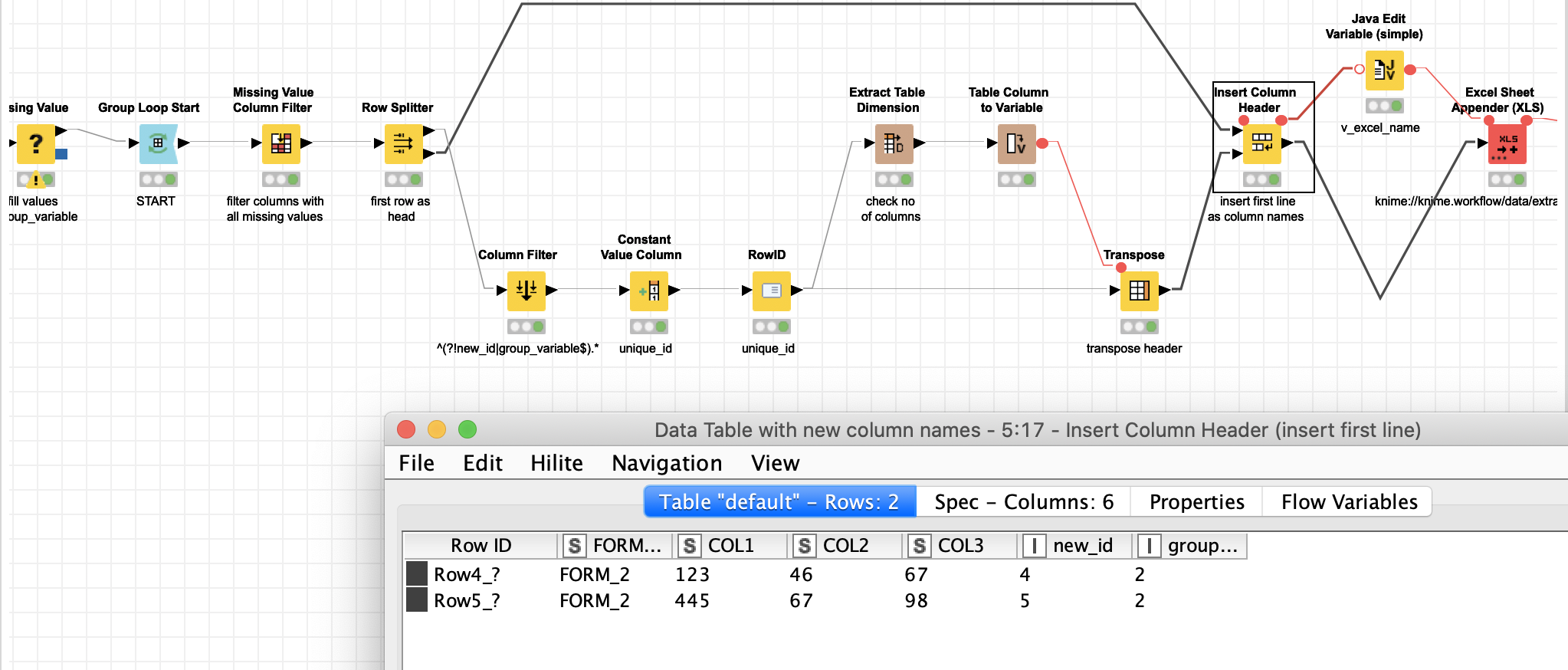
OK it was slightly more complicated than I initially thought. But I hope it does work now:
- give each line a unique ID to identify them later
- identify the ‘heads’ of the tables (“FORMNAME”) like you already did
- use moving aggregate to give the heads unique numbers
- bring these numbers back to the data
- fill the intermediate (empty) cells with the head’s number
- use a group loop on the blocks identified by the head numbers
- extract the first line as column names
- make sure empty columns that would just contain missing values are excluded (you could set a threshold)
- insert the column names
- create a new file name
- store the new files on disk
- be done