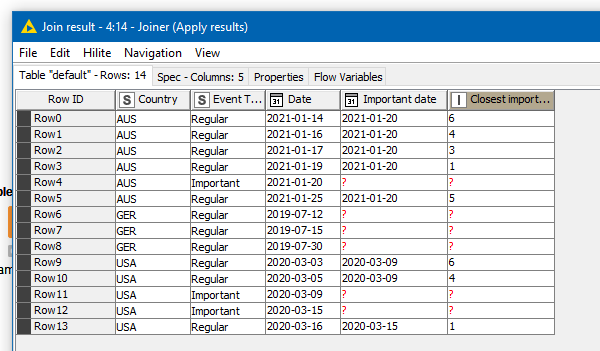
Hi @hhaw, depending on how much data (and memory) you have, you can also achieve this without a loop by joining all rows to all other rows for a given country, and then performing the required date comparisons.
The attached workflow gives an example of how this might work
Hi Brian,
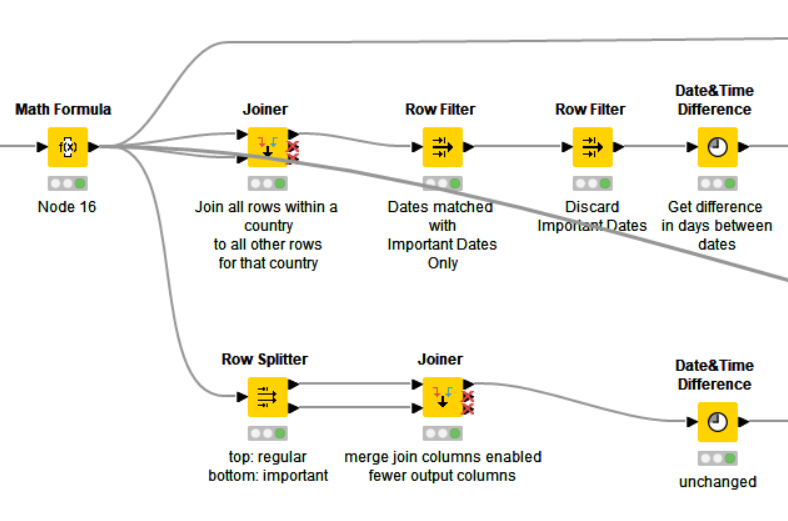
sorry to desecrate your workflow, but I had to Node Golf this. I had an idea that could reduce the number of nodes by one (1):
Using a Row Splitter before the first Joiner get’s rid of the “Grouped Cross Join” and renders the 2 Row Filters afterwards obsolete.
Could be relevant for hhaw since this eats less RAM.
Hi @Thyme, please don’t apologise for being constructive, but thanks for the thoughts. Great idea. That’s what this forum is about… building on each other’s ideas.
I often come back to something later on and think “why didn’t I just…”
Yes, standing on the shoulders of giants. Or a big enough pile of dwarfs, works either way.
It happened in the past that I unintentionally hurt people because I didn’t pay enough attention to how I come across. No big deal on my side, just trying to make sure it doesn’t happen again. But somethymes I overshot the target
 Great idea. That’s what this forum is about… building on each other’s ideas.
Great idea. That’s what this forum is about… building on each other’s ideas.
